Object-Graphs for Context-Aware Category Discovery
Yong Jae Lee and
Kristen Grauman
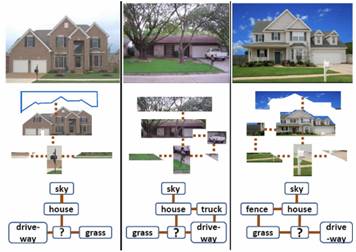
Summary
How
can knowing about some categories help us to discover new ones in unlabeled
images? Unsupervised visual category
discovery is useful to mine for recurring objects without human supervision,
but existing methods assume no prior information and thus tend to perform
poorly for cluttered scenes with multiple objects. We propose to leverage knowledge about
previously learned categories to enable more accurate discovery. We introduce a novel object-graph descriptor
to encode the layout of object-level co-occurrence patterns relative to an
unfamiliar region, and show that by using it to model the interaction between
an image's known and unknown objects we can better detect new visual
categories. Rather than mine for all
categories from scratch, our method identifies new objects while drawing on useful
cues from familiar ones. We evaluate our
approach on benchmark datasets and demonstrate clear improvements in discovery
over conventional purely appearance-based baselines.
Approach
There
are three main steps to our approach:
(1) Detecting instances
of known objects in each image while isolating regions that are likely to be
unknown.
(2) Extracting object-level
context descriptions for the unknown regions.
(3) Clustering the
unfamiliar regions based on these cues.
Identifying Unknown
Objects
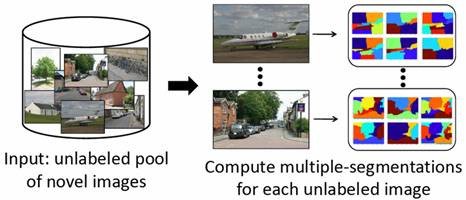
We first
train region-based classifiers for N
“known” categories using labeled training data.
Then, given an unlabeled pool of novel images, we compute
multiple-segmentations for each unlabeled image to produce regions that
(likely) correspond to coherent objects.
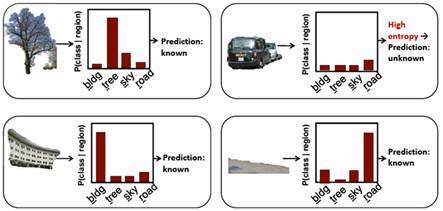
For each region, we use the classifiers to compute posterior
probabilities for the N known
categories. We deem each region as known
or unknown based on the resulting entropy.
Object-Graphs: Modeling
the Topology of Category Predictions
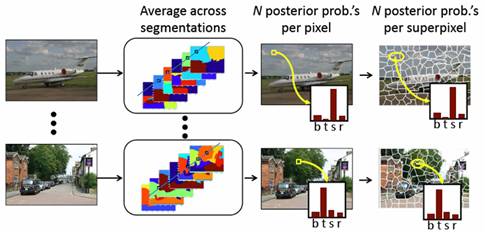
We obtain
per-superpixel posterior probabilities for each image
by first averaging the region-posteriors across multiple-segmentations to
obtain per-pixel posteriors, and then averaging the posteriors within each superpixel.
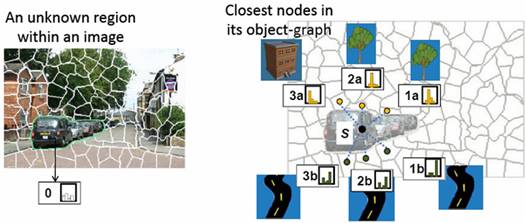
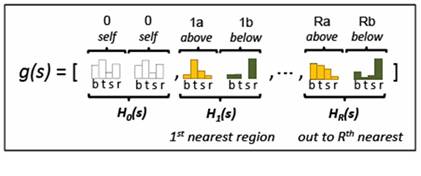
Given
an unknown region, s, we model the topology
of the category predictions above and below the region. We incorporate the uncertainty from the
classifiers by encoding the posterior probabilities of the surrounding regions
as feature histograms in increasingly further spatial extents. We look at the R nearest superpixels in both
orientations, and concatenate the resulting histograms to create our final
descriptor. The object-graph descriptor
serves as a soft encoding of the likely categories that occur near the unknown
region from near and far, at two orientations.
Category Discovery Amidst Familiar Objects
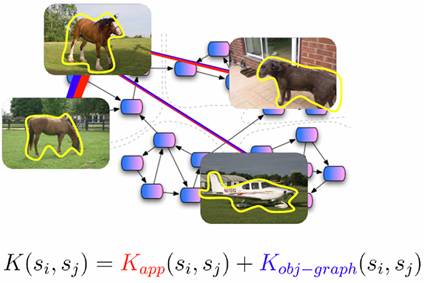
We define
a similarity function between two regions that include both the
region-appearance and known-object context.
We compute affinities between all unknown regions to generate an
affinity matrix which is input to a spectral clustering algorithm to discover
categories.
Results
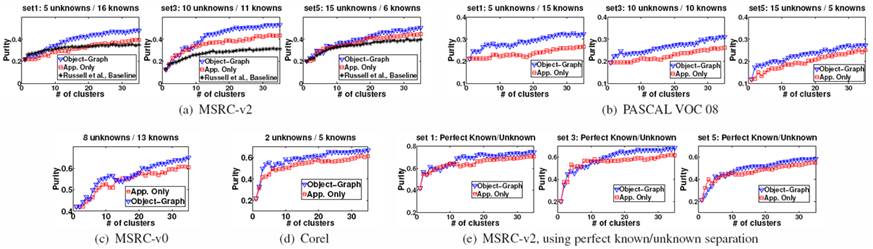
We tested
our method on four datasets: MSRC-v2, MSRC-v0, Pascal VOC 2008, and Corel. We generated random splits of known/unknown
categories. The above figure shows
cluster purity as a function of the number of clusters. We compare our method to an appearance-only
baseline that only uses region appearance to group the regions, and to the LDA
based method of Russell et al. Our
method outperforms both baselines.

The
figure above shows examples of discovered categories. Our clusters tend to be more inclusive of
intra-class appearance variations than those that could be found with appearance
alone. For example, note the presence of
both side views and rear views in the car cluster, and distinct types of
windows that get grouped together.
Publication
Object-Graphs for
Context-Aware Category Discovery [pdf]
[supp]
[code]
[data]
Yong Jae Lee and Kristen Grauman
In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA,
June 2010.