|
|



Three important problems that need to be addressed while choosing informative image data to label for recognition, none of which are considered by traditional active learning approaches.
Sudheendra Vijayanarasimhan and Kristen Grauman
Department of Computer Sciences,
University of Texas at Austin
In the general case, visual category learning does not fit the mold of traditional active learning approaches, which primarily aim to reduce the number of labeled examples required to learn a classifier, and almost always assume a binary decision task. When trying to choose informative image data to label for recognition, there are three important distinctions we ought to take into account as shown in the following figure.
|
|
How do we actively learn in the presence of multi-label and multi-level annotations where each annotation requires different amounts of manual efforts?
In order to handle these issues, we propose an active learning framework where the expected informativeness of any candidate image annotation is weighed against the predicted cost of obtaining it.
![]() Multi-level annotations. To accomodate the multiple levels of granularity that may occur in provided image annotations, we pose the problem in the multiple-instance learning setting (MIL) as done in our previous work.
Multi-level annotations. To accomodate the multiple levels of granularity that may occur in provided image annotations, we pose the problem in the multiple-instance learning setting (MIL) as done in our previous work.
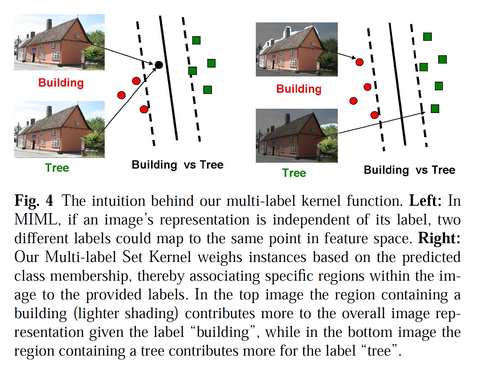
![]() Multi-label images. To deal with images containing multiple labels (objects) we devise a kernel-based classifier for multiple-instance, multi-label learning (MIML) and show how to extend our previous work on standard binary MIL setting to the more general MIML setting.
Multi-label images. To deal with images containing multiple labels (objects) we devise a kernel-based classifier for multiple-instance, multi-label learning (MIML) and show how to extend our previous work on standard binary MIL setting to the more general MIML setting.
 |
|
![]() Predicting manual effort. Humans (especially vision researchers) can easily glance at an image and roughly gauge the difficulty. Can we predict annotation costs directly from image features?
Predicting manual effort. Humans (especially vision researchers) can easily glance at an image and roughly gauge the difficulty. Can we predict annotation costs directly from image features?
 |
 |
Learning with data collected from anonymous users on the Web, we show that we can reliably learn to predict the amount of time required to annotate an image and that active selection gains actually improve when we account for the task's variable difficulty.
Putting it all together we consider the following three queries that an active learner can pose:
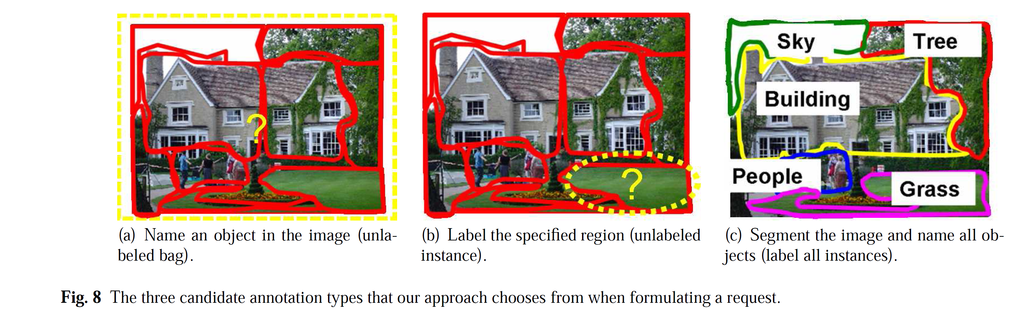
We measure the information content of a candidate annotation by computing the reduction in the risk of the dataset once we add the example along with the annotation to the training set and retrain the classifier.
We obtain the cost (manual effort) of an annotation using our cost-predictor trained on user annotations.
At each active iteration, we compute the ``net worth'' of each unlabeled example and its candidate annotations and choose the annotation that provides the best tradeoff and add it to the training set.
To validate our method we use the MSRC dataset, as it is a common benchmark for multi-class object segmentation. In the following we show some example selections by our approach to illustrate the main idea. We provide extensive quantitative results in our publication.


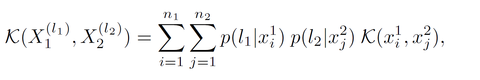 where
where