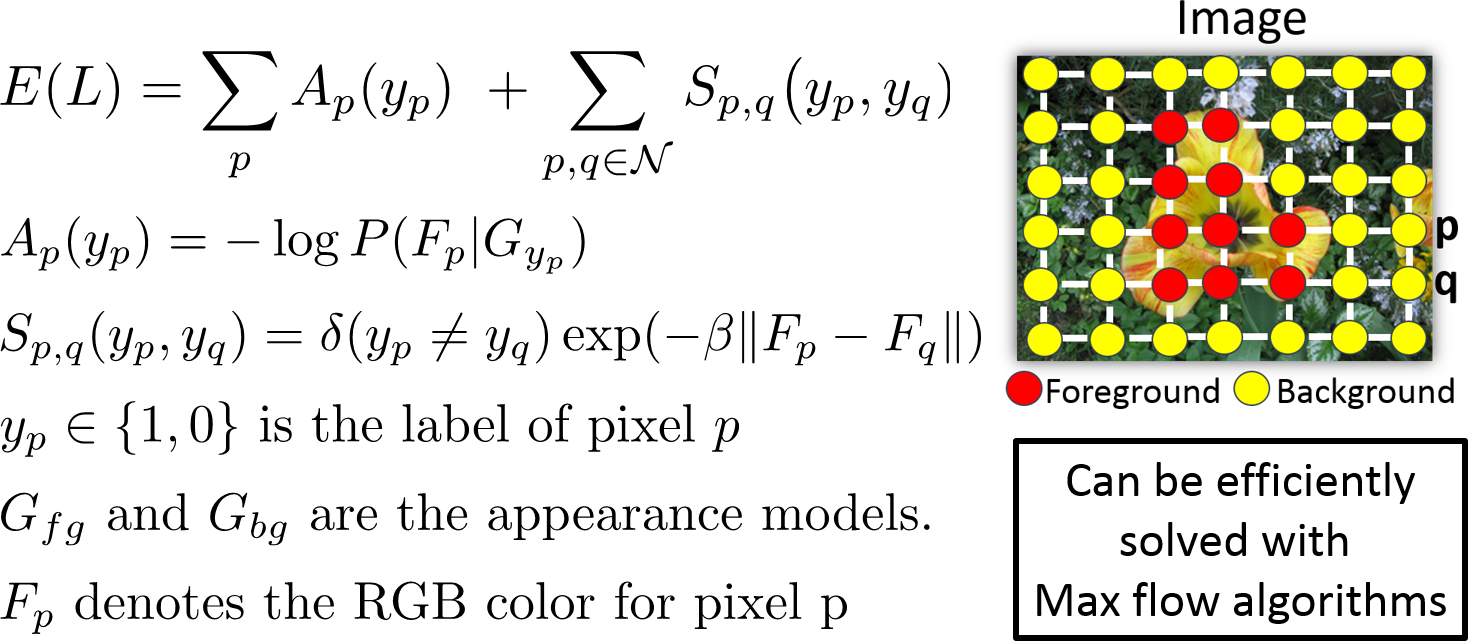
| Fixing the input modality for interactive segmentation methods is not optimal |
 |
Predicting Sufficient Annotation Strength for Interactive Foreground Segmentation
Suyog Dutt Jain Kristen Grauman
University of Texas at Austin
suyog@cs.utexas.edu
[pdf] [supplementary] [bibtex][poster][code] [data]
| Predict the annotation modality that is sufficiently strong for accurate segmentation of a given image |
 |
| Learning to predict segmentation difficulty per modality (Training) |
| Given a set of images with the foreground masks, we first simulate the user input. |
 |
| Use the overlap score between the resulting segmentation and ground truth to mark
an image
as ``easy" or ``hard" and train a linear SVM classifier (for each modality). |
| Bounding box example of ``easy" vs ``hard" |
 |
| Learning to predict segmentation difficulty per modality (Testing) |
| Use saliency detector to get a coarse estimate of foreground at test time. |
 |
| Liu et al. 2009 |
| Compute the proposed features and use trained classifiers to predict difficulty |
| Budgeted Selection |
| Goal: Given a batch of ``n" images with a fixed time budget ``B", we find the optimal
annotation tool for each image |
 |
Baselines:
Predicting segmentation difficulty per modality:
![\includegraphics[keepaspectratio=true,scale=0.30]{figs/MSRC_bounding_box_roc.eps}](img1.png) |
![\includegraphics[keepaspectratio=true,scale=0.30]{figs/iCoseg_bounding_box_roc.eps}](img2.png) |
![\includegraphics[keepaspectratio=true,scale=0.30]{figs/IIS_bounding_box_roc.eps}](img3.png) |
![\includegraphics[keepaspectratio=true,scale=0.30]{figs/ALL_bounding_box_roc.eps}](img4.png) |
![\includegraphics[keepaspectratio=true,scale=0.30]{figs/MSRC-contour_roc.eps}](img5.png) |
![\includegraphics[keepaspectratio=true,scale=0.30]{figs/iCoseg-contour_roc.eps}](img6.png) |
![\includegraphics[keepaspectratio=true,scale=0.30]{figs/IIS-contour_roc.eps}](img7.png) |
![\includegraphics[keepaspectratio=true,scale=0.30]{figs/ALL-contour_roc.eps}](img8.png) |
| Difficulty prediction accuracy for each dataset (first three columns) and cross-dataset experiments (last column) | |||
Cascade selection - application to recognition
Task: Given a set of images with a common object, train a classifier to separate object
vs. non object regions.
How to get data labeled?
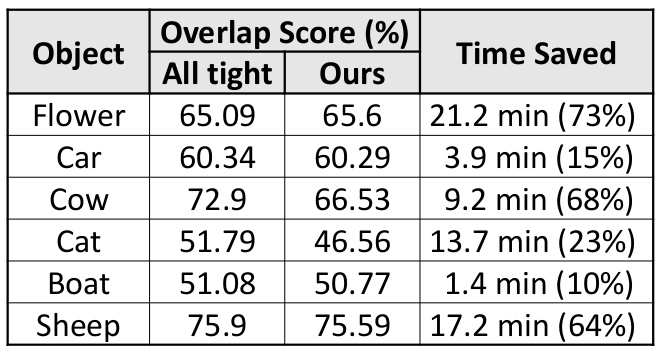
Budgeted selection - MTurk User study
Acknowledgements: This research is supported in part by ONR YIP N00014-12-1-0754.
Publication:
Predicting Sufficient Annotation Strength for Interactive Foreground Segmentation. S. Jain and K. Grauman. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, December 2013. [pdf] [supplementary] [bibtex][poster] [code] [data]




![\includegraphics[keepaspectratio=true,scale=0.60]{figs/userstudy_budget.eps}](img9.png)