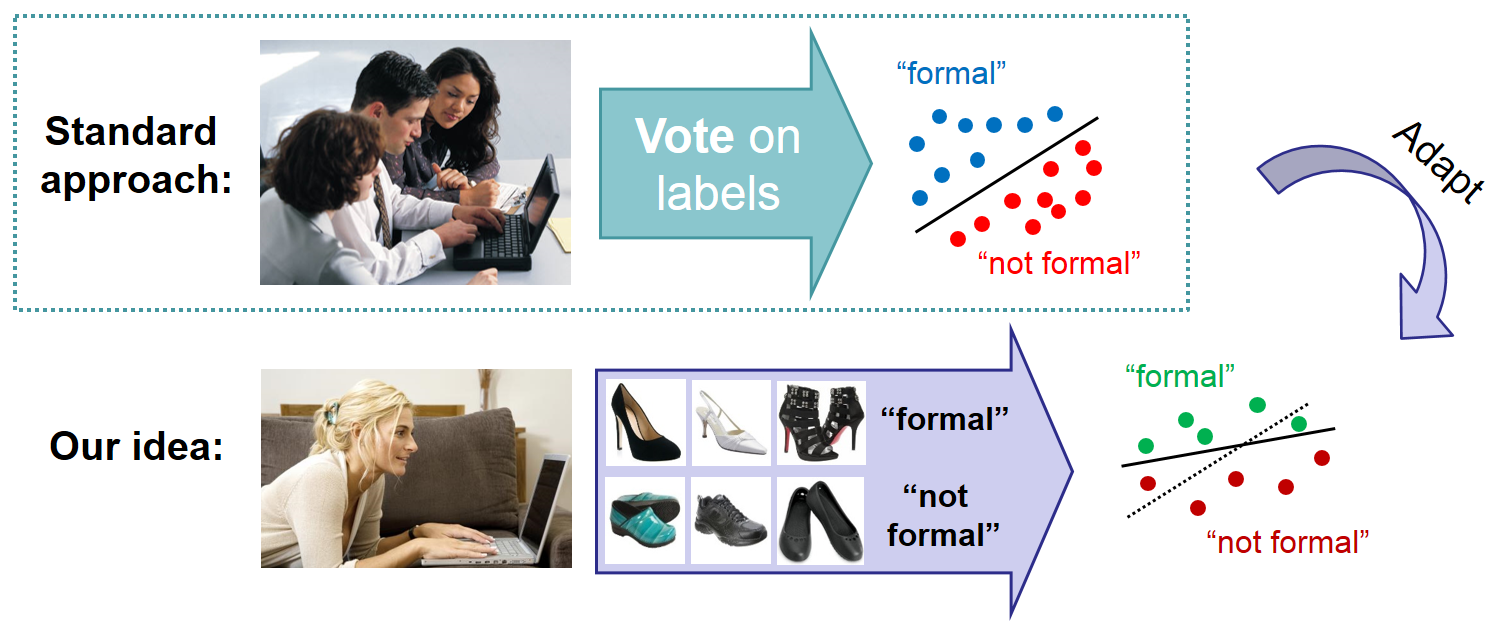
Current methods learn monolithic attribute predictors, with the assumption that a single model is sufficient to reflect human understanding of a visual attribute. However, in reality, humans vary in how they perceive the association between a named property and image content. For example, two people may have slightly different internal models for what makes a shoe look "formal", or they may disagree on which of two scenes looks "more cluttered". Rather than discount these differences as noise, we propose to learn user-specific attribute models. We adapt a generic model trained with annotations from multiple users, tailoring it to satisfy user-specific labels. Furthermore, we propose novel techniques to infer user-specific labels based on transitivity and contradictions in the user's search history. We demonstrate that adapted attributes improve accuracy over both existing monolithic models as well as models that learn from scratch with user-specific data alone. In addition, we show how adapted attributes are useful to personalize image search, whether with binary or relative attributes.
Existing methods (e.g. Lampert et al. CVPR 2009, Farhadi et al. CVPR 2009, Branson et al. ECCV 2010, Kumar et al. PAMI 2011, Scheirer et al. CVPR 2012, Parikh & Grauman ICCV 2011) assume that one model of an attribute is sufficient to capture all user perceptions. However, there are real perceptual differences between annotators. In the following example from our data collection, 5 users confidently declared the shoe on the left formal, while 5 confidently declared the opposite:
These differences also stem from the imprecision of attribute terms:

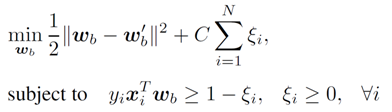
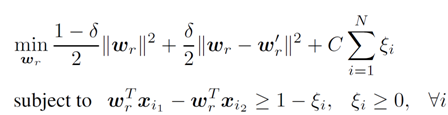
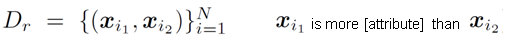
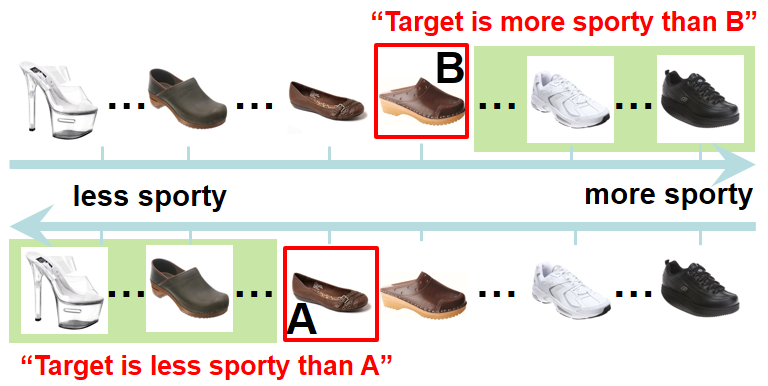
We can infer labels for relative attributes implicitly, from a user's search history. If T is the user's target image (which only he/she knows), and A and B are two reference images, then we can infer the right-hand side from the left-hand side via transitivity:
Alternatively, we can also use seeming contradictions in a user's search history. For example, feedback might imply that no images satisfy all constraints:
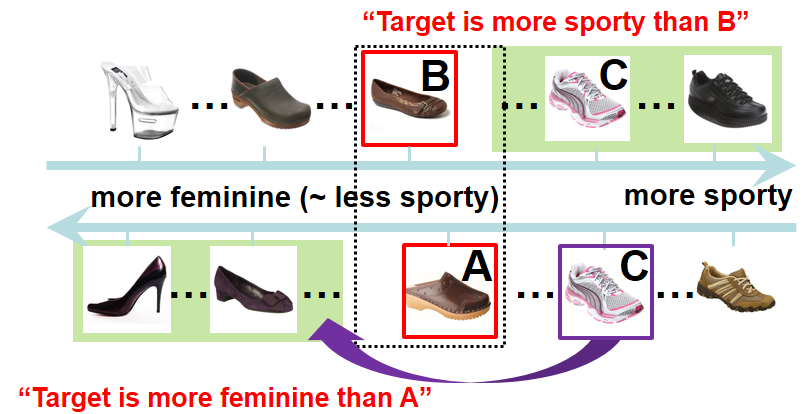
We then take pairs of images (in this case, A and C) in the opposite order of how current, and supply those as training pairs to the learner. This way, the set of images that satisfy all constraints is no longer empty.
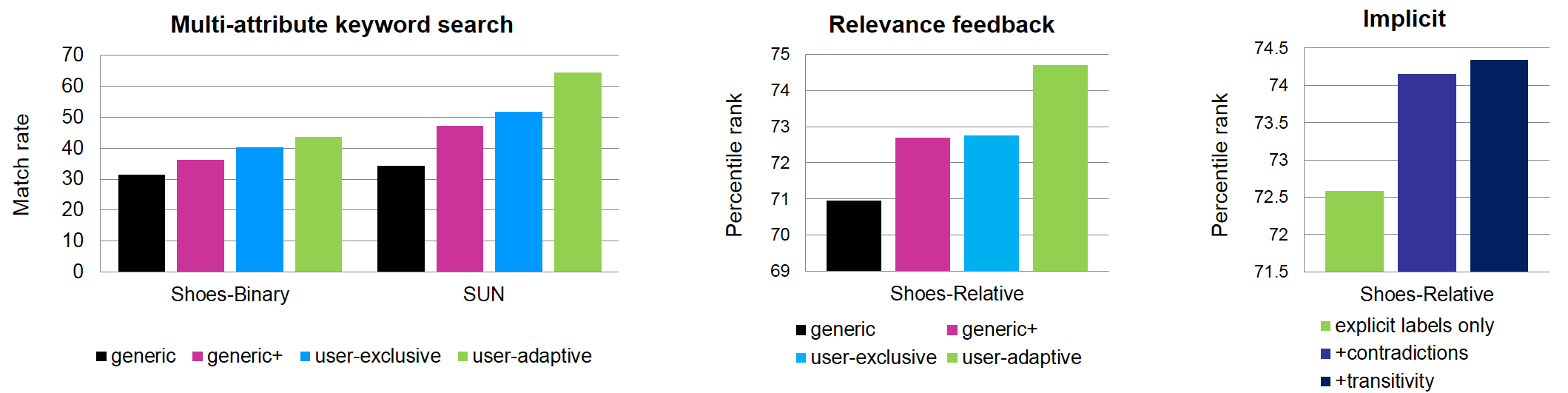
We use the following datasets and attributes:
We compare our User-adaptive approach against the following baselines:
We train models and test on a held-out set from each user. The following is the average over all attributes and users:
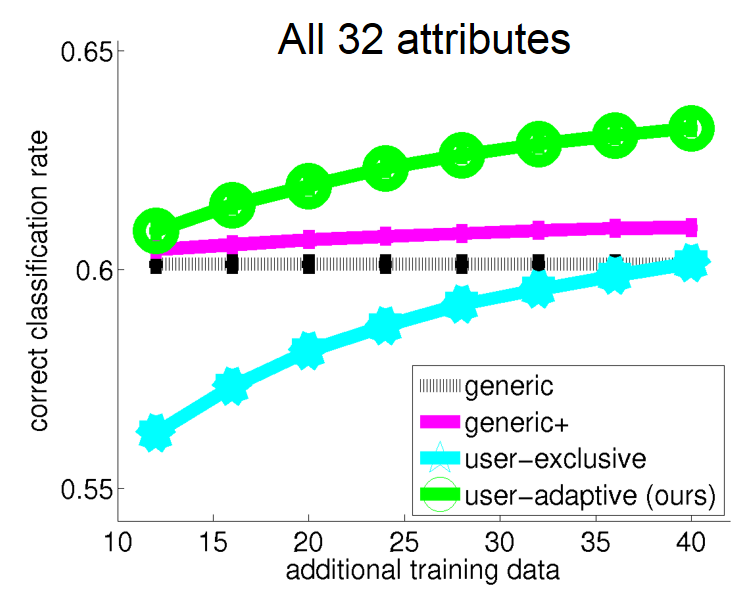
Please see our supplementary file for examples of the performance of the methods on individual users and attributes.
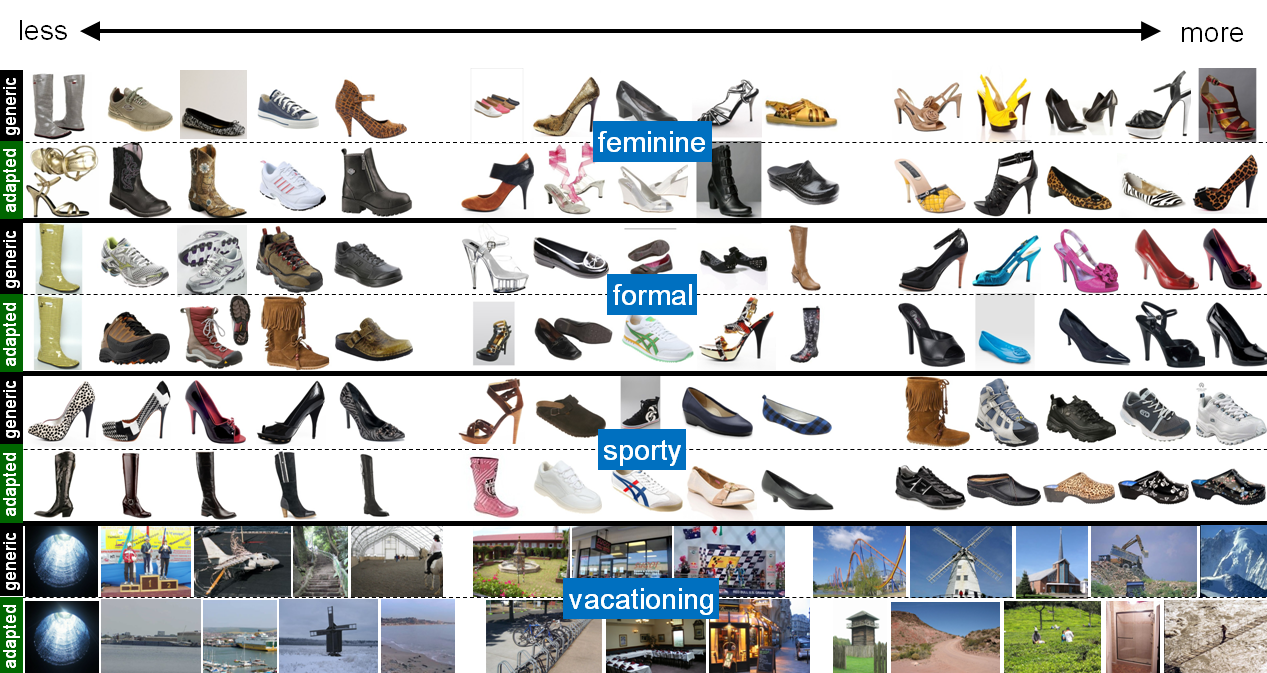
Below is a visualization of some learned generic and adapted spectra for four attributes.
We also show that the personalized attribute models allow the user to more quickly find his/her search target. Furthermore, implicitly gathering labels for personalization saves the user time, while producing similar results.