Clues
from the Beaten Path:
Location Estimation with Bursty Sequences of
Tourist Photos
Chao-Yeh Chen and
Kristen Grauman
The University of Texas at Austin
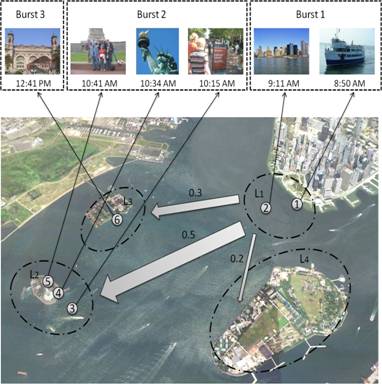
We propose to
exploit the travel patterns among tourists within a city to improve location recognition
for new sequences of photos. Our HMM-based model treats each temporal cluster
(“burst”) of photos from the same camera as a single observation, and computes
a set-to-set matching likelihood function to determine visual agreement with
each geospatial location. Both the learned transition probabilities between
locations and this grouping into bursts yield more accurate location estimates,
even when faced with non-distinct snapshots. For example, the model benefits
from knowing that people travel from L1 to L2 more often than L3 or L4, and can
accurately label all the photos within Burst 2 even though only one (the Statue
of Liberty) may match well with some labeled instance.
Motivation - where
did I take these pictures?

(1)
For image with distinct features, we could recognize
its location by the nearest neighbor method.

(2)
If we know three pictures are taken within a short time,
we assume they are coming from one place. Thus we can estimate the location of
the “burst” rather than the location of each image.
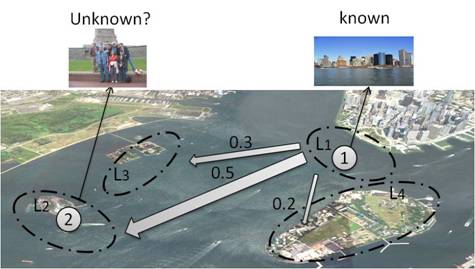
(3)
For successive images, if we know the location of
previous one, we exploit the
learned tourists' travel patterns in order to better infer the labels for the
entire sequence of test photos.
Abstract
Existing methods for image-based location estimation generally attempt
to recognize every photo independently, and their resulting reliance on strong
visual feature matches makes them most suited for distinctive landmark scenes.
We observe that when touring a city, people tend to follow common travel
patterns—for example, a stroll down Wall Street might be followed by a ferry
ride, then a visit to the Statue of Liberty or Ellis Island museum. We propose
an approach that learns these trends directly from online image data, and then
leverages them within a Hidden Markov Model to robustly estimate locations for
novel sequences of tourist photos. We further devise a set-to-set
matching-based likelihood that treats each “burst” of photos from the same
camera as a single observation, thereby better accommodating images that may
not contain particularly distinctive scenes. Our experiments with two large
datasets of major tourist cities clearly demonstrate the approach’s advantages
over traditional methods that recognize each photo individually, as well as a
naive HMM baseline that lacks the proposed burst-based observation model.
Approach
Training stage
(1)
Discovering a city’s locations
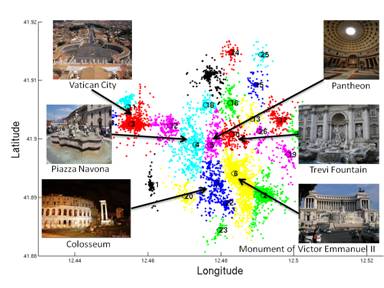
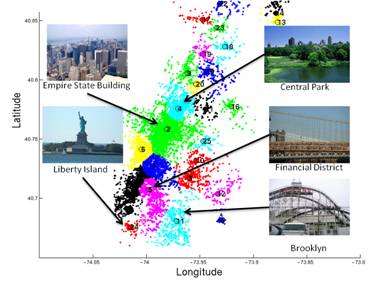
We define the location by applying mean-shift clustering to the GPS
labels of the training images. These two figures depict the defined location
for our two datasets
(2)
Feature extraction
For every image, extracts three visual
features: Gist, a color histogram, and a bag of visual words. Gist captures the
global scene layout and texture. Color histogram characterizes certain scene
regions such as green plants in a park. The bag-of-words descriptor captures
the appearance of component objects.
(3)
Location summarization
As for certain popular locations contain many more images than others,
the non-distinct images can bias the observation likelihood. For example if 5%
of the training images contain a car, then the most popular locations will
likely contain quite a few images of cars. At test time, any image containing a
car could have a strong match to them, even though it may not truly be a
characteristic of the location. In order to automatically select the most
important aspects of the location with minimal redundancy, we apply the
efficient spherical k-centroids algorithm to each
location’s training images when the distribution of images among locations is
highly unbalanced.
(4)
Learning the Hidden Markov model
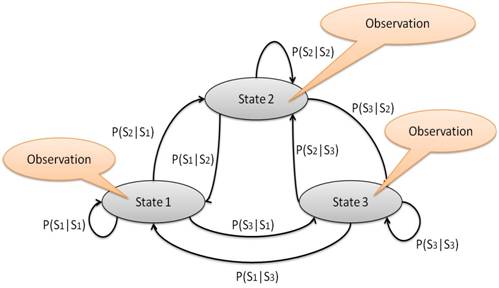
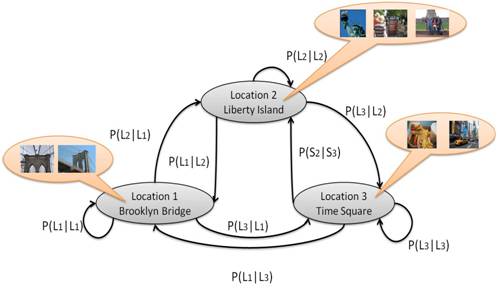
To train the HMM, we
learn the initial state priors and state transition
probabilities from the traveling image sequences from training data. These two
figures show the relation between HMM and our location estimation problem.
Testing stage
(1)
Grouping photos into bursts

We apply Mean shift on the timestamps to compute the
bursts. A burst is meant to capture a small event during traveling. When
inferring the labels for a novel sequence, we assume that all photos in a
single burst have the same location label.
(2)
Location Estimation via HMM
As in the testing stage, our goal is to estimate
the most likely series of locations. The initial state priors and state transition
probabilities have been learned from training.
Here we define the observation likelihood
distribution as:
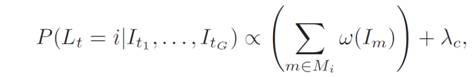
where
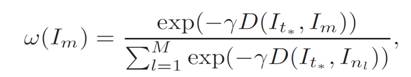
then by Bayes Rule, we have
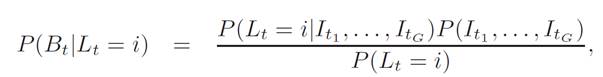
The distance D(It , Im) defines the visual feature similarity between two
images. ![]() is the
regularization constant and
is the
regularization constant and ![]() is the scaling parameter.
is the scaling parameter.
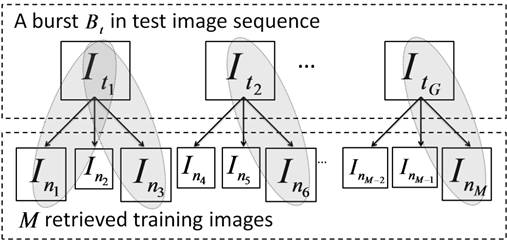
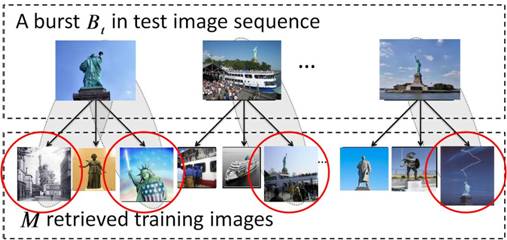
Given a burst Bt that
contains G images, say we retrieve K = 3 neighbors for each test image, giving
3×G retrieved training images. Among them, image 1, 3, 6, and M are from L1,
which means that, M1 = {In1 , In3 , In6 , InM}. Thus,
numerator of ω(Im) is affected
by the four pairs in the grey circle from the left figure. For example, given the
burst in the right figure, among all the retrieved training images, the four
images inside red circle are coming from location M1. Then the
similarity between these four images and their query image determines the
observation likelihood of this burst to M1.
Comparison with other methods
The authors of [1] develop an HMM-model
parameterized by time intervals to predict locations for photo sequences taken
along transcontinental trips. Their work also exploits human travel patterns,
but at a much coarser scale: the world is binned into 3,186 400 km2 bins, and
transitions and test-time predictions are made among only these locations. A
further distinction is our proposed burst based set-to-set observation
likelihood. We show our burst based method (Burst-HMM) outperforms image based
likelihood method (Int-HMM) in the result part.
The authors of [2] consider location
recognition as a multi-class recognition task, and the five images before and
after the test image serve as temporal context within a structured SVM model.
This strategy is likely to have similar label smoothing effects as our method’s
initial burst grouping stage, but does not leverage statistics of travel
patterns.
[1] E. Kalogerakis, O. Vesselova, J.
Hays, A. Efros, and A. Hertzmann. Image sequence geolocation with human
travel priors. In ICCV, 2009.
[2] Y. Li, D. J.
Crandall, and D. P. Huttenlocher. Landmark
classification in large-scale image collections. In ICCV,
2009.
Results
We test our method on two datasets: Rome and
New York. Our experiments demonstrate the approach with real user-supplied photos
downloaded from the Web. We make direct comparisons with four key baselines,
and analyze the impact of various components.
(1)
Properties of two
datasets:
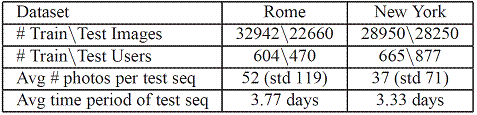
Mean shift on the training data discovers 26
locations of interest for Rome, and 25 for New York. The average location size
is 0.2 mi^2 in Rome, and 3 mi^2 in New York. The ground truth location for each
test image is determined by the training image it is nearest to in
geo-coordinates.
(2)
Location
estimation accuracy:
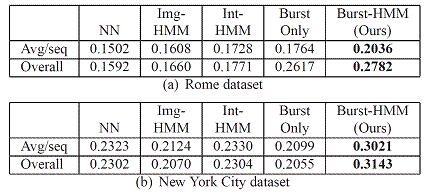
NN = nearest
neighbor method, Img-HMM = image-to-image HMM, Int-HMM =
image to image HMM incorporating length of interval between consecutive images
(used in [1]), Burst Only = uses the
same bursts as computed for our method, but lacks the travel transitions and
priors, Burst-HMM = our method. Avg/seq is the average rate of
correct predictions across the test sequences and Overall is the the correct rate across all test images.
(3)
Qualitative
results:
We show four example results comparing
predictions by our Burst-HMM (“Ours”) and the Img-HMM
baseline (“Base”). Images in the same cell are from the same burst. A check
means correct prediction, an ‘x’ means incorrect.

Two traveling sequences from the New York dataset. In the first sequence, images with distinct features,
such as Images 2-5, and 16-17, are predicted correctly by both methods. While
the baseline fails for less distinctive scenes (e.g., Image 8-14), our method
estimates them correctly, likely by exploiting both informative matches to
another view within the burst (e.g., the landmark building in Image 8 or 13),
as well as the transitions from burst to burst. Our method can also fail if a
burst consists of only non-distinctive images (Image 1). In the second
sequence, our method locate image 9-12 correctly by leveraging strong cues from
image 13 and 14.

Two traveling sequences
from the Rome dataset. In the first sequence, for the images within
the red rectangular, our method correctly locates image 5 to image 14 due to
the strong hints in image 3, 4, and 17, while the baseline fails due to the
lack of temporal constraints and distinctive features. In the second sequence,
our method predicts image 7 to image 10 correctly by the strong hints in image
5 and 6.
Dataset
Poster
Publication
Clues from the
Beaten Path: Location Estimation with Bursty Sequences of Tourist Photos [ pdf ]
Chao-Yeh Chen and
Kristen Grauman
To appear, In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Colorado Springs, CO, June 2011.