
Given a large collection of unlabeled videos, we focus on learning representations for object-like regions. Our key idea is to learn a feature space where representations of object-like regions in video vary slowly over time. Intuitively, this property induces invariances (such as to pose, lighting etc.) in the feature space that are useful for high-level tasks. As shown in the figure above, we observe that objects in images vary slowly over time, so that correct region proposals in one frame tend to have corresponding proposals in adjacent frames. Conversely, region proposals that are spatio-temporally adjacent usually correspond to the same object or object part. Based on this observation, we train deep neural networks to learn feature spaces where spatio-temporally adjacent region proposals in video are embedded close to each other.

Why might our object-centric approach have an advantage? Most prior work produces a holistic image embedding, and attempts to learn feature representations for video frames as a whole. Two temporally close video frames, although similar, usually have multiple layers of changes across different regions of the frames. This may confuse the deep neural network, which tries to learn good feature representations and embed these two frames in the deep feature space as a whole. An alternative is to track local patches and learn a localized representation based on the tracked patches, but tracking is biased towards moving objects, which may limit the invariances that are possible to learn. Furthermore, processing massive unlabeled video collections with tracking algorithms is computationally intensive, and errors in tracking may influence the quality of the patches used for learning. Our object-centric approach has several advantages. First, unlike patches found with tracking, patches generated by region proposals can capture static objects as well as moving objects (see figure above). Static objects are also informative in the sense that, beyond object motion, there might be other slight changes such as illumination changes or camera viewpoint changes across video frames. Therefore, static objects should not be neglected in the learning process. Secondly, our framework can also help capture the object-level regions of interest in cases where there is motion only on a part of the object (e.g., the cat is moving its paw but otherwise staying similarly posed). Thirdly, our method is much more efficient to generate training samples since no tracking is needed (>100 times faster than tracking algorithms).
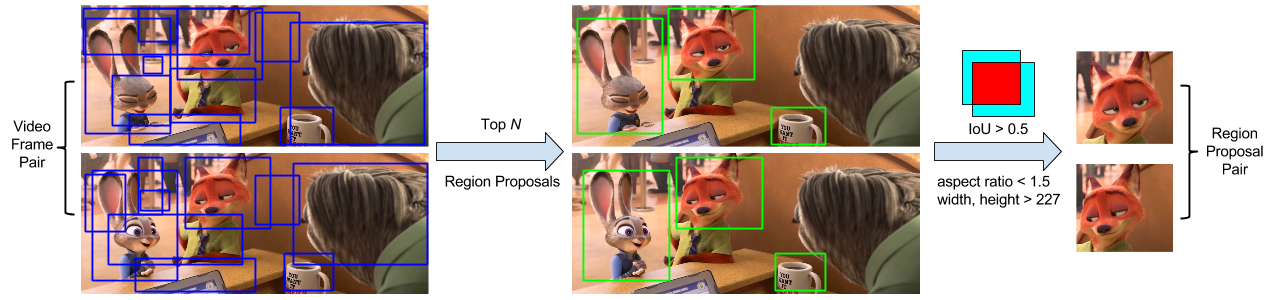
We use Selective Search to generate hundreds of region proposals from each frame, and use our well-designed filtering process (shown above) to guarantee the quality, congruity, and diversity of generated region proposal pairs. Compared to the alternative whole-frame and tracking-based paradigms, our idea shows consistent advantages on three challenging datasets (MIT Indoor 67, PASCAL 2007 and 2012). It often outperforms an array of state-of-the-art unsupervised feature learning methods for image classification and retrieval tasks. In particular, we observe relative gains of 10 to 30% in most cases compared to existing pre-trained models. Overall, our simple but effective approach is an encouraging new path to explore learning from unlabeled video.