
Summary
We present an approach to discover and segment
foreground object(s) in video. Given an unannotated
video sequence, the method first identifies object-like
regions in any frame according to both static and dynamic
cues. We then compute a series of binary partitions
among those candidate "key-segments" to discover hypotheis
groups with persistent appearance and motion. Finally,
using each ranked hypothesis in turn, we estimate a
pixel-level object labeling across all frames, where (a) the
foreground likelihood depends on both the hypothesis’s
appearance as well as a novel localization prior based on
partial shape matching, and (b) the background likelihood
depends on cues pulled from the key-segments’ (possibly
diverse) surroundings observed across the sequence.
Compared to existing methods, our approach automatically
focuses on the persistent foreground regions of interest while
resisting oversegmentation. We apply our method to
challenging benchmark videos, and show competitive or better
results than the state-of-the-art.
Approach
Our goal is to discover object-like
key-segments in an unlabeled video, and learn appearance and
shape models from them to automatically segment the foreground
objects. The main steps to our approach are shown below.
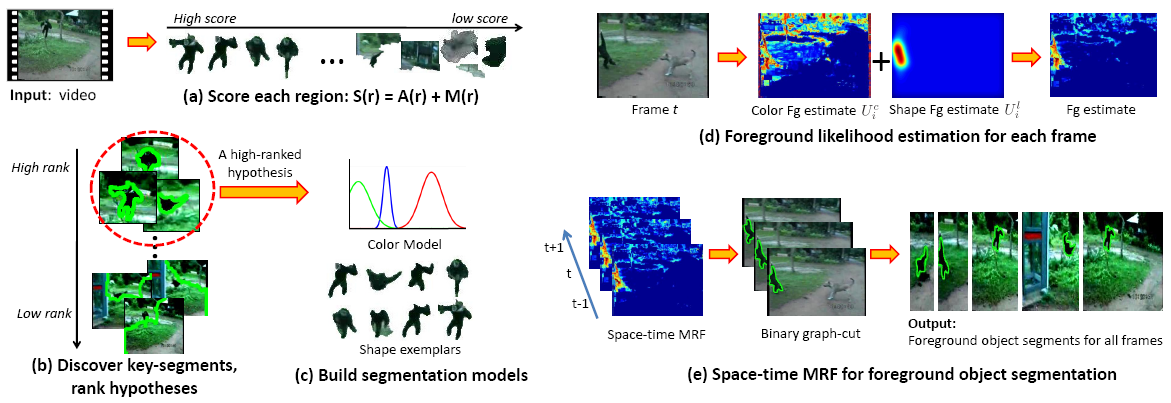
Algorithm
Overview. See ordered steps (a) through (e).
(a) To find
“object-like” regions among the proposals, we look for
regions that have (1) appearance cues typical to objects in
general, and (2) differences in motion patterns relative to
their surroundings. We define a function S(r) = A(r) +M(r), that
scores a region r
according to its static intra-frame appearance score A(r) and dynamic
inter-frame motion score M(r).
(b) Given the scored regions, we next
identify groups of key-segments that may represent a
foreground object in the video. We perform a form of
spectral clustering with the highest scored regions as input
to produce multiple binary inlier/outlier partitions of the
data. Each cluster (inlier set) is a hypothesis h of a foreground
object’s key-segments. We automatically rank the
clusters based on the average object-like score S(r) of its member
regions. If that scoring is successful, the clusters
among the highest ranks will correspond to the primary
foreground object(s), since they are likely to contain
frequently appearing object-like regions.
(c) We build
foreground and background color Gaussian Mixture Models and
extract a set of shape exemplars for each hypothesis.
(d) We next devise a
space-time Markov Random Field (MRF) that uses these
models to guide a pixel-wise segmentation for the entire
video. We compute color fg/bg estimates using the
GMMs, and estimate fg location priors with the shape
exemplars. The main idea is to use the key-segments
detected across the sequence, projecting their shapes into
other frames via local shape matching. The spatial
extent of that projected shape then serves as a location
and scale prior in which we prefer to label pixels as
foreground. Since we have multiple key-segments and many
possible local shape matches, many such projected shapes
are aggregated together, essentially “voting” for the
location/scale likelihoods.
(e) We compute
the foreground object segmentation by minimizing the energy
function for the space-time MRF using graph cuts.
Results
The main questions in our experiments are (1) to what extent are object-like regions better identified by using motion cues unique to video, (2) how well does our method rank each hypothesis, and (3) how accurate is our method’s foreground object segmentation?
We test on two datasets: SegTrack and [Grundmann et al., 2010], eight videos in total.


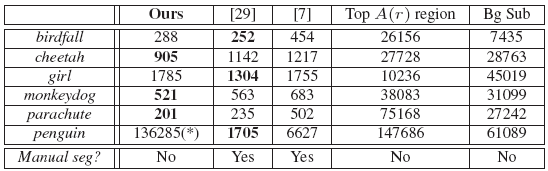
Our unsupervised method produces state-of-the-art results even when compared to supervised methods ([29]: Tsai et al., 2010; [7]: Chockalingham et al., 2009).
The table above shows the average number of incorrect pixels per frame. Lower numbers are better.
Publication
Key-Segments for Video Object Segmentation [pdf] [code] [data] [poster] [video results]
Yong Jae Lee, Jaechul Kim, and Kristen Grauman
In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, November 2011.