Pixel Objectness
Suyog Jain
Bo Xiong
Kristen Grauman
PAPER DEMO CODE CONTACT BIBTEX FUSIONSEG
We propose an end-to-end learning framework for foreground object segmentation. Given a single novel image, our approach produces a pixel-level mask for all "object-like" regions---even for object categories never seen during training. We formulate the task as a structured prediction problem of assigning a foreground/background label to each pixel, implemented using a deep fully convolutional network. Key to our idea is training with a mix of image-level object category examples together with relatively few images with boundary-level annotations. Our method substantially improves the state-of-the-art on foreground segmentation on the ImageNet and MIT Object Discovery datasets---with 19% absolute improvements in some cases. Furthermore, on over 1 million images, we show it generalizes well to segment object categories unseen in the foreground maps used for training. Finally, we demonstrate how our approach benefits image retrieval and image retargeting, both of which flourish when given our high-quality foreground maps.
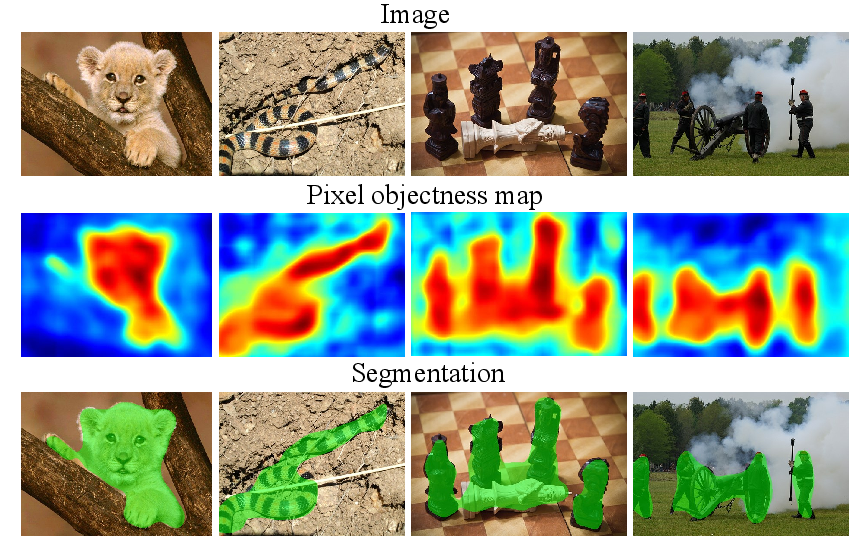
Our goal is to predict an objectness map for each pixel (2nd row) and a single foreground segmentation (3rd row). Left to right: Our method can accurately handle objects with occlusion, thin objects with similar colors to background, man-made objects, and multiple objects. Our approach is class-independent, meaning it is not trained to detect the particular objects in the images.









