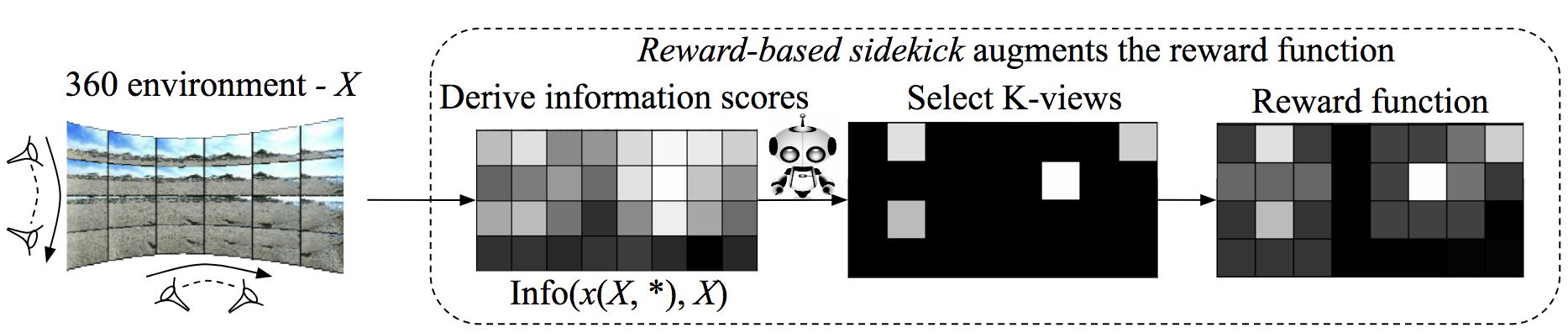
Reward-based sidekick
Demonstration-based sidekick
Santhosh K. Ramakrishnan1 Kristen Grauman2
1The University of Texas at Austin 2Facebook AI Research
ECCV 2018
We consider an active visual exploration scenario, where an agent must intelligently select its camera motions to efficiently reconstruct the full environment from only a limited set of narrow field-of-view glimpses. While the agent has full observability of the environment during training, it has only partial observability once deployed, being constrained by what portions it has seen and what camera motions are permissible. We introduce sidekick policy learning to capitalize on this imbalance of observability. The main idea is a preparatory learning phase that attempts simplified versions of the eventual exploration task, then guides the agent via reward shaping or initial policy supervision. To support interpretation of the resulting policies, we also develop a novel policy visualization technique. Results on active visual exploration tasks with 360 scenes and 3D objects show that sidekicks consistently improve performance and convergence rates over existing methods. Code, data and demos are available.
[code] [data] [models] [scores] [main pdf] [supp pdf] [arxiv]
The agent starts by looking at a novel environment (left) or object (right) from some unknown viewpoint. It has a budget T of time to explore the environment. The learning objective is to minimize the error in the agent’s pixelwise reconstruction of the full—mostly unobserved— environment using only the sequence of views selected within that budget. The agent does this by learning a policy to actively sample views that allows it to reconstruct the environment.
Sidekicks provide a preparatory learning phase that informs policy learning. Sidekicks have full observability during training: in particular, they can observe the results of arbitrary camera motions in arbitrary sequence. This is impossible for the actual look-around agent—who must enter novel environments and respect physical camera motion and budget constraints—but it is practical for the sidekick with fully observed training samples. Sidekicks exploit this full observability during training to accelerate and aid policy learning for the actual agent.
|
Reward-based sidekick
|
|---|
|
Demonstration-based sidekick |
@inproceedings{ramakrishnan-eccv2018,
author = {Ramakrishnan, Santhosh K. and Grauman, Kristen},
title = {{Sidekick Policy Learning for Active Visual Exploration}},
booktitle = {ECCV},
year = {2018}
}