Given two images, we want to predict which exhibits a particular visual attribute more than the other — even when the two images are quite similar. Existing relative attribute methods rely on global ranking functions; yet rarely will the visual cues relevant to a comparison be constant for all data, nor will humans’ perception of the attribute necessarily permit a global ordering. To address these issues, we propose a local learning approach for fine-grained visual comparisons. Given a novel pair of images, we learn a local ranking model on the fly, using only analogous training comparisons. We show how to identify these analogous pairs using learned metrics. With results on three challenging datasets — including a large newly curated dataset for fine-grained comparisons — our method outperforms stateof-the-art methods for relative attribute prediction.
Overview
Scenario: Ted is shopping online for a new pair of “sporty looking” shoes. After narrowing down his choices, he would like to finalize his decision by performing pairwise comparisons based on the relative attribute “sporty”.
Main Task: Given 2 distinct images, determine the one with more of the attribute than the other.
The current status quo takes a global learning approach where a single ranking model is trained using all available data. While such an approach might be sufficient for coarse comparisons (soccer cleats vs. high heel), it is highly insufficient for fine-grained comparisons (running shoe vs. running shoe). A global model tends to accommodate for the gross visual differences that govern the attribute’s spectrum but it cannot simultaneously account for the many fine-grained differences among closely related examples. e.g. What makes a soccer shoe appear more sporty than a high heel is significantly different from what makes one running shoe appear more sporty than another.
Problem: A global learning approach fails to account for the subtle differences among closely related images.
Our Approach
We propose a local learning approach for fine-grained visual comparisons. Note that while local learning has been studied previously on learning classification models using individual images, we're learning ranking models using pairs of images.
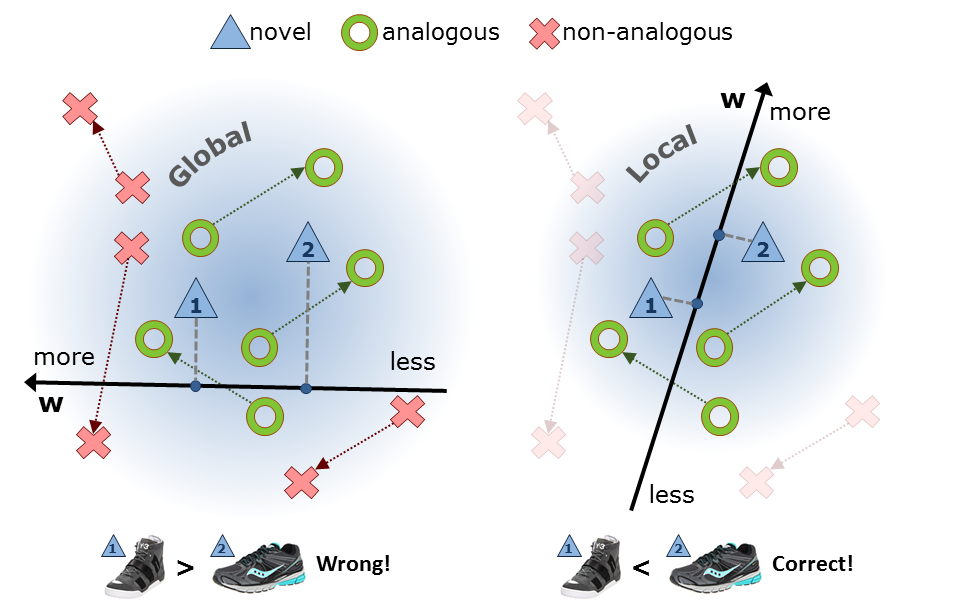
Illustration: Comparing Shoe 1 and Shoe 2 with respect to the relative attribute “sporty”. A dotted line links each pair of training images with the arrow pointing towards the image with more of the attribute. The goal is to find a ranking function W that maximizes the distance between the projections of each pair of training images while preserving their orderings [Parikh & Grauman 11].
The existing gloal approach (left) learns a W grossly using all available training pairs. In contrast, our local approach (right) learns a W with only the most analogous neighboring pairs for each novel test pair. These local functions are custom tailored to the neigborhood statistics of the individual novel test pairs respectively.
Analogous Neighboring Pairs
Intuition: A key factor to the success of our local rank learning approach is how we judge similarity between pairs. We would like to gather training pairs that are somehow analogous to the test pair, so that the ranker focuses on the fine-grained visual differences that dictate their comparison. This means that not only should individual members of the pairs have visual similarity, but also the visual contrasts between the two test pair images should mimic the visual contrasts between the two training pair images.
Learned Attribute Distance
When identifying neighboring pairs, rather than judge image distance by the usual Euclidean distance on global descriptors, we want to specialize the function to the particular attribute at hand. That's because often a visual attribute does not rely equally on each dimension of the feature space, whether due to the features' locations or modality. For example, if judging image distance for the attribute “smiling”, the localized region by the mouth is likely most important; if judging distance for “comfort” the features describing color may be irrelevant.
Metric Learning: To this end, we learn a Mahalanobis metric for each attribute. The key observation is that the nearest analogous pairs most suited for local learning need not be those closest in the raw feature space.
UT-Zap50K Dataset
We introduce a new large dataset UT-Zap50K, consisting of 50,025 catalog images from Zappos.com and comparison labels on 4 relative attributes. Please visit our dataset page for more information.
Results
We evaluate our method on 3 challenging datasets: UT-Zap50K (shoes), OSR (scenes), and PubFig (faces). We compare our method to the state-of-the-art methods and the baselines described below:
FG-LocalPair: Our proposed fine-grained local approach.
LocalPair: Our approach w/o the learned metric. Isolates the impact of not tailoring the neighbor search to each attribute.
RandPair: A local approach that selects its neighbors randomly. Demonstrates the importance of selecting the right neighbors.
Global [Parikh & Grauman 11]: Status quo of learning a single global ranking function using all available data.
RelTree [Li et al. 12]: A non-linear relative attribute approach. Holds the current state-of-the-art performance on OSR & PubFig.
UT-Zap50K
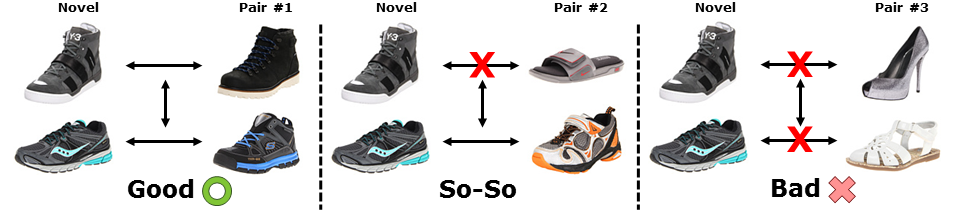
Qualitative: We contrast our predictions to the Global baseline's. In each pair, top item is more sporty than bottom item according to ground truth from human annotators. (1) We predict correctly, Global is wrong. We detect subtle changes, while Global relies only on overall shape and color. (2) We predict incorrectly, Global is right. These coarser differences are sufficiently captured by a global model. (3) Both methods predict incorrectly. Such pairs are so fine-grained, they are difficult even for humans to make a firm decision.
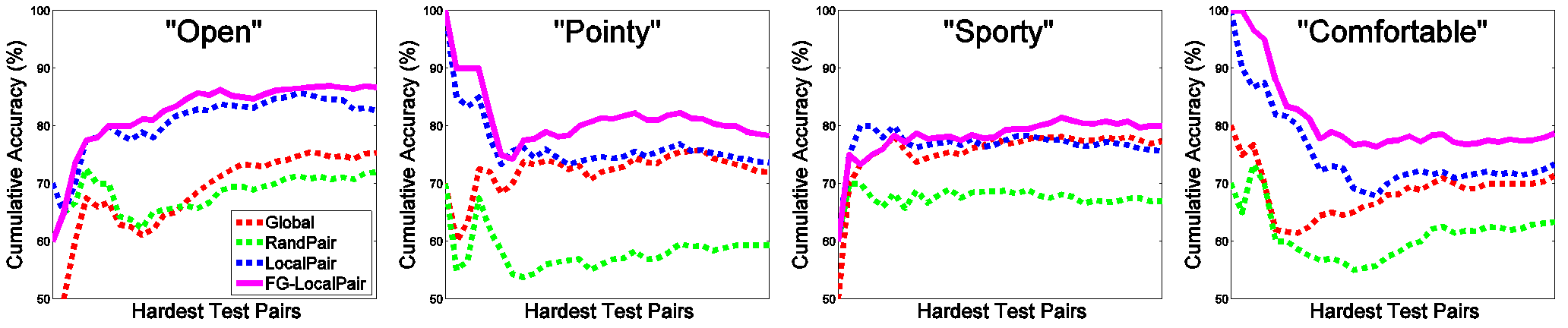
We proceed to isolate the more difficult pairs. We sort the test pairs by their intra-pair distance and identify the 30 hardest test pairs per attribute (shown below). In addition, we also evaluate on 4,334 fine-grained pairs for even harder comparisons.
Observation: We outperform all baselines, demonstrating strong advantage for detecting subtle differences on the harder comparisons (~20% more). See paper for more extensive results.
OSR & PubFig
We form supervision pairs using the category-wise comparisons, resulting in about 20,000 ordered labels on average per attribute.
Outdoor Scene Recognition (OSR): 2,688 images w/ 6 attributes, GIST features
Public Figure Faces (PubFig): 772 images w/ 11 attributes, GIST+RGB features
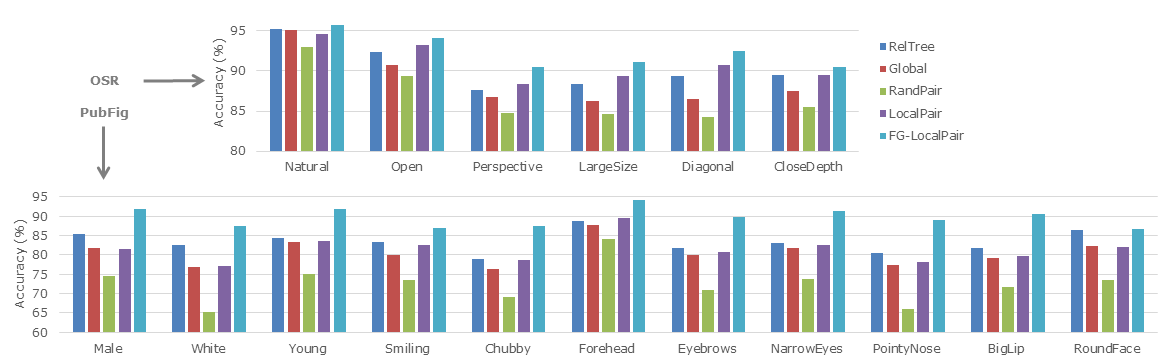
Observation: We outperform the current state-of-the-art for all attributes on both relative attributes datasets. Our gains are especially dominant (up to 9% over RelTree) on the more localizable attribute due to the learned metrics.
Publication
A. Yu and K. Grauman. "Fine-Grained Visual Comparisons with Local Learning". In CVPR, 2014.[bibtex]
@InProceedings{fine-grained, author = {A. Yu and K. Grauman}, title = {Fine-Grained Visual Comparisons with Local Learning}, booktitle = {Computer Vision and Pattern Recognition (CVPR)}, month = {Jun}, year = {2014} }