|
Sudheendra Vijayanarasimhan and Kristen Grauman
Department of Computer Sciences,
University of Texas at Austin
|
Carefully prepared labeled datasets are useful for learning visual category models, but they are expensive to obtain. On the other hand, images on the Web indexed using keywords are available in large quantities, but do not necessarily portray the query term and are much more variable than typical benchmark training sets. How can we learn reliable category models from images returned by keyword search?
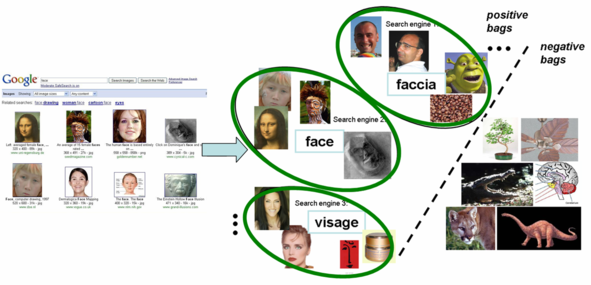
Given just the names of the categories, we directly obtain discriminative models by considering the problem in a multiple-instance visual category learning scenario.
Multiple Instance Learning (MIL) considers a particular form of weak supervision where the classifier is given positive bags, which are sets of instances containing at least one positive example and negative bags, which are sets containing no positive examples.
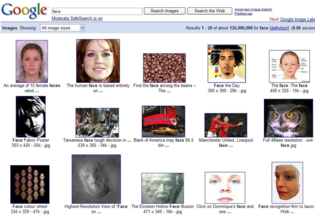
A single search for a keyword of interest yields a collection of images within which (we assume) at least one image depicts that object, thus comprising a positive bag. This enables us to pose the problem of learning classifiers from web searches as a multiple-instance learning problem.
On average 30% of the images returned by Google for a small set of categories contain a ``good'' view of the class of interest, 20% are of ``ok'' quality and 50% are completely unrelated ``junk'' (as judged in [Fergus et al. 2005]). By explicitly accounting for the fact that there could be as little as one good example in the set of returned images we are able to deal with the large amount of noise in the training data.
|
|
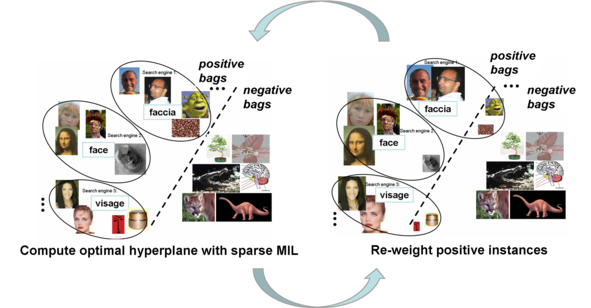
The main steps of the algorithm are summarized as follows
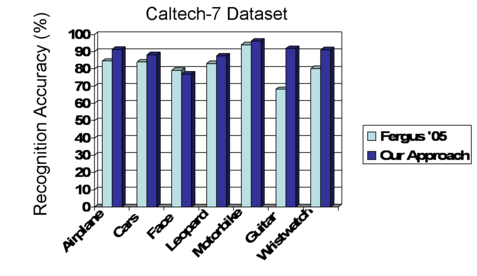
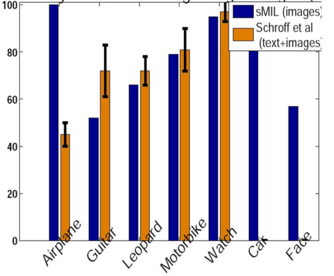
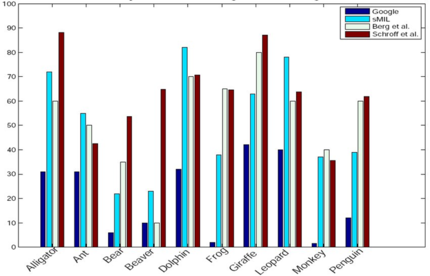
We evaluate our method for two kinds of tasks: categorizing novel examples, and re-ranking keyword search returns according to predicted relevance on the publicly available Google dataset ([Fergus et al. 2005]) and the Animals dataset ([Berg et al. 2005]). We download training examples for each category name using Google Image Search, Yahoo, and MSN, in five languages and represent images with bags of local SIFT features from four interest operators (Harris-Affine, DoG, edges, Kadir & Brady), and use an RBF kernel.
|
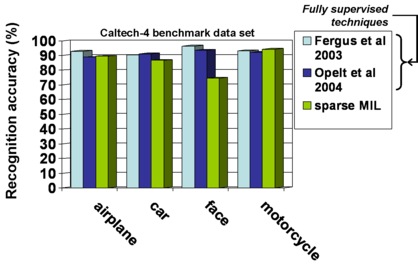
Our results improve the state-of-the-art in unsupervised recognition, and are even competitive with fully supervised techniques.
|
Using image content alone, our approach provides accurate re-ranking results, and for some classes improves precision more than methods employing both text and image features.
In comparison to previous approaches that deal with the problem of learning from web search returns ([Fergus et al. 2005, Berg et al. 2005, Schroff et al.]) we use image features alone and directly obtain discriminative classifiers by explicitly accounting for the noise in the search returns.
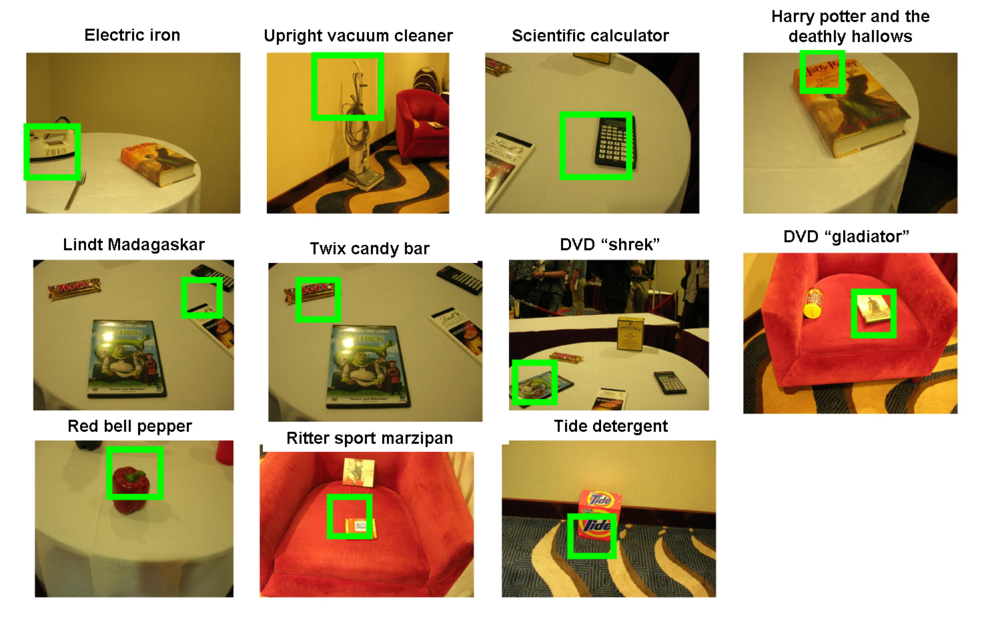
The Semantic Robot Vision Challenge (SRVC) is a workshop conducted every year where fully autonomous robots receive a text list of objects that they are to find. They use the web to automatically find image examples of those objects in order to learn visual models. These visual models are then used to identify the objects in the robot's cameras.
We applied our Multiple-Instance Learning based approach in the 2008 version of the competition. The text list contained about 20 objects with an equal mix of specific objects such as DVD ``300'' and object categories like ``fax machine''.
We automatically downloaded web images from multiple search engines and used our approach to build classifiers for all 20 objects setting the parameters automatically. To localize objects in the test images we used the sliding window approach and returned the bounding box that obtained the largest response from the classifiers. Following are the results on the challenge
 |
Following are results from the practice round that was run by the organizers under the same settings as the final round with a different set of objects.
Finally, these are results on the qualification round,
In addition to specific objects, which have little variation in their appearance, our method was able to find a large number of generic objects such as ``electric iron'', ``vacuum cleaner'', ``calculator'', ``brown pen'', ``apple'', etc. despite the noisy data used to train the classifiers.
Keywords to Visual Categories: Multiple-Instance Learning for Weakly Supervised Object Categorization,
Sudheendra Vijayanarasimhan and Kristen Grauman, In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2008. CVPR 2008.
[paper][poster] [code, readme]