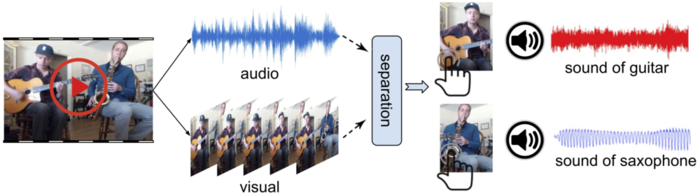
Perceiving a scene most fully requires all the senses. Yet modeling how objects look and sound is challenging: most natural scenes and events contain multiple objects, and the audio track mixes all the sound sources together. We propose to learn audio-visual object models from unlabeled video, then exploit the visual context to perform audio source separation in novel videos. Our approach relies on a deep multi-instance multi-label learning framework to disentangle the audio frequency bases that map to individual visual objects, even without observing/hearing those objects in isolation. We show how the recovered disentangled bases can be used to guide audio source separation to obtain better-separated, object-level sounds. Our work is the first to learn audio source separation from large-scale “in the wild” videos containing multiple audio sources per video. We obtain state-of-the-art results on visually-aided audio source separation and audio denoising.
Qualitative Video
In the qualitative video, we show (a) example audio source separation results on novel "in the wild" videos; (b) example unlabeled videos and their discovered audio basis-object associations; (c) visually-assisted audio denoising results on three benchmark videos.
Here are some more results of applying our audio-visual sound source separation system on interesting YouTube videos with both animal and instrument.
Data
You can download AudioSet-SingleSource and AV-Bench using the links below:
AudioSet-SingleSourceA dataset of AudioSet videos from our val/test set containing only a single sounding object.
AV-BenchA dataset that contains the benchmark videos (Violin Yanni, Wooden Horse, and Guitar Solo) used in previous studies (Izadinia et al. 2013, Li et al. 2014, Pu et al. 2017).
Publication
R. Gao, R. Feris and K. Grauman. "Learning to Separate Object Sounds by Watching Unlabeled Video". In ECCV, 2018.[bibtex]
@inproceedings{gao2018object-sounds, title = {Learning to Separate Object Sounds by Watching Unlabeled Video}, author = {Gao, Ruohan and Feris, Rogerio and Grauman, Kristen}, booktitle = {ECCV}, year = {2018} }
Acknowledgement
This research was supported in part by an IBM Faculty Award, IBM Open Collaboration Research Award, and DARPA Lifelong Learning Machines. We also gratefully acknowledge a GPU donation from Facebook.