Asymmetric Region-to-Image Matching for Comparing Images with Generic Object Categories
Jaechul Kim and Kristen Grauman
University of Texas at Austin
Summary
We propose a dense feature
matching algorithm that leverages bottom-up segmentation to compare generic
object categories with non-parametric geometric constraints. We call our image
matching “asymmetric” because only one of the input images is segmented into
regions, and its grouping of points can match within any (geometrically)
consistent portion of the other image. We find this deliberate imbalance to be
an advantage for matching: we get the grouping power of low-level segmentation
to keep coherent pixels of object sub-part undergoing a common geometric
distortion, but without suffering in the inevitable event where the bottom-up
cues produce incompatible regions for two images of the same object category.
We applied our image matching approach to exemplar-based object category
recognition, and show on Caltech-256 and 101 datasets that it outperforms
existing image matching measures by 10~20% in nearest neighbor recognition
tests.
Approach
Our approach can be summarized as follows:
(1) One of input images is segmented, but the other image is left
unsegmented.
(2) For each segmented region, we find correspondences between points
within each region of the segmented image and some points anywhere within the
unsegmented image (Region-to-image match). We use a dynamic programming to seek
the correspondences for each region-to-image match, so as to maximize both
geometric consistency and appearance similarity. (see Region-to-Image Match
section)
(3) The union of corresponding points from each region-to-image match
becomes the final set of matches between the two images.
(4) A final matching score between two images
is evaluated for mutual geometric consistency of final match points, at which
we favor low distortion matches for each segmented region, while allowing
larger deformations between the segmented regions. (see Scoring the Resulting
Correspondences section)
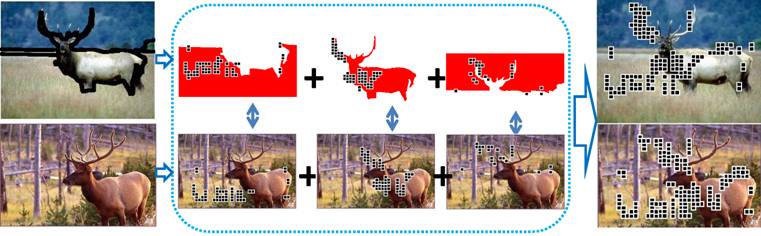
Figure 1. Overview of our approach. One of input images (top row, left)
is segmented, but the other image (bottom row, left) is left unsegmented. The
matching process begins by finding correspondences between points within each
region of the segmented image and some points within unsegmented image
(center). We call it “region-to-image match”. To efficiently identify
correspondences in each of the region-to-image match, we develop a dynamic
programming solution, so as to maximize both geometric consistency and
appearance similarity. The union of corresponding points from each
region-to-image match becomes the final set of matches between the two images
(right). Then, a final matching score between two images is evaluated for
mutual geometric consistency of final match points, at which we favor low
distortion matches for each segmented region, while allowing larger
deformations between the segmented regions.
Region-to-Image Match
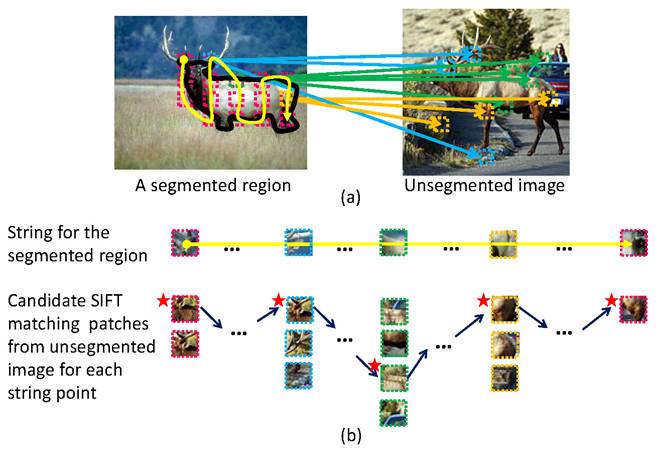
Figure 2. Region-to-image match. (a) A segmented region (inside the black
contour in the left image) is represented by a string (a yellow curve), which
links adjacent SIFT patches (dotted rectangles) densely sampled on a regular
grid in the segmented image. In this example, we illustrate a column-wise
linked string. For each point (i.e., patch) in the string, we identify
candidate matches in the (unsegmented) right image by SIFT patch matching. (b)
We use a dynamic programming (DP) to solve for assignment between the string
and the candidates that minimize the total geometry and appearance costs. Short
arrows and starts denote the optimal matches selected with DP. Each column of
patches represents the set of candidate matching points for each string point.
Summary of region-to-image match
(1) A region in the segmented image is mapped to a set of local SIFT
descriptors densely sampled at multiple scales on a regular grid. We denote
each grid location as a “point”.
(2) We represent each region by strings of its constituent points. To
more robustly represent the 2D layout using 1D string, we extract two strings
per region: a column-wise string and a row-wise string. In figure 2, we show a
column-wise string.
(3) For each point in the string, we first find a set of candidate
matching points in the unsegmented image, determined by the SIFT descriptor
distances across multiple scales. Candidate matches may come from anywhere in
the unsegmented image.
(4) Given these candidate matches, we compute the optimal correspondences
by using a dynamic programming (DP) to minimize a cost function that accounts
for both appearance and geometric consistency.
A cost function
A cost function minimized by DP consists of four terms to address
geometric and appearance consistency:
- The geometric distortion term measures the pairwise geometric
deformation between pairs of corresponding points. This gives preference to
neighboring match pairs that have similar distortion.
- The ordering constraint term penalizes the pairs of corresponding points
when they violate the geometric ordering. For example, if a point in the string
of the segmented region is located left of its next point in the string, its
matching point in the unsegmented image should be also located left of the next
point’s matching point.
- The displacement constraint term penalizes large displacement between
the locations of corresponding points, thereby giving some preference for
objects that occur within similar scene layout.
- The appearance similarity term penalizes dissimilarity between SIFT
patches extracted at two matching points.
For more details, please see section 3.1. in the paper.
Scoring the Resulting
Correspondences
The union of corresponding points from each region-to-image match becomes
the final set of matches between the two images. Then, we assign a single match
score between two original images from the final set. Note that while each
individual region match can be scored by a cost function for DP, the final
match score must incorporate the geometric distortion between the component region matches. Thus, we need more than just
summation of the costs of each region-to-image match.
The final match score both summarizes appearance similarity between
corresponding points as well as addresses their pairwise geometric
deformations. Also it assigns different weights to correspondences by assessing
the discriminating power of each correspondence. When accounting pairwise
geometric deformations, we impose more penalty on within-region matches than
across-region matches, thereby requiring stronger geometric consistency for
matching pairs within the same region, while allowing more distortions for the
matching pairs across different regions.
For more details, please see section 3.1. in the paper.
Discussion
Contrast between our (asymmetric) region-to-image match and (symmetric)
region-to-region match
In our asymmetric strategy, we exploit the fact that a group of pixels
within the same segment often belong to the same object part, giving us an
automatic way to generate groups which when matched to another image, should
have low geometric distortion. Once we take feature grouping given by the
segmentation in one image, we can find its geometrically consistent match in
any part of the second (unsegmented) image. This way, we can find the best
matches whether or not the region in the second image’s segmentation would have
happened to appear consistent to the first image’s segmentation. In contrast, a
region-to-region match uses a region as a matching primitive rather than as a
grouping purpose; thus, it always suffers from the inevitable events of
inconsistently decomposing different instances of the same generic category.
Figure 3 demonstrates such an inconsistency issue in a region-to-region match.

Figure 3. Inconsistent
segmentation between two images of the same generic category. In this example,
segmented regions from two images lack agreement, which in turn misleads a
region-to-region match.
About our string representation
A 1D string representation
gives us an efficient computation of pairwise geometric constraint by
accounting the pairwise geometric relations between only adjacent points on the
string. Existing methods still require computing 2D full pairwise relations,
whose computational complexity is O(m2n2) for image with m and n points, while we just need O(mn2).
The upshot is that ours is the first image matching method to realize a dense
matching with non-parametric geometric constraints—both aspects vital to
matching images with generic object categories. In addition, we should note
that our match is not string-to-string. Rather, we match a string from one
region to a set of candidate points anywhere in the segmented image identified
by local appearance similarity (see Figure 2). This means we avoid the pitfalls
of traditional DP-based string-to-string match, namely, sensitivity to the
string’s start and end points, and overly strict layout consistency
requirement.
Results
We apply our matching
algorithm to exemplar-based object category recognition on the Caltech-256 and
101 dataset. We achieved 61.3% accuracy on Caltech-101 for 15 test images and
15 exemplar images per a class, and 36.3% accuracy on Caltech-256 for 25 test
images and 30 exemplar images per a class. These numbers show that our algorithm
provides 10-20% better accuracy over existing matching-based categorization
techniques, and is competitive with methods that include more sophisticated
learning components when using the same local feature types. To our knowledge,
this is the first image matching algorithm tested on Caltech-256 that achieves
a raw matching accuracy comparable to some classifier-based algorithms. To see
more detailed comparison to the existing methods, please refer to the section 4
in the paper.
For qualitative evaluation, we show the nearest
neighbors for some image queries. Queries are selected from the hard categories
for which previous recognition methods produce below average accuracy. Our algorithm shows powerful matching results for those difficult object
categories under notable intra-class
variations or background clutter. Further, even for the failure cases (as judged by
the true category label of
the nearest exemplar), we find that the top matched images often show very similar geometric
configurations and appearance,
meaning the mistakes made are somewhat intuitive.
In addition, to get more convincing sense of how
well our matching algorithm works, you can check out our supplementary file which contains a large number of
examples of our matching results on the Caltech-256 dataset.

Figure 4. Examples
of matching results on the Caltech-256. Leftmost image in each
row is a query, following six are nearest exemplars found
by our method among 7680 total images.
Last
two rows show queries whose nearest exemplar has
the wrong label, and yet seem to be fairly intuitive errors.
Code : [download]
Publication
Jaechul Kim and Kristen Grauman,
Asymmetric Region-to-Image Matching for
Comparing Images with Generic Object Categories, In Proc.
International Conference on Computer Vision and Pattern Recognition (CVPR),
Jun. 2010. [pdf]