| Changan Chen1,2, Ziad Al-Halah1, Kristen Grauman1,2 |
|
1UT Austin,2Facebook AI Research Accepted at CVPR 2021 |
|
|
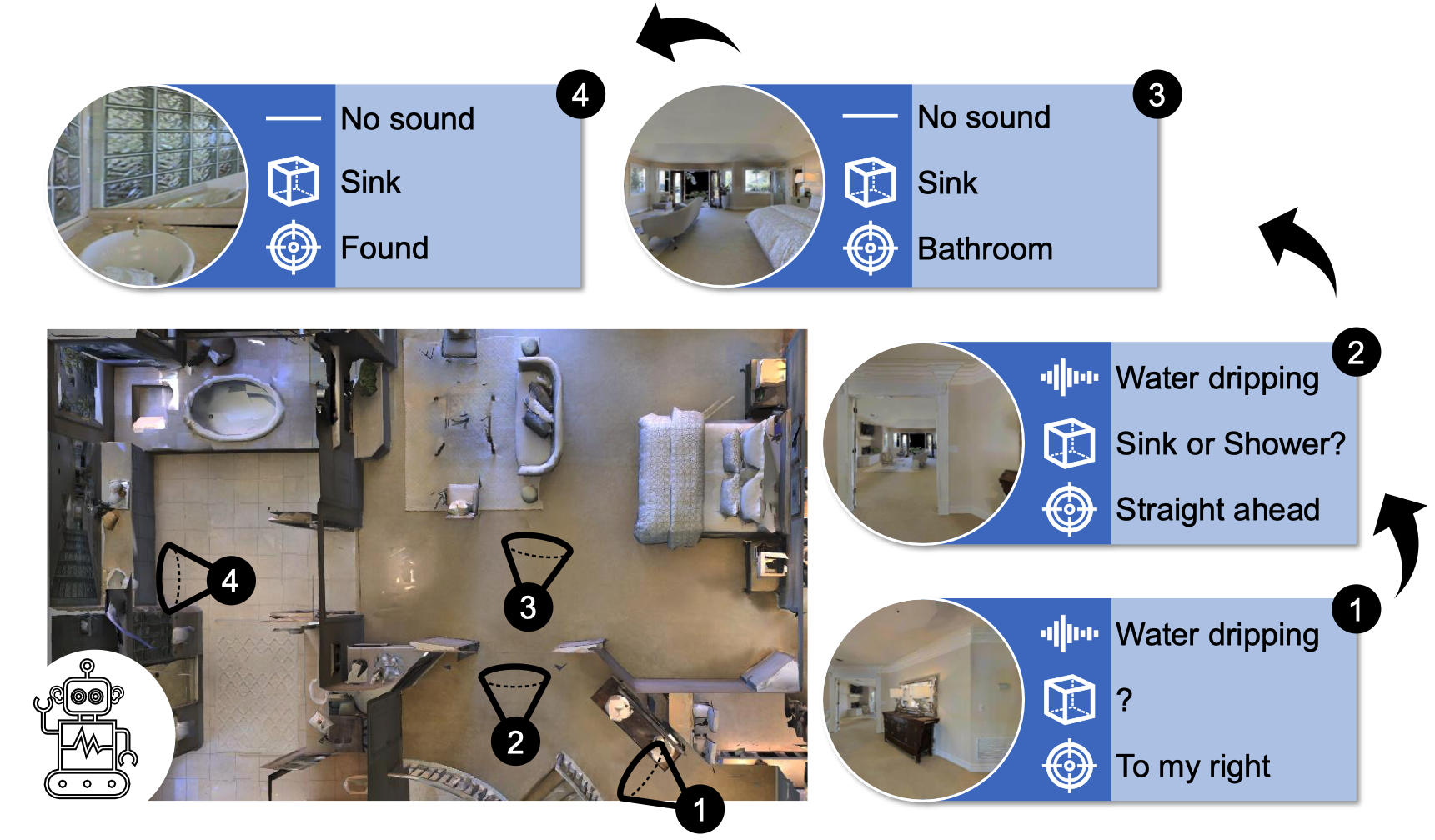
| Recent work on audio-visual navigation assumes a constantly-sounding target and restricts the role of audio to signaling the target's spatial placement. We introduce semantic audio-visual navigation, where objects in the environment make sounds consistent with their semantic meanings (e.g., toilet flushing, door creaking) and acoustic envents are sporadic or short in duration. We propose a transformer-based model to tackle this new semantic AudioGoal task, incorporating an inferred goal descriptor that captures both spatial and semantic properties of the target. Our model's persistent multimodal memory enables it to reach the goal even long after the acoustic event stops. In support of the new task, we also expand the SoundSpaces audio simulation platform to provide semantically grounded object sounds for an array of objects in Matterport3D. Our method strongly outperforms existing audio-visual navigation methods by learning to associate semantic, acoustic, and visual cues. |
|
Simulator demos and some navigation examples.
|
|
|
| (1) Changan Chen*, Unnat Jain*, Carl Schissler, Sebastia Vicenc Amengual Gari, Ziad Al-Halah, Vamsi Krishna Ithapu, Philip Robinson, Kristen Grauman. SoundSpaces: Audio-Visual Navigation in 3D Environments. In ECCV 2020 [Bibtex] |
| (2) Ruohan Gao, Changan Chen, Carl Schissler, Ziad Al-Halah, Kristen Grauman. VisualEchoes: Spatial Image Representation Learning through Echolocation. In ECCV 2020 [Bibtex] |
| (3) Changan Chen, Sagnik Majumder, Ziad Al-Halah, Ruohan Gao, Santhosh Kumar Ramakrishnan, Kristen Grauman. Learning to Set Waypoints for Audio-Visual Navigation. In ICLR 2021 [Bibtex] |
| UT Austin is supported in part by DARPA Lifelong Learning Machines. |
| Copyright © 2020 University of Texas at Austin |