Abstract:
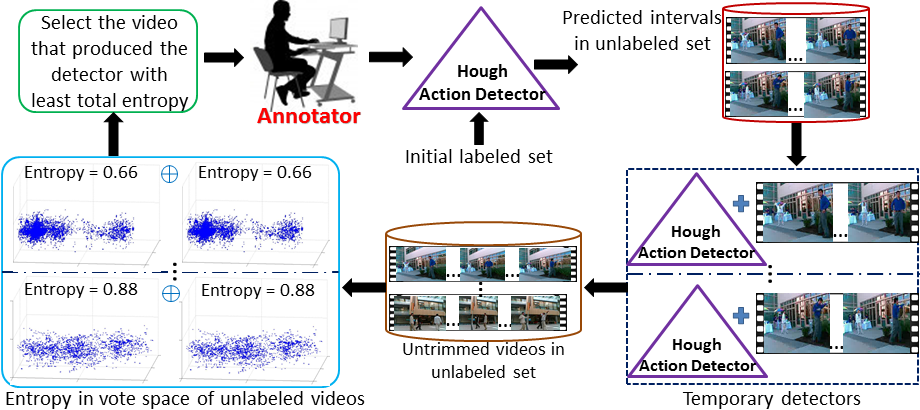
Method Overview:
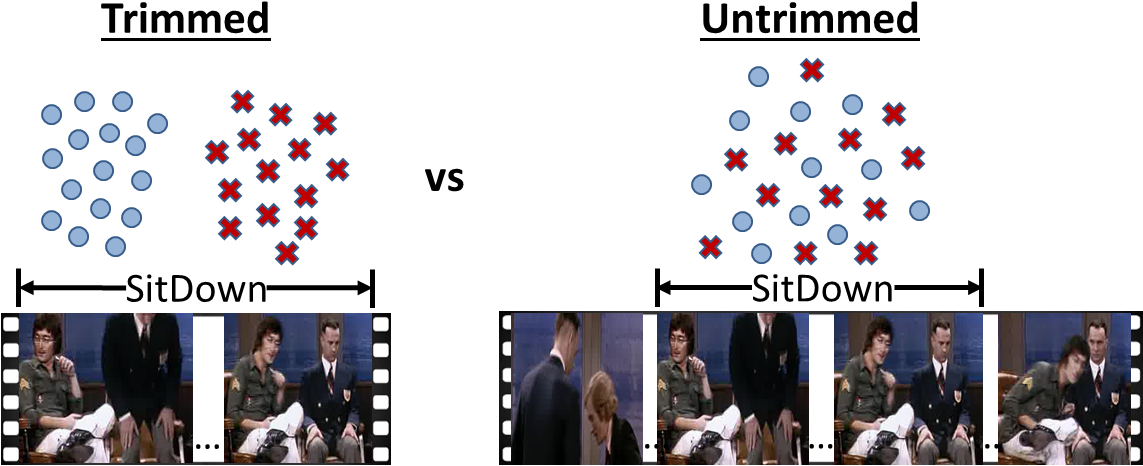
Our goal is to perform active learning of actions in untrimmed videos. To achieve this, we introduce a technique to measure the information content of an untrimmed video, rank all unlabeled videos based on these scores, and request annotations on the most valuable video.
The method works as follows. In order to predict the informativeness of an untrimmed video, we first use a Hough-based action detector to estimate the spatio-temporal extents in which an action of interest could occur. Whereas a naive approach would evaluate all possible spatio-temporal intervals, this step allows us to focus on a small subset of candidates per video. Next, we forecast how each of these predicted action intervals would influence the action detector, were we to get it labeled by a human. To this end, we develop a novel uncertainty metric computed based on entropy in the 3D vote space of a video. Importantly, rather than simply look for the single untrimmed video that has the highest uncertainty, we estimate how much each candidate video will reduce the total uncertainty across all videos. That is, the best video to get labeled is the one that, once used to augment the Hough detector, will more confidently localize actions in all unlabeled videos. We ask a human to annotate the most promising video, and use the results to update the detector. The whole process repeats for a specific number of rounds, or until the available manual annotation effort is exhausted.
Results:
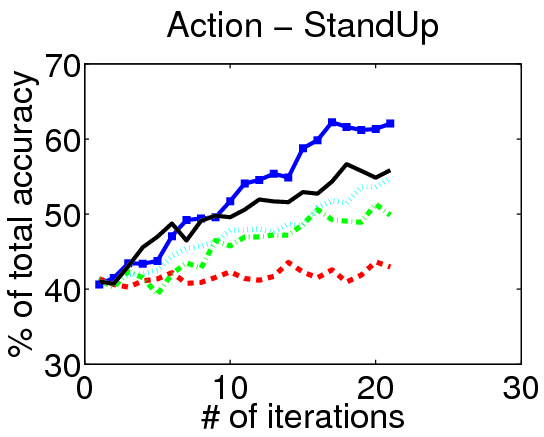
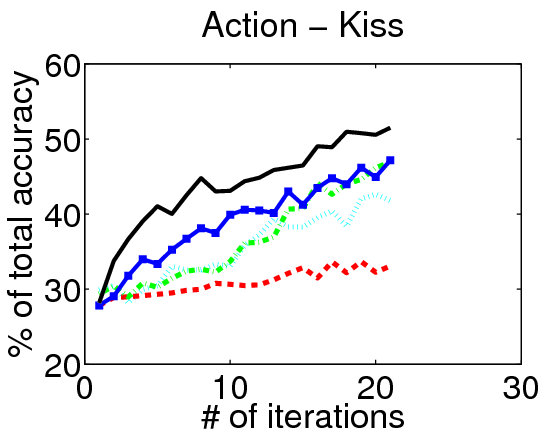
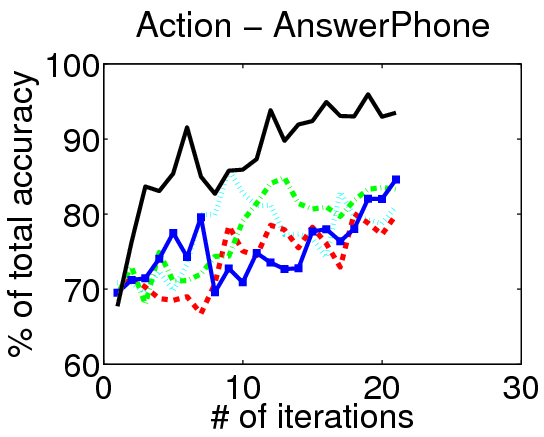
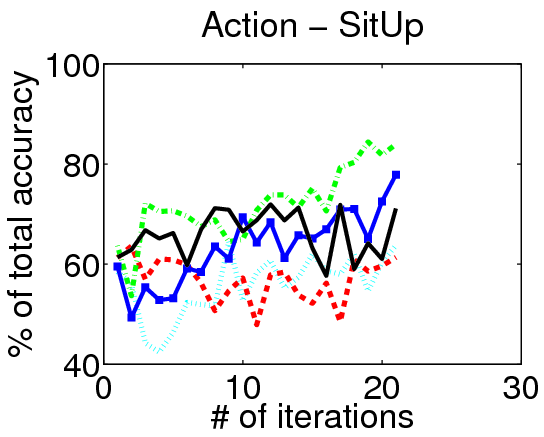
We evaluate our method on three action localization datasets - Hollywood, MSR Action 1 and UT Interaction. We examine detection accuracy as a function of the number of annotated videos, comparing our method to both passive and active alternatives. The results demonstrate that accounting for the untrimmed nature of unlabeled video data is critical.
Results on Hollywood:
![]()
|
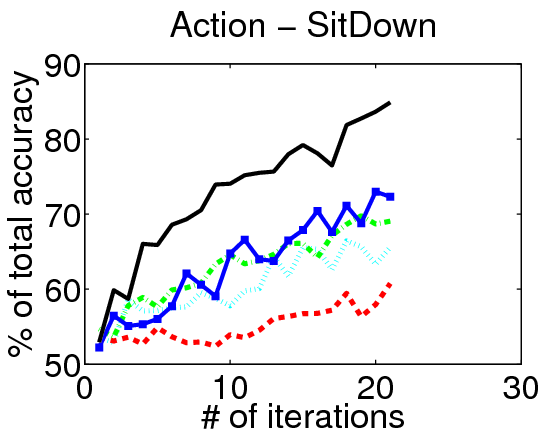
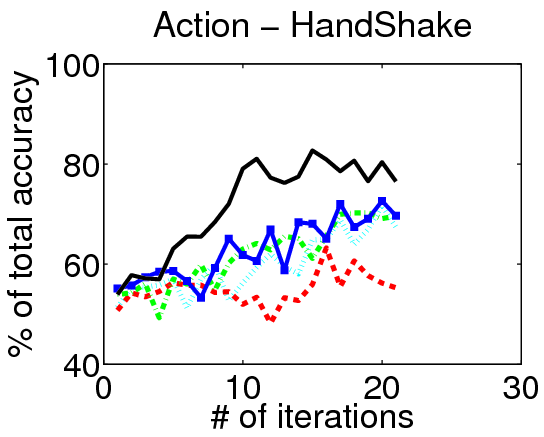
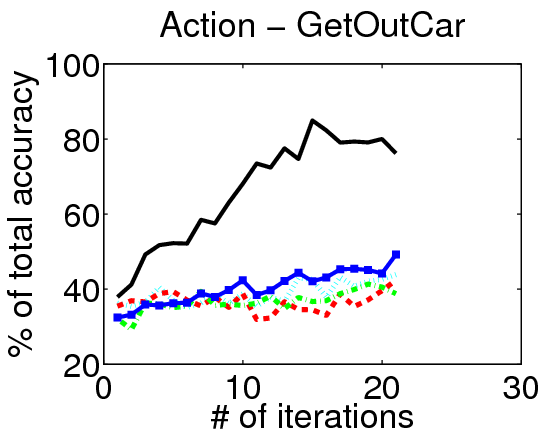
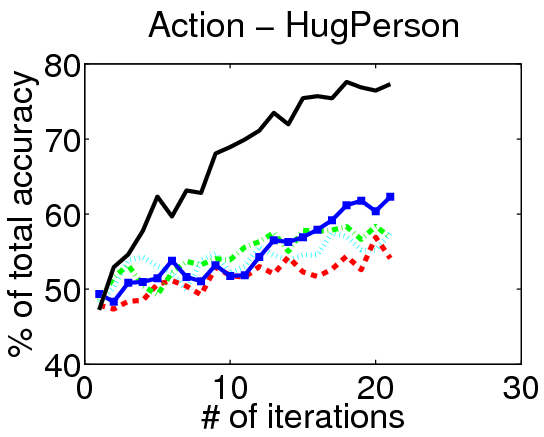
Video Annotations:
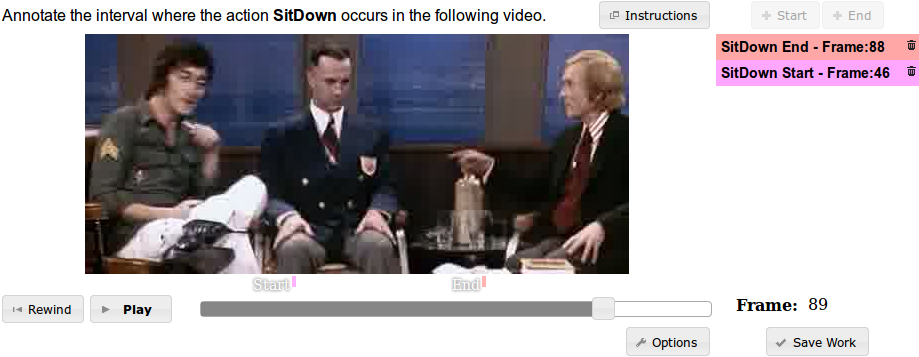
We enhanced the VATIC tool to allow annotators to specify the temporal interval in which an action is located. The interface allows the user to play the video, jump around in time with a slider, and quickly place start and end points.
On Hollywood, we improve the ground truth temporal trimming with our interface. We annotate videos with tighter temporal action intervals and share the annotations below.
Code & Data:
[VATIC for action annotation (code)] [Tighter temporal annotations on Hollywood dataset]
Original authors of VATIC:
Carl Vondrick, Donald Patterson, Deva Ramanan. "Efficiently Scaling Up Crowdsourced Video Annotation" International Journal of Computer Vision (IJCV). June 2012.
http://web.mit.edu/vondrick/vatic/
Publication:
Active Learning of an Action Detector from Untrimmed Videos. S. Bandla and K. Grauman. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, December 2013. [pdf]
Sunil Bandla
October 11, 2013