Learning the Latent "Look": Unsupervised Discovery of a Style-Coherent Embedding from Fashion Images
We propose an unsupervised approach to learn a style-coherent representation. Our method leverages probabilistic polylingual topic models based on visual attributes to discover a set of latent style factors. Given a collection of unlabeled fashion images, our approach mines for the latent styles, then summarizes outfits by how they mix those styles. Our approach can organize galleries of outfits by style without requiring any style labels. Experiments on over 100K images demonstrate its promise for retrieving, mixing, and summarizing fashion images by their style.
Approach
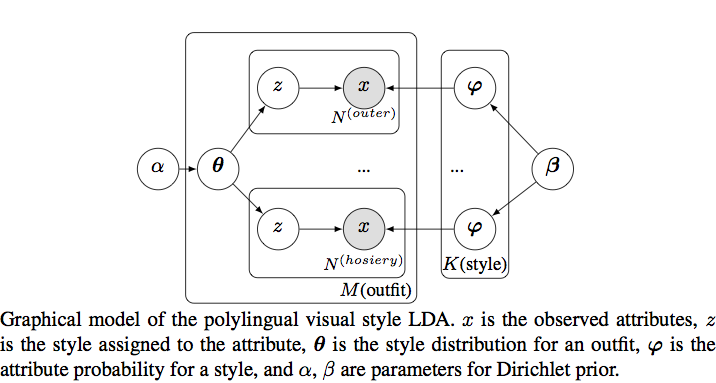
We learn a style-coherent embedding using a polylingual topic model. The latent topics will be discovered from unlabeled full-body fashion images, meaning images of people wearing an entire outfit. The basic mapping from document topic models to our visual style topic models is as follows: an observed outfit is a "document", a predicted visual attribute (e.g., polka dotted, flowing, wool) is a "word", each body region(i.e. upper, lower, outer, hosiery) is a language, and each style is a discovered "topic".
Results
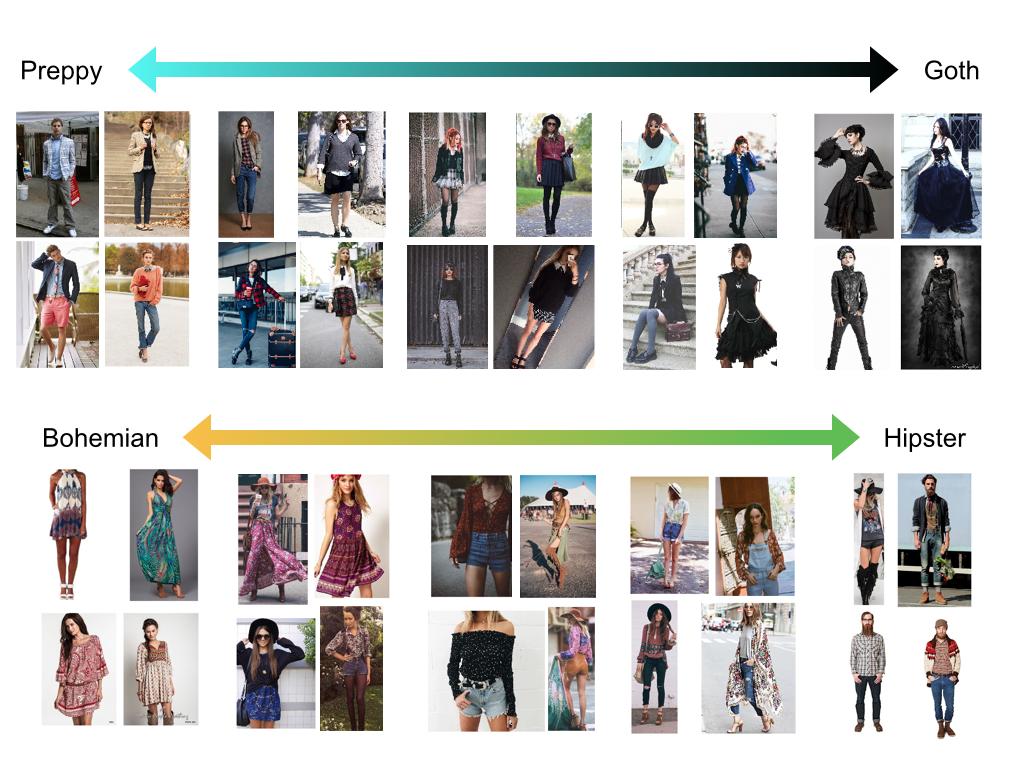
We evaluate our discovered styles and learnt style embedding in clustering and style retrieval experiments. See our paper for more details. Here we show qualitative results of traversing between styles, and summarizing users' albums at a glance.

Acknowledgement
This research is supported in part by NSF IIS-1065390 and a gift from Amazon.