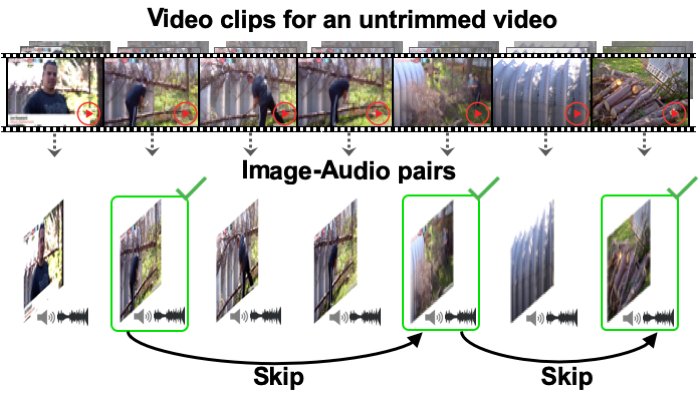
In the face of the video data deluge, today's expensive clip-level classifiers are increasingly impractical. We propose a framework for efficient action recognition in untrimmed video that uses audio as a preview mechanism to eliminate both short-term and long-term visual redundancies. First, we devise an ImgAud2Vid framework that hallucinates clip-level features by distilling from lighter modalities—a single frame and its accompanying audio—reducing short-term temporal redundancy for efficient clip-level recognition. Second, building on ImgAud2Vid, we further propose ImgAud-Skimming, an attention-based long short-term memory network that iteratively selects useful moments in untrimmed videos, reducing long-term temporal redundancy for efficient video-level recognition. Extensive experiments on four action recognition datasets demonstrate that our method achieves the state-of-the-art in terms of both recognition accuracy and speed.
†On leave from The University of Texas at Austin.