Reading Between The Lines: Object Localization
Using Implicit Cues from Image Tags
Sung Ju Hwang and Kristen Grauman
The University of Texas at Austin
1) Idea

The list of tags on an image may give useful information beyond just which objects are present. The tag lists on these images indicate that each contains a mug. However, they also suggest likely differences between the mug occurences even before we see the pixels. For example, the relative order of the words many indicate prominence in location and scale (mug is named first on the left tag list, and is central in that image; mug is named later on the right tag list, and is less central in that image), while the absence of other words may hint at the total scene composition and scale (no significantly larger objects are named in the left image, and the mug is relatively large; larger furniture is named on the right, and the mug is relatively small).
2) Approach
2.1) Features
Wordcount
 A traditional bag-of-words representation, extracted from a single image's list of tags.
A traditional bag-of-words representation, extracted from a single image's list of tags.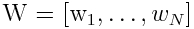 where
where 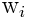 denotes the number of times that tag i occurs in that image's associated list of keywords, for a vocabulary of N total possible words.
denotes the number of times that tag i occurs in that image's associated list of keywords, for a vocabulary of N total possible words.Rank
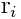 denotes the percentile of the rank for tag i in the current image, relative to all previous ranks observed in the training data for that word (note that i indexes the vocabulary, not the tag list).
denotes the percentile of the rank for tag i in the current image, relative to all previous ranks observed in the training data for that word (note that i indexes the vocabulary, not the tag list).Proximity

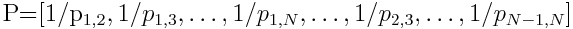 , where
, where 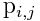 denotes the signed rank difference between tag words i and j for the given image. The entry is 0 when the pair is not prsent.
denotes the signed rank difference between tag words i and j for the given image. The entry is 0 when the pair is not prsent.
2.2) Modeling the Localization Distributions
We need the conditional probability of the location and scale given tag features; that is we wish to model P(X|T), where X = (s, x, y) (scale, x position, y position), and T = W, R, or P. To model this conditional PDF, We use a mixture of Gaussians, since we expect most categories to exhibit multiple modes of location and scale combinations. We compute the parameters of the mixture models using a Mixture Density Network (MDN), which allows us to directly model this conditional PDF, training on a collection of tagged images with bounding box ground truth for the target object.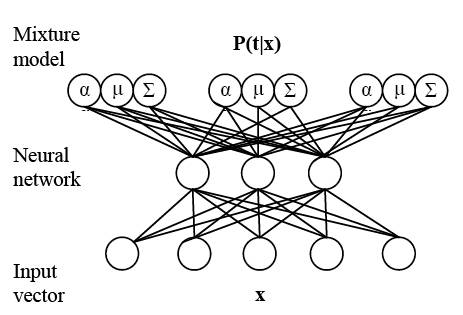
Mixture density network
2.3) Modulating or Priming the Detector
Once we have the function P(X|T), we can either combine its predictions with an object detector that computes P(X|A) based on appearance cues A, or else use it to rank sub-windows and run the appearance based detector on only the most probable locations ("priming"). The former has potential to improve accuracy, while the latter will improve speed.Modulating the detector
We use the following logistic regression classifier to balance the appearance and tag-based predictions.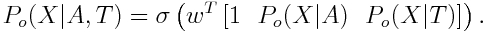
Priming the detector
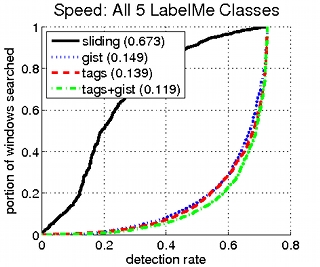
Instead of scanning the whole image, our method prioritizes the search window according to P(X|T), and stops searching with the appearance based detector once a confident detection is found. The below figures show the real examples of location our method would search first. |
 |
 |
 |
The top 30 most likely places for a car in several tagged images, as computed by our Method.
3) Results
3.1) LabelMe
 |
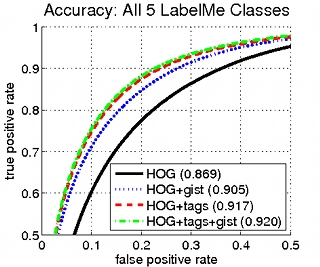 |
| Person |  |
 |
 |
Sky Buildings Person Sidewalk Car Car Road |
| Car |  |
 |
 |
Car Window Road Window Sky Wheel Sign |
| Screen |  |
 |
 |
Desk Keyboard Screen |
| Keyboard |  |
 |
 |
Bookshelf Desk Keyboard Screen |
| Mug |  |
 |
 |
Mug Keyboard Screen CD |
3.2) PASCAL VOC 2007
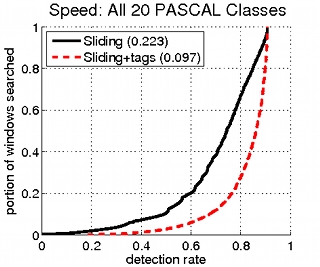 |
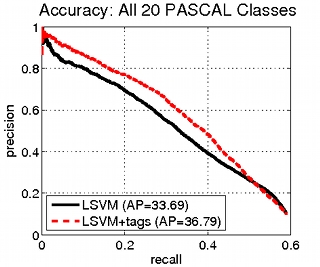 |
| Aeroplane |  |
 |
 |
| Boat |  |
 |
 |
| Bottle |  |
 |
 |
| Dog |  |
 |
 |
| Person |  |
 |
 |
Publication
Reading Between The Lines: Object Localization Using Implicit Cues from Image Tags [pdf]Sung Ju Hwang and Kristen Grauman
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, June 2010