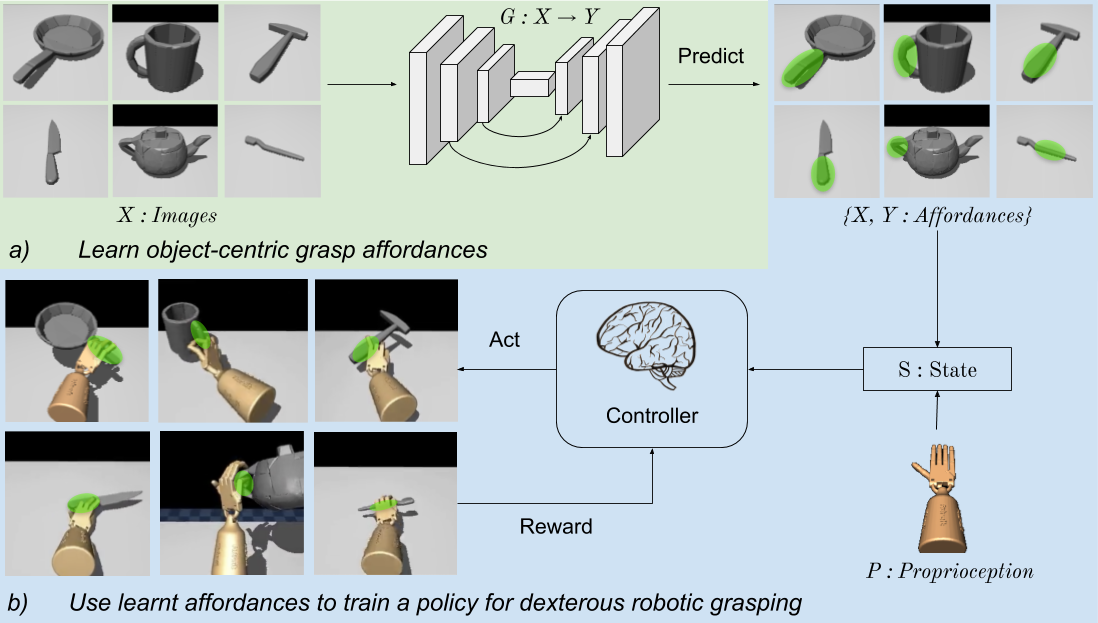
| In this work, we aim to learn deep RL grasping policies for a dexterous robotic hand by injecting a visual affordance prior that encourages using parts of the object used by people for functional grasping. Given an object image, we predict the affordance regions, and use it to influence the learned policy. The key upshots of our approach are better grasping, faster learning, and generalization to successfully grasp objects unseen during policy training. |
|