Accounting for the Relative Importance of Objects
in Image Retrieval
Sung Ju Hwang and Kristen Grauman
The University of Texas at Austin
Abstract
We introduce a method for image retrieval that leverages the implicit information about object importance conveyed by the list of keyword tags a person supplies for an image. We propose an unsupervised learning procedure based on Kernel Canonical Correlation Analysis that discovers the relationship between how humans tag images (e.g., the order in which words are mentioned) and the relative importance of objects and their layout in the scene. Using this discovered connection, we show how to boost accuracy for novel queries, such that the search results may more closely match the user's mental image of the scene being sought. We evaluate our approach on two datasets, and show clear improvements over both an approach relying on image features alone, as well as a baseline that uses words and image features, but ignores the implied importance cues. Then we further apply our method to the images with natural language captions, and show similar substantial improvements over the both baselines.
1) Idea
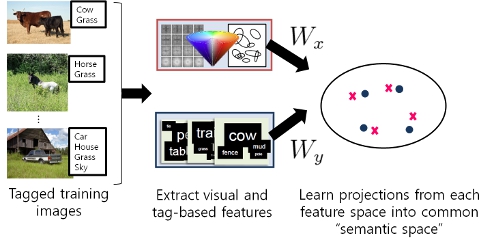
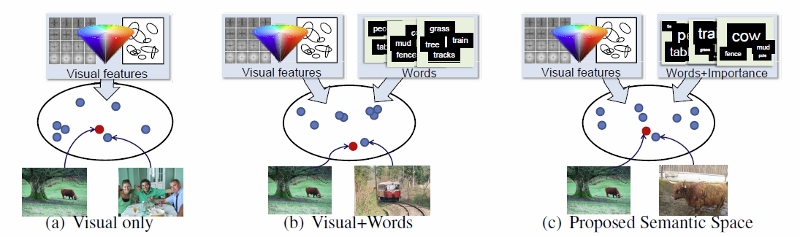 Main idea.
Main idea. (a) Using only visual cues allows one to retrieve similar-looking examples for a query (bottom left image / denoted with red dots), but can result in semantically irrelevant retrievals (e.g., similar colors and edges, but different objects). (b) Learning a Visual+Words "semantic space" (e.g., with KCCA) helps narrow retrievals to images with a similar distribution of objects. However, the representation still lacks knowledge as to which objects are more important. (c) Our idea is to learn the semantic space using the order and relative ranks of the human-provided tag-lists. As a result, we retrieve not only images with similar distributions of objects, but more specifically, images where the objects have similar degrees of ``importance'' as in the query image. For example, the retrieved image on the bottom right, though lacking a `tree', is a better match due to its focus on the cow.
2) Approach
2.1)Overview
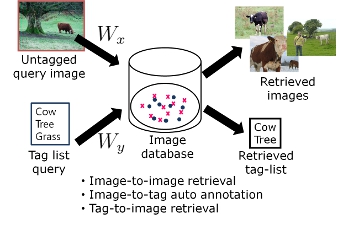
We build the image database by first learning the semantic space and the projects onto them using extracted visual and tag features from a tagged subset of the image databse. Once we build the semantic space, then we can project any images onto it. At the retrieval time, we can use the learned projection to perform multi-modal retrieval from either image or text side. Namely, we can perform three different tasks: 1) Image to image retrieval, 2) Tag to image retrieval, and 3) Image to tag auto annotation.
2.1) Implicit tag features
We consider three types of tag-based features, which together capture the object present as well as an indirect signal about their inter-relationships in the scene.
Word Frequency
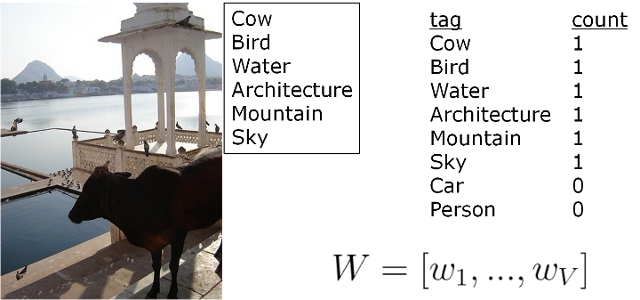 Traditional bag-of-(text)words
Traditional bag-of-(text)words
Absolute Rank
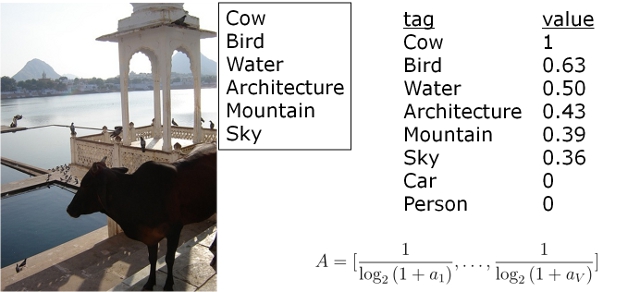 Absolute rank in the image's tag list
Absolute rank in the image's tag list
Relative Rank
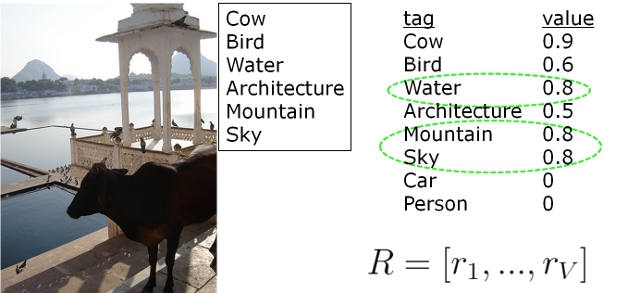 Percentile rank obtained from the rank distribution of that word in all tag-lists
Percentile rank obtained from the rank distribution of that word in all tag-lists
2.2) Learning the semantic space
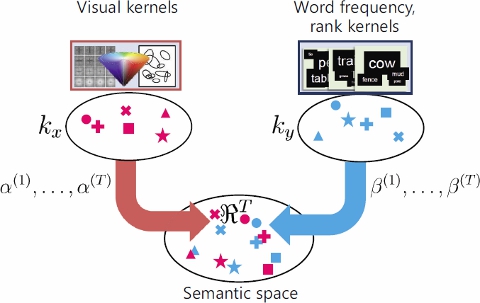
Using KCCA (Kernelized Canonical Correlation Analysis), We learn nonlinear correlation between the points in two feature spaces by maximizing the correlation in the semantic space between the points projected from the same instances.
3) Results
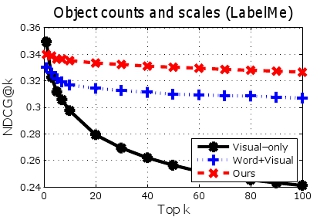
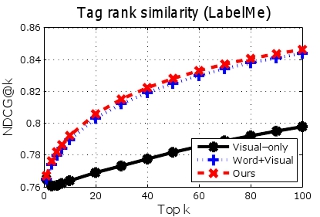
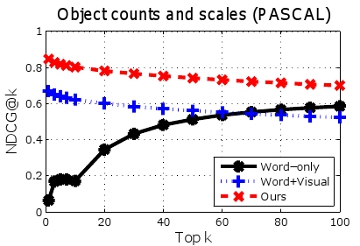
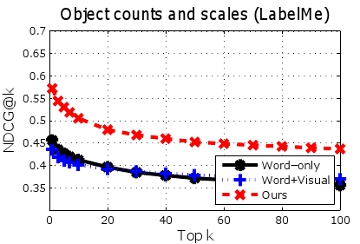
3.1) Image to image retrieval
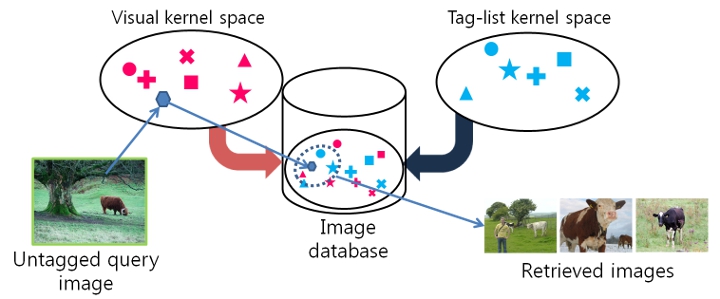
Given an
untagged image, we want to retrieve images that are relevant to the query, in terms of object importance.
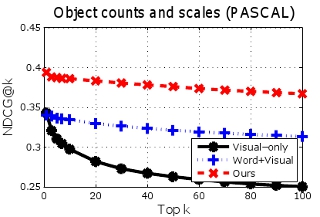
Image-to-image retrieval results for PASCAL (top row) and LabelMe (bottom row). Higher curves are better. By modeling importance cues from the tag-lists when building the semantic space, our method outperforms both a method using image features alone, as well as a semantic space that looks only at unordered keywords.
Example image-to-image retrieval results for our method and the baselines. While a baseline that builds the semantic space from Words+Visual features can often retrieve images with an object set overlapping the query's, ours often better captures the important objects that perceptually define the scene.
3.2) Tag to image retrieval
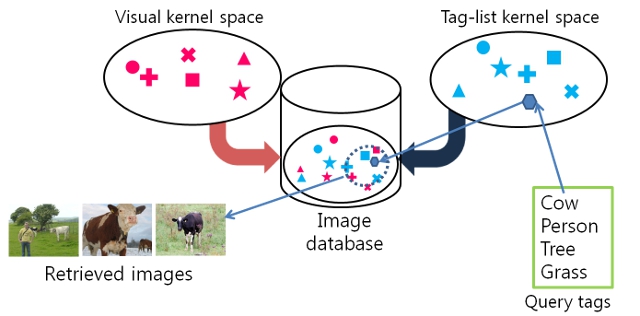
Given a tag list, we want to retrieve images that is best described by it, in terms of implicit object importance conveyed in the ordered tag list.
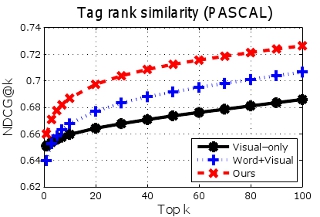
Tag-to-image retrieval results. Given a user's ordered tag list, our method retrieves images better respecting the objects' relative importance.
3.3) Image to tag auto annotation
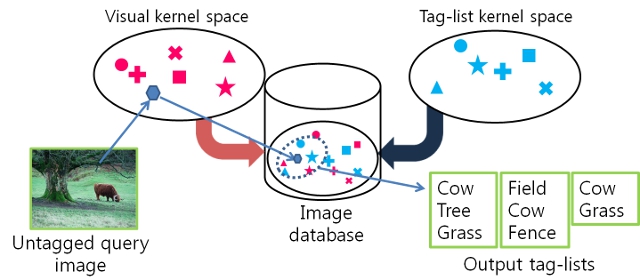 Given an image, our method generates a list of tags.
Given an image, our method generates a list of tags.
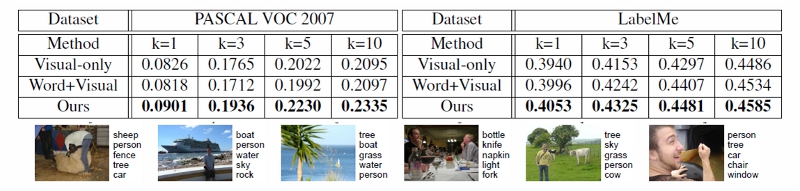
Top: Image-to-tag auto annotation accuracy(F1 score). Bottom: Examples of annotated images. Tags are quite accurate for imags that depict typical scenes. Last example is a failure case.
Downloads
LabelMe dataset
[labelme.tar.gz]
PASCAL dataset
[pascal.tar.gz]
Publication
Accounting for the Relative Importance of Objects in Image Retrieval.
[pdf]
Sung Ju Hwang and Kristen Grauman
In Proceedings of the British Machine Vision Conference (BMVC), Aberystwyth, UK, September 2010