Active Frame Selection for Label Propagation in Videos
Sudheendra Vijayanarasimhan and Kristen Grauman
University of Texas at Austin
[pdf]
[code]
[data]
Manually segmenting and labeling objects in video sequences is quite tedious, yet such annotations are valuable for learning-based approaches to object and activity recognition. While automatic label propagation can help, existing methods simply propagate annotations from arbitrarily selected frames (e.g., the first one) and so may fail to best leverage the human effort invested. We define an active frame selection problem: select 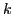 frames for manual labeling, such that automatic pixel-level label propagation can proceed with minimal expected error. We propose a solution that directly ties a joint frame selection criterion to the predicted errors of a flow-based random field propagation model. It selects the set of frames that together minimize the total mislabeling risk over the entire sequence. We derive an efficient dynamic programming solution to optimize the criterion. Further, we show how to automatically determine how many total frames should be labeled in order to minimize the total manual effort spent labeling and correcting propagation errors. We demonstrate our method's clear advantages over several baselines, saving hours of human effort per video.
frames for manual labeling, such that automatic pixel-level label propagation can proceed with minimal expected error. We propose a solution that directly ties a joint frame selection criterion to the predicted errors of a flow-based random field propagation model. It selects the set of frames that together minimize the total mislabeling risk over the entire sequence. We derive an efficient dynamic programming solution to optimize the criterion. Further, we show how to automatically determine how many total frames should be labeled in order to minimize the total manual effort spent labeling and correcting propagation errors. We demonstrate our method's clear advantages over several baselines, saving hours of human effort per video.
Figure 1:
Goal: actively select video frames for a human to label, so as to ensure minimal expected error across the entire sequence after automatic propagation.
|
![\includegraphics[width=0.9\linewidth]{figs/concept.eps}](img5.png) |
Our approach explicitily models "trackability" and uses it in the selection criterion to choose the most informative frames. Actively selecting these frames aims to minimize the manual effort spent in labeling the entire video sequence. Once the selected frames are labeled by human annotator, the labels are propagated to the rest of frames using optical flow and appearance based models.
Pixel Flow Propagation Method
The basic propagation method uses dense optical flow to track every pixel in both the forward and backward
directions until it reaches the closest labeled frames on either side. The pixel takes its label from the labeled frame (either left or right) with smaller expected propagation error.
Pixel Flow + MRF Propagation Method
A space-time Markov Random Field is used to enhance the basic flow based label propagation method. Using the motion based data terms and the usual MRF smoothness constraints, it infers label maps which are smooth in space and time. The object appearance model is learnt from the labeled frames.
We explicitly model the probability that a pixel is mistracked, by taking into account the errors which occur due to boundaries, occlusions, and when pixels change in appearance, or enter/leave the frame. We define the probability that pixel 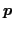 in frame
in frame 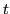 will be mislabeled if we were to obtain its label from frame
will be mislabeled if we were to obtain its label from frame 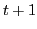 as:
as:
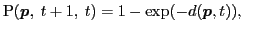 where where |
|
The component distances reflect the expected forms of tracking error and are defined using pixel appearance(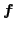 ) and optical flow field(
) and optical flow field(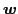 ) . Specifically,
) . Specifically,
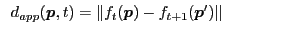 (Color Difference) (Color Difference) |
|
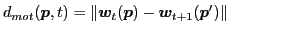 (Flow Difference) (Flow Difference) |
|
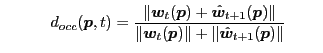 (Occlusion Detection) (Occlusion Detection) |
|
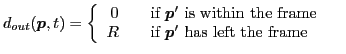 (Pixels leaving the frame) (Pixels leaving the frame) |
|
When there is more than one frame between labeled frame  and current frame , the error can be computed in a recursive manner (and analogously for
and current frame , the error can be computed in a recursive manner (and analogously for 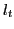 ),
),
Selection Criterion
To get a well-segmented video, there are two sources of manual effort cost:
- Cost of fully labeling a frame from scratch, denoted
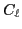
- Cost of correcting errors by the automatic propagation, denoted
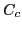 .
.
We now define an optimization problem for the best set of frames from which to propagate. Our aim is to choose subset 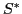 of frames to minimize the total expected effort:
of frames to minimize the total expected effort:
Since choosing which frame to propagate per pixel adds a factor of height width to the computation time, we modify this to select which frame to propagate per frame. Thus we can rewrite the cost in terms of an
width to the computation time, we modify this to select which frame to propagate per frame. Thus we can rewrite the cost in terms of an 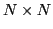 matrix
matrix 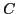 , where
, where
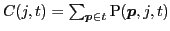 :
:
Dynamic Programming Solution
Let
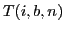 be the optimal value of
be the optimal value of
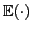 for selecting
for selecting 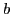 frames from the first
frames from the first 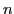 frames, where
frames, where 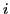 denotes the index of the -th selected frame.
denotes the index of the -th selected frame.
-
- Case 1: 1-way
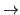 end.
end. 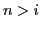
-
- Case 2: 1-way
beginning.
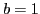 and
and 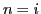
-
- Case 3: Both ways.
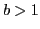 and
and
Once 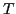 is computed, we obtain the optimal value for a given (where starts at since the minimum selected index for total frames is ) as:
is computed, we obtain the optimal value for a given (where starts at since the minimum selected index for total frames is ) as:
Datasets:
We use four publicly available datasets: (1) Camseq01: 101 frames of a moving driving scene. (2) Camvid_seq05: first 3000 frames from 0005VD sequence depicting a driving scene. (3) Labelme_8126: 167 frames depicting a traffic signal. (4) Segtrack: 6 videos with moving objects.
Baselines:
We compare our results with the following baselines:
- Uniform-f: samples frames uniformly starting with the first frame, and propagates labels in the forward direction only using our pixel flow method.
- Uniform: samples frames uniformly and transfers labels in both directions. Each frame obtains its labels from the closest labeled frame.
- Keyframe: selects representative frames by performing -way spectral clustering on global Gist features extracted for each frame. It requests labels for the frame per cluster with highest intra-cluster affinity.
Our Approach:
We evaluate three variants of our approach:
- DP-PF: selects frames using our dynamic programming (DP) algorithm and propagates labels using our pixel flow approach.
- DP-MRF: selects frames using our DP algorithm and propagates using our MRF-based formulation.
- DP2-MRF: automatically selects the number of frames and their indices by minimizing total annotation cost.
Figure 4:
Comparison of ground truth label propagation error with the error predicted by our model () for Labelme. Our error predictions follow the actual errors fairly closely.
|
|
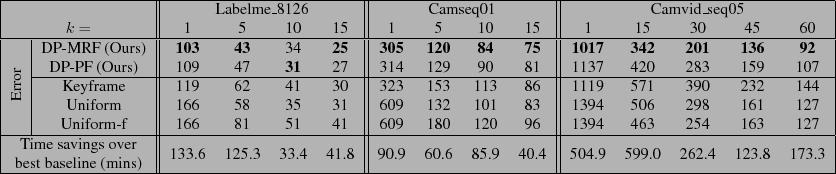
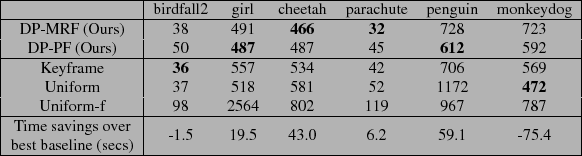
Table 1:
Results on Labelme, Camseq, and Camvid datasets. Values are average number of incorrect pixels (the standard metric in prior work) over all frames in hundreds of pixels for our method and the 3 baselines, for varying values. In all cases, our active approach outperforms the baselines, and yields significant savings in human annotation time (last row).
|
|
Table 2:
Results on the Segtrack dataset. Values denote pixel errors when
selecting k=5 frames for annotation.
|
|
Figure 5:
Each method's accuracy plotted for all frames, for two values of per sequence. Accuracy values are sorted from high to low per method for clarity. Our DP approaches (darker blue curves) have higher accuracy, esp. on frames far away from labeled frames.It reduces effort better than the baselines, and can also predict the optimal number of frames to have labeled, 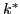 .
.
|
|
Our active frame selection approach outperforms the baselines in most cases, and saves hours of manual effort per video, if cost to correct errors is proportional to number of mislabeled pixels.
Figure 6:
Total human annotation time required to label each sequence, as a function of selections made per method. Darker lines are ours.
This result clearly shows the trade-off between the two types of effort--initial frame labeling, and correcting the algorithm's errors. For all methods,
the total annotation time has a sweet spot where the combined effort cost is minimized. Our method can automatically predict the optimal
number of frames to be labeled, which is close to the actual minimum.
|
|
Figure 7:
Frames selected by our approach for 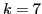 on the Camseq01
sequence. We see our approach selects non-uniformly spaced frames so that they contain
high resolution information of most of the objects that occur in the video (the two
cars, bicyclists, pedestrians).
on the Camseq01
sequence. We see our approach selects non-uniformly spaced frames so that they contain
high resolution information of most of the objects that occur in the video (the two
cars, bicyclists, pedestrians).
|
|
- Introduced and formulated the active multi-frame selection problem.
- Our approach models expected label propagation errors, and provides an efficient DP solution to make the optimal choice.
- Results show the real impact of our method in using human time for video labeling most effectively.
Active Frame Selection for Label Propagation in Videos.
S. Vijayanarasimhan and K. Grauman, In ECCV, 2012
[pdf]
[code]
[data]
The datasets tested in the paper:
This research is supported in part by the ONR Young Investigator Program, grant #N00014-12-1-0754
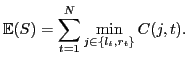
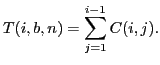
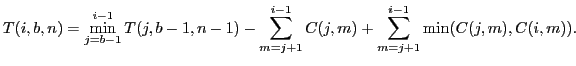
![\includegraphics[width=0.7\linewidth]{figs/flow_labels3.eps}](img8.png)
![\includegraphics[width=0.9\linewidth]{figs/propagation2.eps}](img9.png)
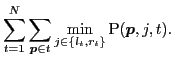
![\includegraphics[width=0.7\linewidth, height=0.25\linewidth]{figs/cases0.eps}](img41.png)
![\includegraphics[width=0.4\linewidth, height=0.25\linewidth]{figs/cases1.eps}](img42.png)
![\includegraphics[width=0.4\linewidth, height=0.25\linewidth]{figs/cases2.eps}](img43.png)
![\includegraphics[width=0.4\linewidth, height=0.25\linewidth]{figs/cases3.eps}](img44.png)
![\includegraphics[width=0.5\linewidth]{figs/labelme-predrisk.eps}](img54.png)
![\includegraphics[width=0.5\linewidth]{figs/labelme-actrisk.eps}](img55.png)
![\includegraphics[width=0.5\linewidth]{figs/labelme-sortedacc-7.eps}](img58.png)
![\includegraphics[width=0.5\linewidth]{figs/labelme-sortedacc-15.eps}](img59.png)
![\includegraphics[width=0.5\linewidth]{figs/camseq01-sortedacc-7.eps}](img60.png)
![\includegraphics[width=0.5\linewidth]{figs/camseq01-sortedacc-15.eps}](img61.png)
![\includegraphics[width=0.5\linewidth]{figs/camvid-sortedacc-15.eps}](img62.png)
![\includegraphics[width=0.5\linewidth]{figs/camvid-sortedacc-30.eps}](img63.png)
![\includegraphics[width=0.5\linewidth]{figs/labelme-totalcost.eps}](img64.png)
![\includegraphics[width=0.5\linewidth]{figs/camseq01-totalcost.eps}](img65.png)
![\includegraphics[width=0.3\linewidth]{figs/selections7-1.eps}](img66.png)
![\includegraphics[width=0.3\linewidth]{figs/selections7-2.eps}](img67.png)
![\includegraphics[width=0.3\linewidth]{figs/selections7-3.eps}](img68.png)
![\includegraphics[width=0.3\linewidth]{figs/selections7-4.eps}](img69.png)
![\includegraphics[width=0.3\linewidth]{figs/selections7-5.eps}](img70.png)
![\includegraphics[width=0.3\linewidth]{figs/selections7-6.eps}](img71.png)
![\includegraphics[width=0.3\linewidth]{figs/selections7-7.eps}](img72.png)