Actively Selecting Annotations Among Objects and Attributes
Adriana Kovashka, Sudheendra Vijayanarasimhan, and Kristen Grauman
Abstract
We present an active learning approach to choose image
annotation requests among both object category labels
and the objects' attribute labels. The goal is to solicit those
labels that will best use human effort when training a multiclass
object recognition model. In contrast to previous
work in active visual category learning, our approach directly
exploits the dependencies between human-nameable
visual attributes and the objects they describe, shifting its
requests in either label space accordingly. We adopt a discriminative
latent model that captures object-attribute and
attribute-attribute relationships, and then define a suitable
entropy reduction selection criterion to predict the influence
a new label might have throughout those connections. On
three challenging datasets, we demonstrate that the method
can more successfully accelerate object learning relative to
both passive learning and traditional active learning approaches.
Introduction
Labeled data is critical for object category learning, but it is expensive. Active learning can mitigate the cost, but existing methods restrict requests to "What object is it?" or "Where is it in the image?" They also consider object models independently.
In contrast, we propose to minimize the annotation effort by exploiting shared attributes among objects and the relationships between them in active learning. Attributes are properties like "wooden" or "furry" that are shared among object categories. This property makes them inherently appropriate for active learning. We expect that obtaining an attribute label can potentially have a greater impact than obtaining any single object label. Furthermore, some attributes often cooccur, which implies that only a partial set of attributes needs to be labeled.
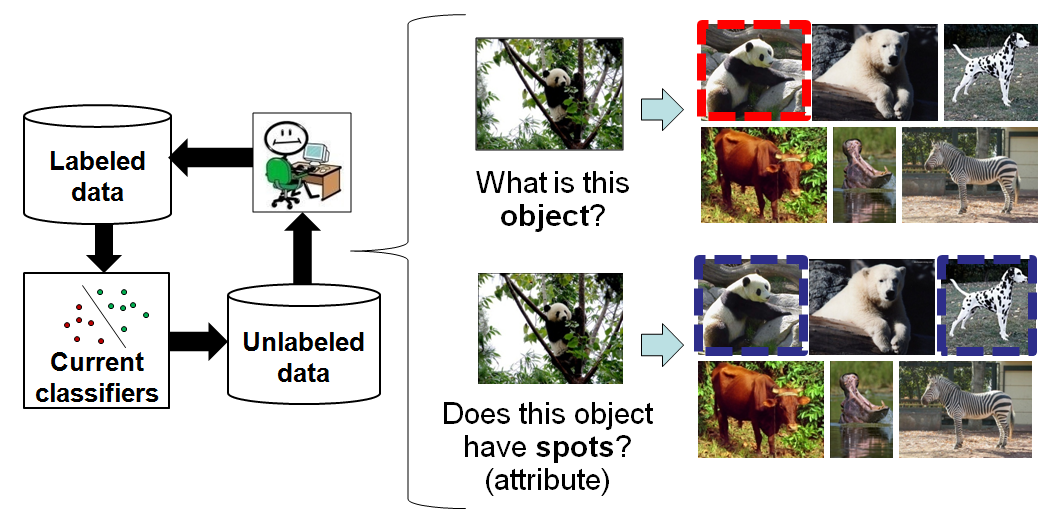
Approach
Object-Attribute Model
For a classifier, we adopt a discriminative latent SVM model capturing all object-attribute interactions from Wang and Mori, ECCV 2010 (see paper for reference).
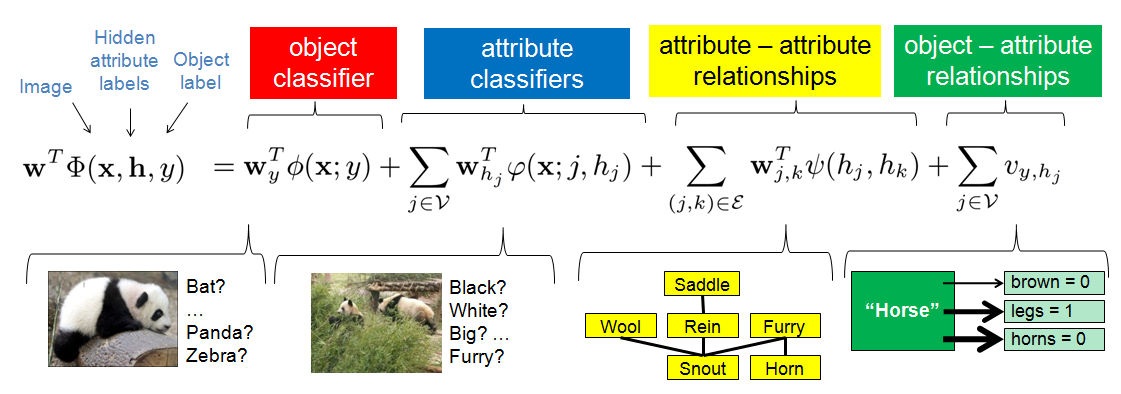
- Object classifier: P(label(x) = y), multi-class SVM, ignoring attributes
- Attribute classifiers: P(label(j) = hj), binary SVMs, ignoring objects
- Attribute-attribute relations: vector of length 2x2, 1 in one entry denotes that both/none/first/second attributes are present, models relations of highly correlated attributes only; (V, E) = graph of attribute-attribute relationships
- Object-attribute relations: learned parameter, reflects frequency of object being y and jth attribute being hj
At training time, we use a small initial set of training images fully annotated with their object label and all attributes labels. We use a non-convex cutting plane method by Do and Artieres for training (see paper for reference).
At test time, we predict the object label as:
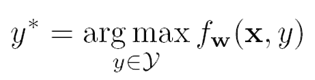
Note that the features depend on the latent attributes:
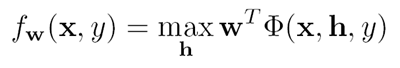
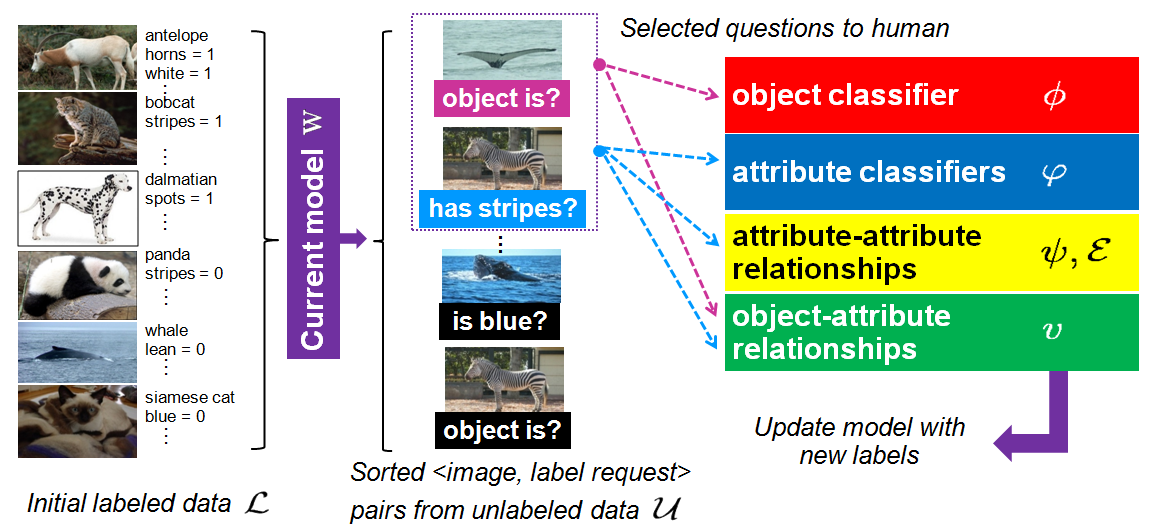
Active Learning with Objects and Attributes
We interleave actively selected questions for object and attribute labels. We use the object-attribute model and an entropy-based selection function to predict what questions to ask, and when to ask them. We pick the n most informative (image, label) pairs, where label is an object label or label for some attribute.
Entropy-Based Selection Function
Our entropy-based selection function seeks to maximize the expected object label entropy reduction. We measure object class entropy on the labeled and unlabeled image sets:
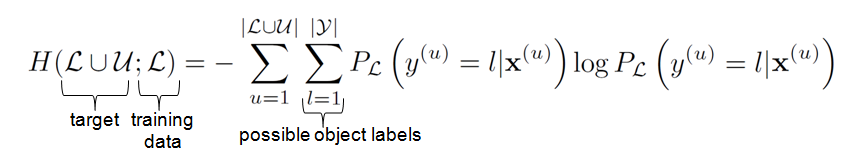
We seek maximal entropy reduction, which is equivalent to minimum entropy after the label addition:
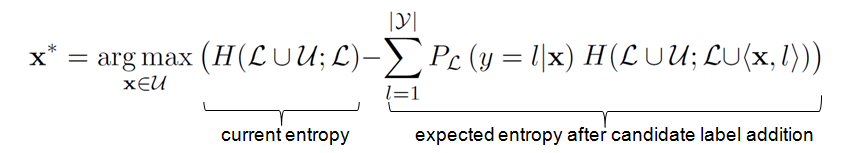
The expected entropy scores for object label and attribute label additions can be expressed as follows. Note that these two formulations are comparable since they both measure entropy of the object class.
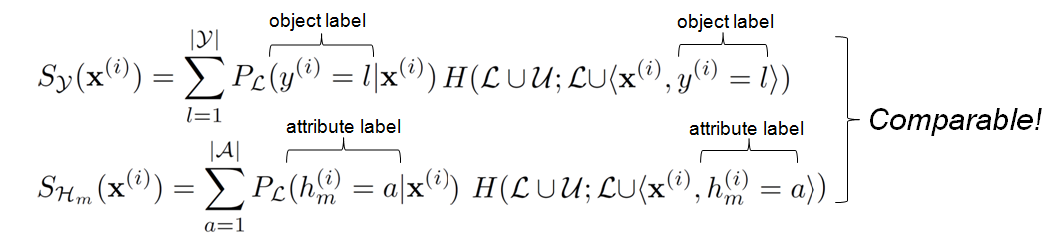
Then the best (image, label) choice can be made as:
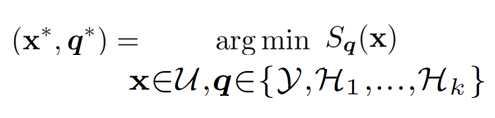
where x ranges over unlabeled images and q ranges over possible label types.
A key point to note is that by predicting entropy change over all data, selection accounts for the impact of all desired interactions.
Inferring Missing Attribute Labels
Note that for partially labeled data, we infer the missing attribute labels. This enables faster learning since we avoid waiting for a full labeling to see the effects of a new label.
Experiments
Datasets

Baselines
We compare our method to two baselines: a passive baseline (random) which randomly selects both object and attribute labels, and a single-level active baseline (active-obj) which actively selects object labels only (while starting from both object and attribute labels). In one figure we also show the performance of an upper baseline (optimal selection) which is like our method but "peeks" at the true labels of the unlabeled images instead of computing expected entropy.
Results
First we show learning curves, which demonstrate how quickly our method learns compared to the two baselines. Here we show confidence on a test set. Our proposed method builds accurate models with less total human effort, outperforming a traditional active approach that selects object labels only.

Next we show actual entropy reduction on the training and unlabeled sets, which demonstrates the quality of the selected queries.

Here are some sample (image, label) requests selected by our method (see paper for an explanation):

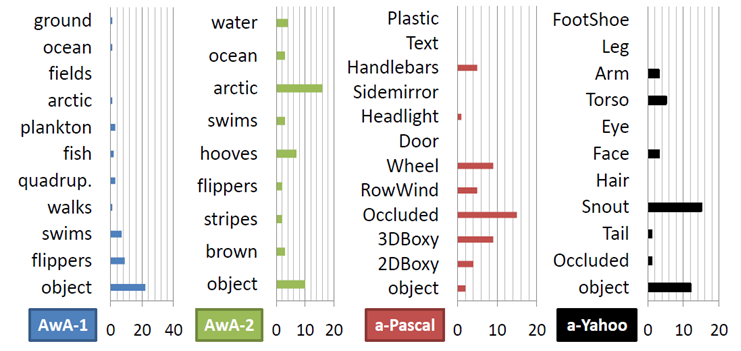
Here is the distribution of all requests. The large number of attribute requests indicates the impact of shared attributes on reducing uncertainty:
Conclusions
We introduce richer annotations beyond labels which are critical for active learning. Our method makes the most efficient use of annotator effort to train multi-class object models. We provide a natural means to enhance multi-class object category learning.
Publication
Actively Selecting Annotations Among Objects and Attributes. Adriana Kovashka, Sudheendra Vijayanarasimhan, and Kristen Grauman. Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, November 2011.
[pdf]
[poster]
[video]