Face Discovery with Social
Context
Yong Jae
Lee and Kristen Grauman

Summary
We
present an approach to discover novel faces in
untagged photo collections by leveraging "social
context" of co-occurring people. Our idea
exploits the social nature of consumer photos, in
which people of the same clique (family, team, class,
friends) often appear together. Initially, the
system trains detectors for any individuals with
tagged instances in the collection. Then, for
each untagged image, it isolates any unfamiliar
faces. Among those, it discovers novel face
clusters by leveraging both their appearance, as well
as descriptors encoding the (predicted) familiar faces
with which the unfamiliar faces co-occur. The
resulting discovered people can then be presented to a
user for name-tagging, thereby efficiently propagating
manually provided labels. Our experiments with
real consumer photo collections demonstrate that the
system outperforms baseline approaches that either
lack any social context model, or rely solely on the
appearance of co-occurring faces. Furthermore,
we show it can successfully use the discovered models
it forms to auto-tag unseen faces in a new collection.
Approach
We
first train SVM classifiers for N
initial people for whom we have tagged face
images. These classifiers will allow us to
identify instances of each familiar person in novel
images. We use those predictions to describe the
social context for each unfamiliar face.
For any unlabeled photo, we detect the people in it,
and then determine whether any of them resembles a familiar person.
To compute the known/unknown decision for a face
region r in an unlabeled image, we apply the
N trained classifiers to the
face to obtain its class membership posteriors.
To distinguish which faces should be considered to be
unknown, we compute the entropy. Faces with low
entropy values will likely belong to familiar people,
while those with high values will likely be
unfamiliar.
For
each unfamiliar face, we want to build a description
that reflects that person's co-occurring familiar
people, at least among those that we can already
identify. Having such a description allows us to
group faces that look similar and often appear among
the same familiar people.
Suppose
an image has T total faces. We
define the social context descriptor S(r)
as an N-dimensional vector that captures the
distribution of familiar people that appear in the
same image:
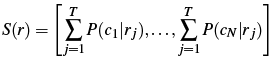
If
our class predictions were perfect, with posteriors
equal to 1 or 0, this descriptor would be an indicator
vector telling which other people appear in the
image. When surrounding faces do belong to
previously learned people, we will get a "peakier"
vector with reliable context cues, whereas when they
do not appear to be a previously learned person the
classifier outputs will simply summarize the
surrounding appearance.
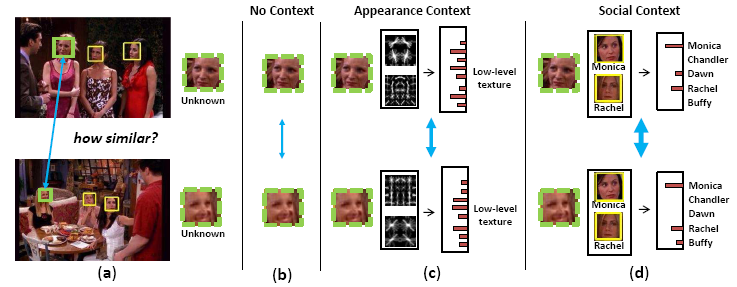
An example illustrating the
impact of social context for discovery. The blue
double-headed arrows indicate strength in affinity
between the unknown regions. (a) Two images,
where the unfamiliar faces are outlined in
green. (b) Appearance information alone can be
insufficient to deal with large pose or expression
variations. (c) Modeling the context surrounding
the face of interest can provide more reliable
similarity estimates, but a context descriptor using
raw appearance is limiting since it can only describe
nearby faces with texture or color. (d) By
modeling the social context using learned models of
familiar people, we can obtain accurate matches
between faces belonging to the same person.
Finally,
we cluster all faces that were deemed to be unknown,
using spectral or agglomerative clustering. We
want the discovered groups to be influenced both by
the appearance of the face regions themselves, as well
as their surrounding context. Therefore, given
two face regions rm and rn,
we evaluate a kernel function K
that combines their appearance similarity and context
similarity:
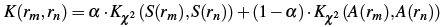
where
A(r)
is the appearance descriptor, alpha
weights the contribution of social context
versus appearance, and each Kx2
is a chi-squared kernel function for histogram inputs
x
and y.
Results
We
compare our method to a no-context baseline that simply
clusters the face regions' low-level texture features,
and an appearance-context
discovery method that uses the appearance of
surrounding faces as context. These are
important baselines to show that we would not be as
well off simply looking at a model of appearance using
image features, and to show the impact of social
context analysis versus a low-level appearance context
description for discovery.
We validate on three datasets of consumer photo
collections composed of 1,000 to 12,000 images and 23
to 152 people. We partition each dataset into
two random subsets. The first is used to train N classifiers for the initial
"knowns". On the second subset, we perform
discovery using the N
categories as context to obtain our set of discovered
categories. This reflects the real scenario
where a user has tagged only some of his/her family
members and friends.

The
table shows discovery results as judged by the
F-measure. Higher values are better. Our method significantly
outperforms the baselines, validating our claim that
social context leads to better face discovery.
Our substantial improvement over the
appearance-context baseline shows the importance of
representing context with models of familiar
people.
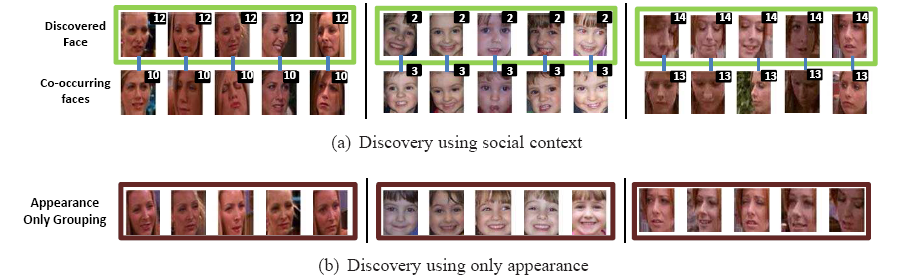
The figure above shows qualitative discovery
examples. (a)
The first row shows representative faces of the
dominant person for a discovered face, with their
respective co-occurring faces below. The second
row faces belong to a known person---their social
context helps to group the diverse faces of the same
person in the first row. (b) Limitations of
appearance-based grouping. The images show
representative faces of the dominant person for a
discovered face using only appearance features. Notice
the limited variability in pose and expression of each
grouped person, as compared to our discoveries in
(a).
In the paper, we study several other aspects of
interest including (1) how accurately we predict novel
instances to be familiar or unfamiliar, and (2) how
our discovered faces can be used to predict tags in
novel photos. Our results show that the models
learned from faces discovered using social context
generalize better on novel face instances than those
learned from faces discovered using appearance
alone. This is evidence that our approach can
indeed serve to save human tagging effort.
Publication
Face Discovery with Social Context [pdf]
Yong
Jae Lee and Kristen Grauman
To appear,
In Proceedings
of the British Machine Vision Conference (BMVC),
Dundee, Scotland, August 2011.