Efficient
Activity Detection with Max-Subgraph Search
Chao-Yeh Chen and
Kristen Grauman
The University of Texas at Austin
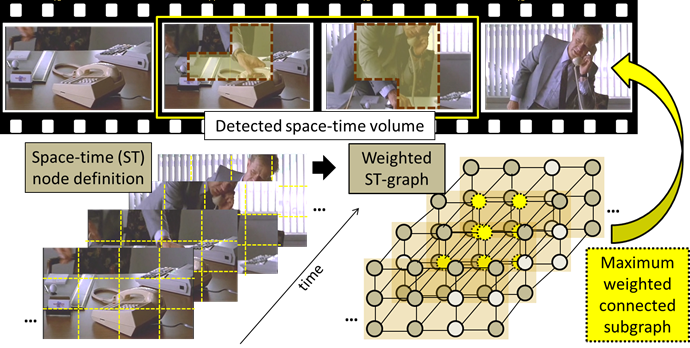
We
propose an efficient approach that unifies activity categorization with
space-time localization. The main idea is to pose activity detection as a
maximum-weight connected subgraph problem over a
learned space-time graph constructed on the test sequence. We show this permits an efficient branch-and-cut
solution for the best-scoring—and possibly non-cubically shaped—portion of the
video for a given activity classifier.
The upshot is a fast method that can evaluate a broader space of candidates
than was previously practical, which we find often leads to more accurate
detection. We demonstrate the proposed algorithm on three datasets, and show
its speed and accuracy advantages over multiple existing search strategies.
Problem: how to detect human activity
in continuous video?
Status
quo approaches:
- Expensive: sliding window search.
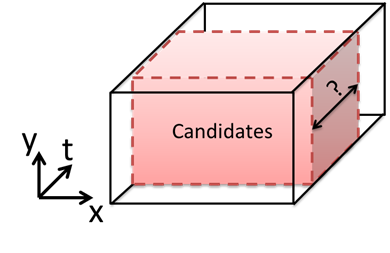
- Restricted
shapes: only allows cuboid shape detection.

- Lack
context: detection through tracking humans.
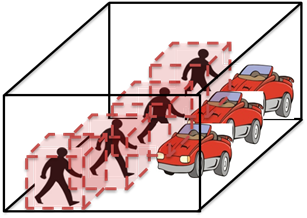
Our Idea:
Pose activity detection as a maximum-weight
connected subgraph problem over a learned
space-time graph.
Highlights:
- Obtain exhaustive sliding window search result with much less time.
- Widen search scope to “non-cubic”
detection volumes.
- Incorporate top-down knowledge of
interactions of people/objects.
Approach
Overview
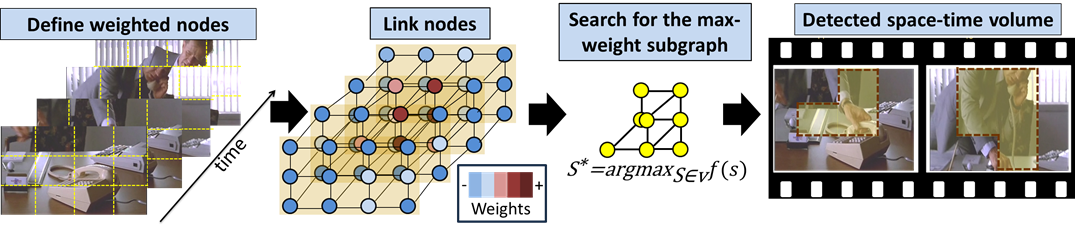
(1)
Define weighted nodes
Background: classifier
training for feature weights:
- Activity detection = determine the subvolume S in a video
sequence Q that maximizes the score S*:
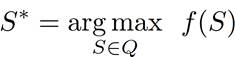
- Learn a linear SVM from training data, the
scoring function would have the form:
![]()
where h is the
histogram of quantized features (BoF), (![]() ) are the learned
weights/bias, i indexes the training examples.
) are the learned
weights/bias, i indexes the training examples.
- We define ![]() = jth bin count for histogram
= jth bin count for histogram ![]() , the jth word is associated with a weight
, the jth word is associated with a weight
![]()
for
j = 1,…,K, where K is the dimension of histogram h.
- Thus the classifier
response for subvolume S is:
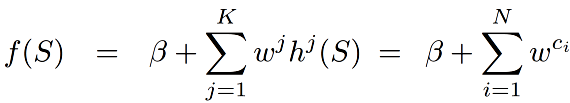
where ci ∈[1,K],
which is the sum of weights from the
features inside the subvolume S.
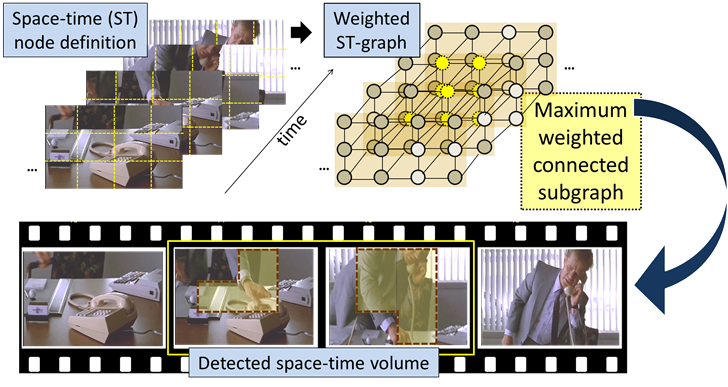
Define weighted nodes:
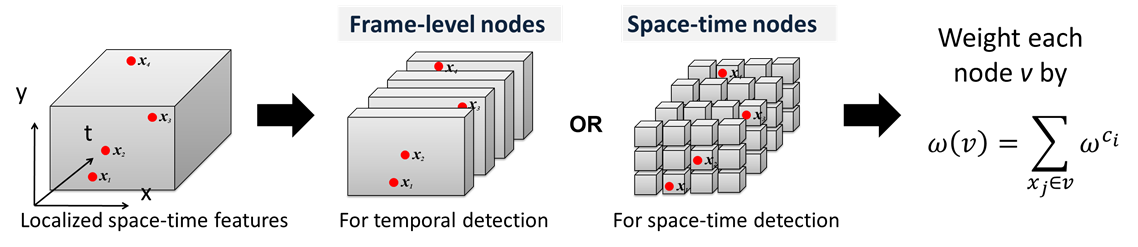
Divide space-time volume into frame-level/space-time nodes. Compute the weight
of nodes from the features inside them.
(2)
Link nodes

Two different link strategies:
1.
Neighbors only for frame-level nodes(T-Subgraph)
or space-time nodes(ST-Subgraph).
2.
First two neighbors for frame-level nodes(T-Jump-Subgraph).
(3)
Search for the maximum-weight graph
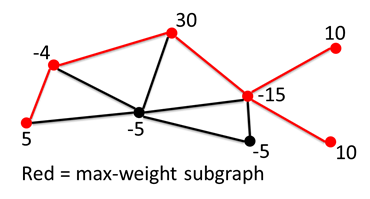
- Transform max-weight subgraph
problem into a prize-collecting Steiner tree problem.
- Solve efficiently with branch and cut
method from [Ljubic et al. 2006].
For
example, the solution of T-Subgraph is (4+2) the
solution of T-Jump-Subgraph is (4+2+5).
(4)
Back project the selected nodes for the detection
result.

Localized Space-Time Features
- Low-level feature: Histograms of oriented gradients (HoG) +
histograms of optical flow (HoF) at interest
points/densely sampled.
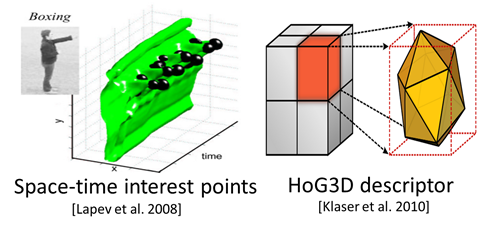
- High-level feature: three steps to
formulate a descriptor
a.
Detect objects and people from frames using
object/pose detector. Cluster poses into N(~10) person types.
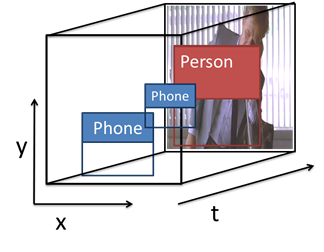
b.
For each detection, build a semantic descriptor
based on it’s spatial/temporal neighbors.
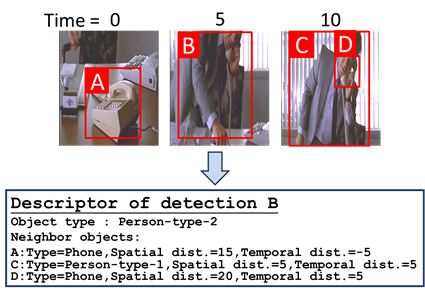
c.
Quantize the semantic descriptor into words via
random forest.
Results
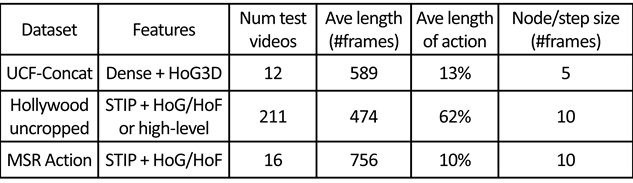
Properties of three datasets
Evaluation metrics
- mean overlap accuracy: ![]()
- detection
time: Second
Temporal
detection on UCF Concatenated/Hollywood uncropped/MSR
Action
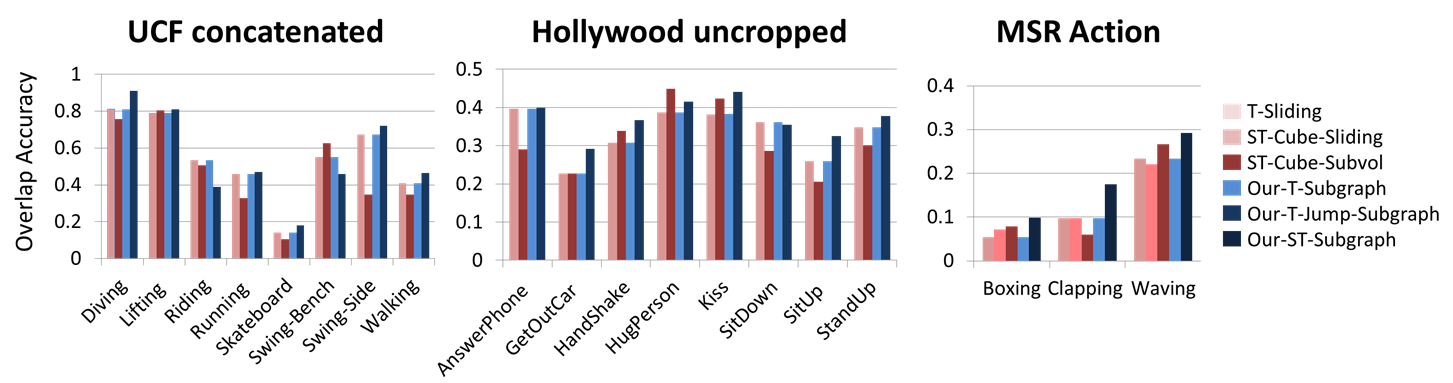
- Our T-Jump
gives top accuracy for UCF and Hollywood,
showing the advantage of ignoring noisy features.
- Our ST-Subgraph
is most accurate in MSR since it can isolate those nodes that participate in
the action.
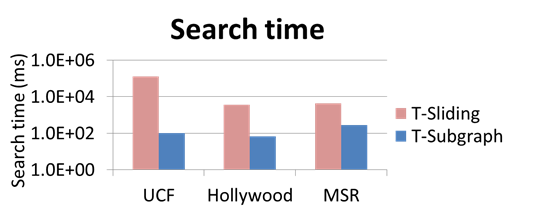
- Our T-Subgraph is orders
of mag. faster than T-Sliding.
Temporal/Space-time detection on MSR Actions
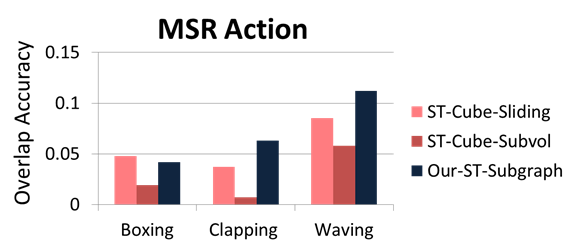
- Our ST-Subgraph is also
most accurate in terms of space-time overlap accuracy.

-
Top row: yellow box à the space time
detection from our ST-Subgraph. Note the detection
changes with time. Red boxes: ground truth annotation.
-
Bottom row: green box àtop four detections from
the ST-Cube-Subvolume. The top three detections are
trapped by the local maximum caused by the small motion of human.
Trade-offs in results
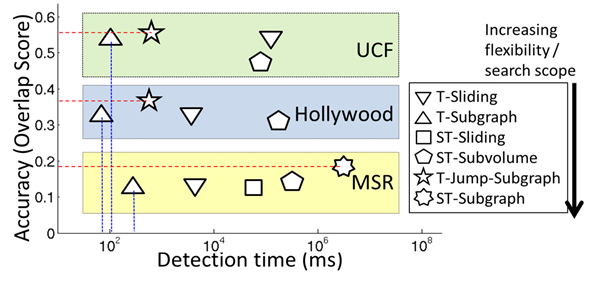
-
Increased search scope boosts accuracy, though
costs more.
-
Flexibility of proposed method allows the best
speed/accuracy.
Subgraph search with high-level
features

- Qualitative detection result from our high-level features. Note that the red
boxes are the space-time detection output, not annotation or human detection
result.
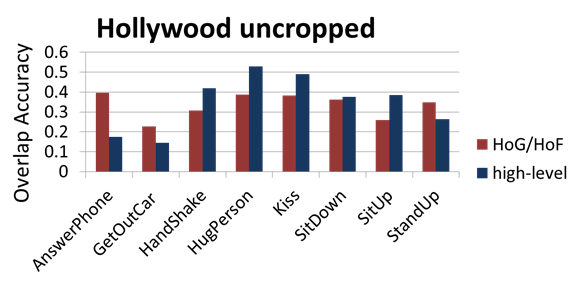
- Our high-level features obtain higher
accuracy in 5 out of 8 categories in Hollywood uncropped
dataset.
Conclusion
- Reduced computation
time for detection vs. sliding window search.
- Flexible
node structure offers more robust detection in noisy backgrounds.
- High-level
descriptor shows promise for complex activities by incorporating semantic
relationships between humans and objects in video.