Semantic Kernel Forests from Multiple Taxonomies
Sung Ju Hwang, Fei Sha and Kristen Grauman
The University of Texas at Austin
University of Southern California
Abstract
We introduce an approach to learn discriminative visual representations while exploiting external semantic knowledge about object category relationships. Given a hierarchical taxonomy that captures semantic similarity between the objects, we learn a corresponding tree of metrics (ToM). In this tree, we have one metric for each non-leaf node of the object hierarchy, and each metric is responsible for discriminating among its immediate subcategory children. Specifically, a Mahalanobis metric learned for a given node must satisfy the appropriate (dis)similarity constraints generated only among its subtree members training instances. To further exploit the semantics, we introduce a novel regularizer coupling the metrics that prefers a sparse disjoint set of features to be selected for each metric relative to its ancestor (supercategory) metrics. Intuitively, this reflects that visual cues most useful to distinguish the generic classes (e.g., feline vs. canine) should be different than those cues most useful to distinguish their component
fine-grained classes (e.g., Persian cat vs. Siamese cat). We validate our approach with multiple image datasets using the WordNet taxonomy, show its advantages over alternative metric learning approaches, and analyze the meaning of attribute features selected by our algorithm
Motivation
The conventional use of a semantic taxnomy in object categorization is limited in two ways.
 |
 |
| 1) The structure is not always optimal for hierarchical classification |
2) There exists no single 'optimal' taxonomy |
Idea
We want to focus on the implicit information provided by the taxonomy - that is, the criteria used to classify subclasses at different semantic granularity [1]
Different taxonomies provide complementary information, which could be exploited to learn discriminative visual features. Instead of focusing on a single taxonomy, and use it directly for hierarchical classificaiton, we want to exploit
multiple taxonomies for feature learning, and combine the learned features in a
non-hierarchical way.
Approach
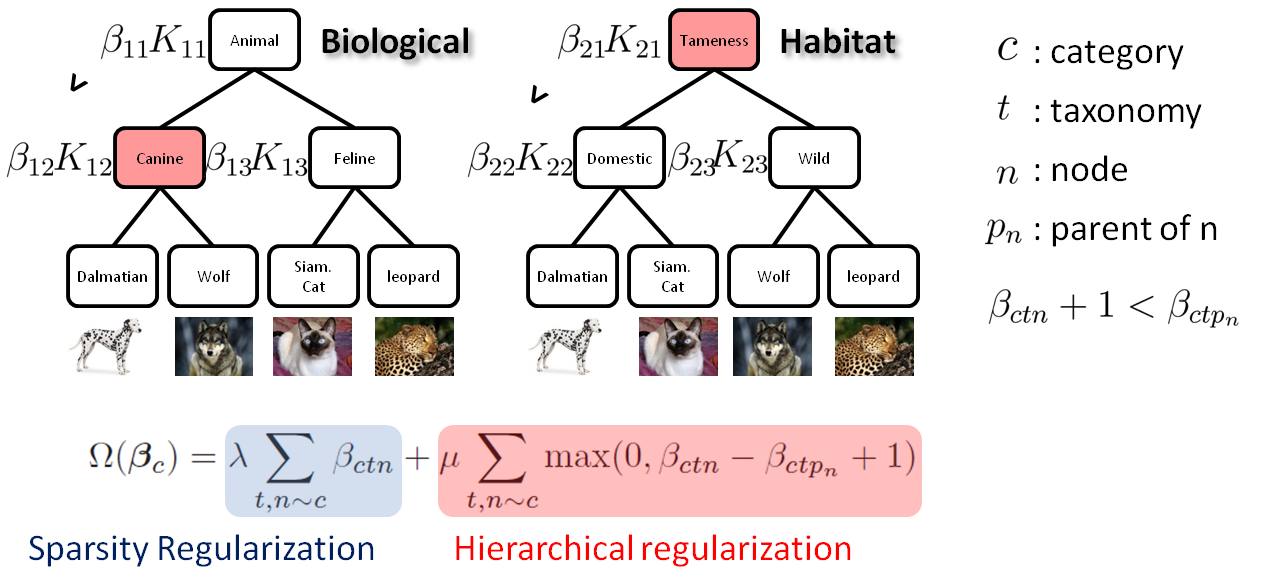
Our method comprises of two steps: 1) Learning granularity-specific semantic discriminative features. 2) Combining features at different semantic views and granularities.
Isolating granularity-specific discriminative features from multiple taxonomies
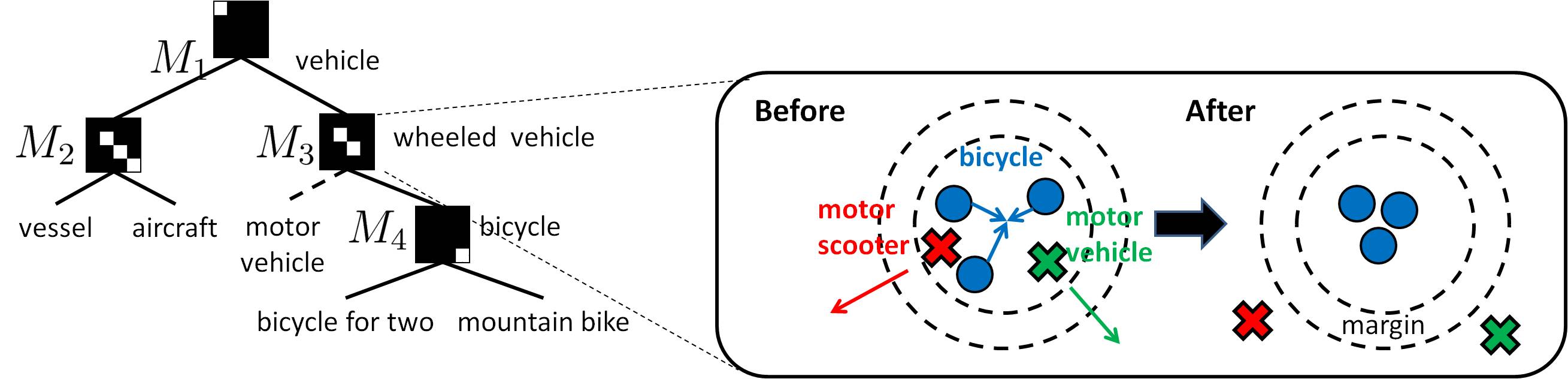 |
To learn granularity-specific discriminative features on each taxonomy, we use
Tree of Metrics (ToM), that learns hierarchically structured metrics that focus on different features at each node.
Combining features at different semantic views and granularities
After having isolated per-granularity discriminative semantic features at each node, we want to combine them to learn optimal per-category feature.
Semantic Kernel Forest
We first construct RBF kernels on each node, using the metrics obtained from ToM. We call the resulting set of kernels as
Semantic Kernel Forest.
Learning per-category kernel from Semantic Kernel Forest using MKL
After isolating semantic, discriminative features at each node, we combine them in an
additive manner using multiple kernel learning. Note that we only consider the kernels on the tree path.
Sparse hierarchical regularization
L1 regularization is usally applied to the original MKL formulation, in case not all kernels are relevant and we want to select out useful ones. Semantic kernel forests inevitably result in redundant kernels for categorization between two classes. In this case, we want to favor higher-level kernels, as they have more generalization power.
Result
Dataset
We validate our method on three different datasets,
AWA-4 (4 categories used for illustration),
AWA-10, and
Imagenet-20.
|
AWA-10 |
Imagenet-20 |
| # images |
6,180 |
28,957 |
| # classes |
10 |
20 |
| Granularity |
Fine-grained |
Coarser-grained |
| Taxonomies |
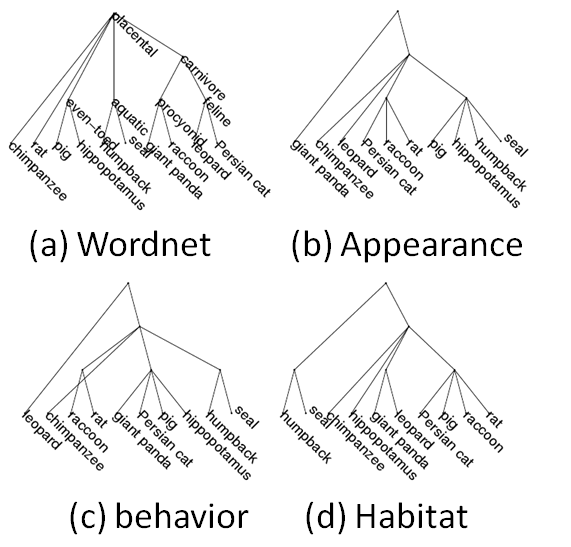 |
 |
Multiclass classification
| Method
| Description
| AWA-4
| AWA-10
| Imagenet-20
|
| Raw feature kernel |
an RBF kernel computed on the original features |
47.67 ± 2.22 |
30.80 ± 1.36 |
28.20 ± 1.45 |
| Raw feature kernel + MKL |
MKL combination of RBF kernels constructed by varying gamma |
48.50 ± 1.89 |
31.13 ± 2.31 |
27.57 ± 1.50 |
| Perturbed semantic kernel tree + MKL-H |
a semantic kernel tree trained with taxonomies that have randomly swapped leaves |
N/A |
31.53 ± 2.07 |
28.20 ± 2.02 |
| Perturbed semantic kernel forest + MKL-H |
semantic kernel forest trained with taxonomies that have randomly swapped leaves |
N/A |
33.20 ± 2.96 |
30.77 ± 1.53 |
| Semantic kernel tree + Avg |
an equal-weight average of the semantic kernels from one taxonomy |
47.17 ± 2.40 |
31.92 ± 1.21 |
28.97 ± 1.61 |
| Semantic kernel tree + MKL |
the same kernels, combined with MKL using sparsity regularization only |
48.89 ± 1.06 |
32.43 ± 1.93 |
29.74 ± 1.26 |
| Semantic kernel tree + MKL-H |
the same as the above, but adding the proposed hierarchical regularization |
50.06 ± 1.12 |
32.68 ± 1.79 |
29.90 ± 0.70 |
| Semantic kernel forest + MKL |
semantic forest kernels from multiple taxonomies combined with MKL |
49.67 ± 1.11 |
34.60 ± 1.78 |
30.97 ± 1.14 |
| Semantic kernel forest + MKL-H |
the same as the above, but adding our hierarchical regularizer |
52.83 ± 1.68 |
35.87 ± 1.22 |
32.30 ± 1.00 |
Per-class results
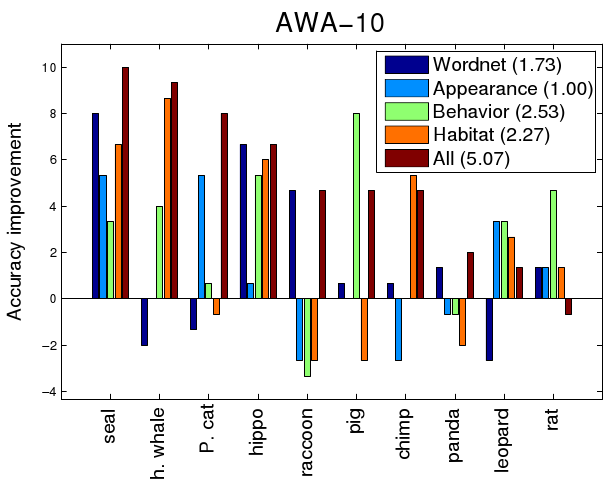
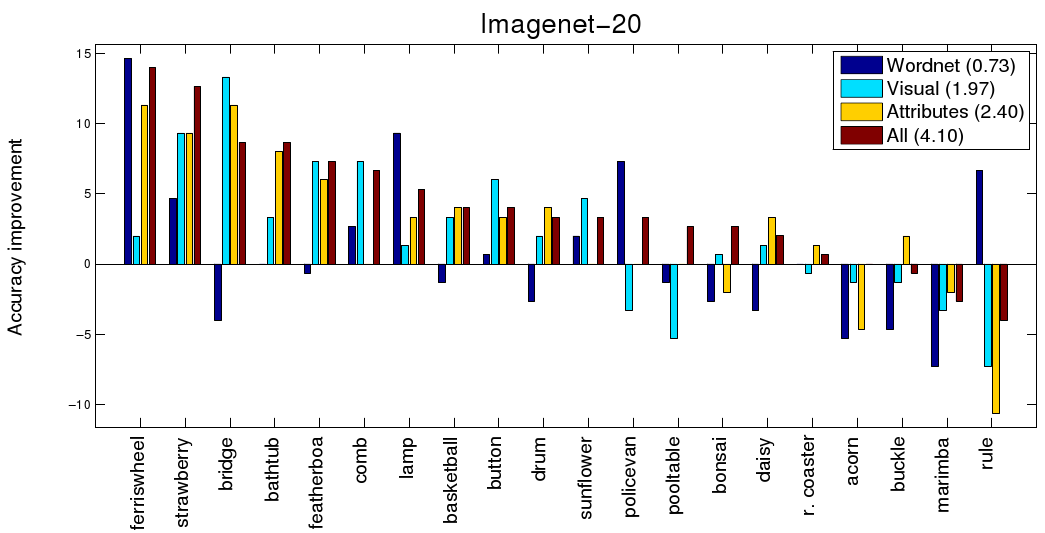
The below two plots are per-class accuracy improvements of each individual taxonomy and the semantic kernel forest ("All") over the raw kernel baseline.
A single semantic kernel tree often improves accuracy on some classes, but at the expense of reduced accuracy on others (e.g. Habitat on AWA-10 helps to distinguish humpback whale, but hurts accuracy for giant panda). On the other hand, semantic kernel forest takes best of both through its learned combination.
Qualitative Analysis
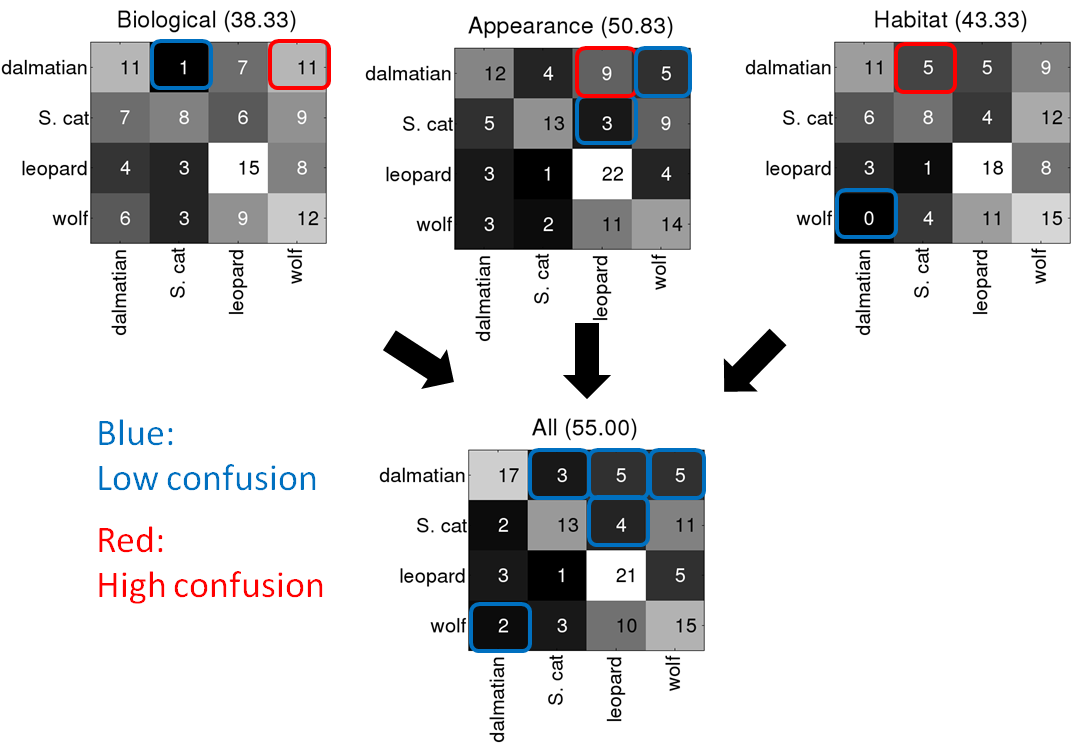
Confusion matrix on 4 animal classes
The top three confusion matrices are obtained using only top-level kernel from each taxonomy, and the bottom is obtained from combining them using MKL. Each taxonomy-derived kernel reduces confusion between some categories but add confusion to others, and the combined kernel reduces confusion among all by taking complementary information from each.
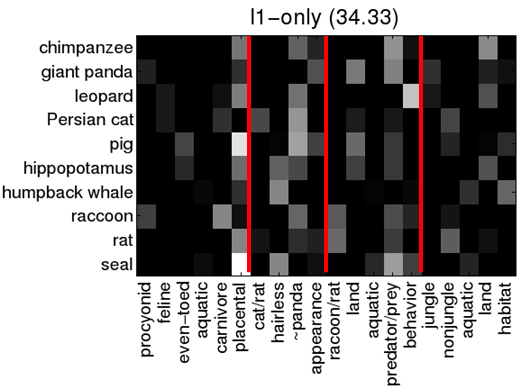
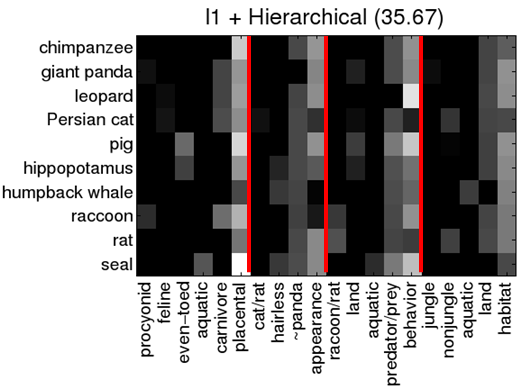
Learnt kernel weights
The above are the weights learned for each category from AWA-10. We see that higher-level kernels are selected using the regularization, which results in an accuracy improvement.
References
[1] Sung Ju Hwang, Kristen Grauman and Fei Sha, Tree of Metrics with Disjoint Visual Features, NIPS 2011
Source code and data
[kernelforest.tar.gz] 64Mb. Contains matlab codes (v0.9) for both
tree of metrics and semantic kernel forests, and data.
v1.0 in C++ with OpenMP for parallel classifier training will be released soon.
[taxonomyutil.tar.gz] Contains matlab codes to generate taxonomy from WordNet, and also taxonomy data for 4 taxonomies from AWA-10, and 3 taxonomies from ImageNet-20
Publication
Sung Ju Hwang, Kristen Grauman and Fei Sha Semantic Kernel Forests from Multiple Taxonomies
Advances in Neural Information Processing System (NIPS), Lake Taho, NV, USA, December 2012