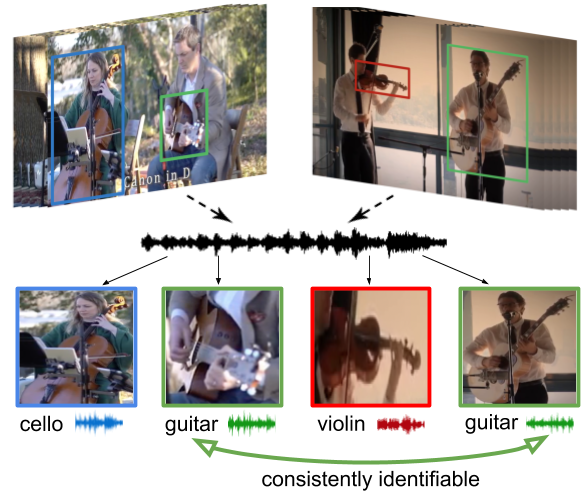
Learning how objects sound from video is challenging, since they often heavily overlap in a single audio channel. Current methods for visually-guided audio source separation sidestep the issue by training with artificially mixed video clips, but this puts unwieldy restrictions on training data collection and may even prevent learning the properties of "true" mixed sounds. We introduce a co-separation training paradigm that permits learning object-level sounds from unlabeled multi-source videos. Our novel training objective requires that the deep neural network's separated audio for similar-looking objects be consistently identifiable, while simultaneously reproducing accurate video-level audio tracks for each source training pair. Our approach disentangles sounds in realistic test videos, even in cases where an object was not observed individually during training. We obtain state-of-the-art results on visually-guided audio source separation and audio denoising for the MUSIC, AudioSet, and AV-Bench datasets.