Text detection in stores has valuable applications that could transform the shopping experience, yet cluttered store environments present distinct challenges for existing techniques. We propose a strategy for text detection in stores that exploits a repetition prior. Leveraging the fact that
shops typically display multiple instances of the same product on the shelf, our approach localizes text regions with a global view of the image, preferring instances that have repeated support in the scene. On two challenging real-world datasets taken with a mobile phone and wearable camera, we demonstrate our method’s substantial advantages compared to several state-of-the-art techniques in grocery store environments
Our Method
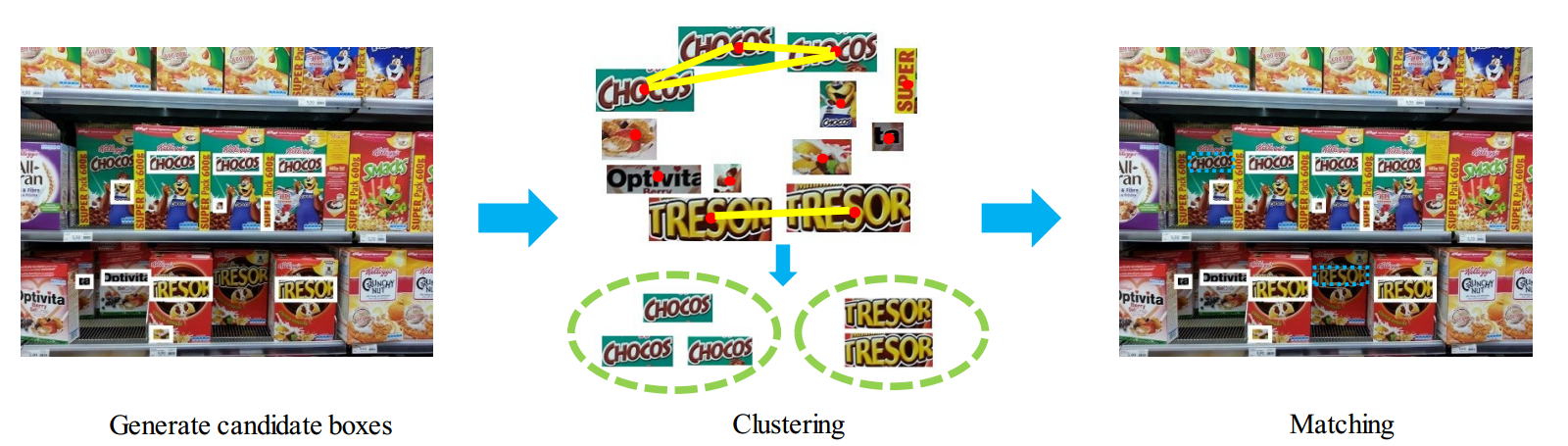
We start with candidate text bounding boxes as shown on the left (only a subset are drawn for legibility purposes), and then find similar candidates by connected components clustering (middle). Using each cluster as an anchor, we detect additional text boxes via local feature matching, as shown on the right. Original candidate boxes are drawn in solid lines and newly detected text candidate boxes are drawn in dotted lines. Finally, based on the results of the clustering and matching stages, we rank each text bounding box with a confidence score.
Results
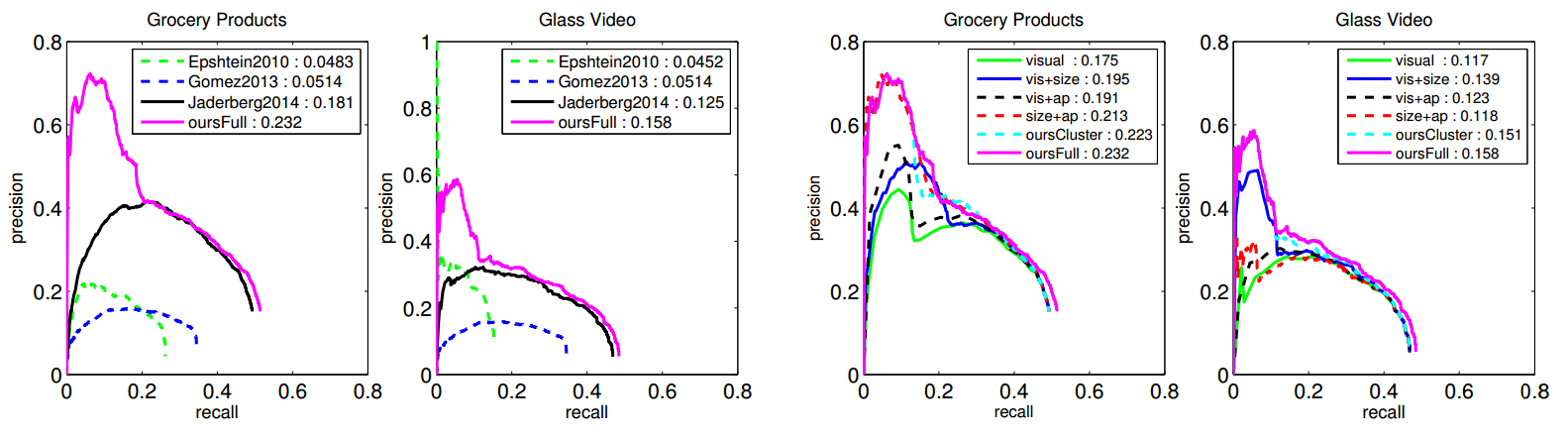
We evaluate our approach on two challenging datasets and compare to multiple recent text detection methods. We also examine the impact of the design choices in our clustering approach.
Overall, our method outperforms the existing methods. Our gains over the two non-learning approaches are largest, reinforcing recent findings about the power of learned character detectors that leverage large training data sets. Furthermore, we see sizeable gains over the state-of the-art deep learning approach, particularly in terms of precision. This is an important empirical finding, since our method specifically builds on the output of the deep learning approach, enhancing it with the repetition prior. Our method improves the CNN approach by leveraging the repetition prior to better rank the bounding boxes proposals and re-detect harder texts.
Downloads
You can download the annotations using the links below:
data.zipAnnotations on
the Grocery Products dataset and the Glass Video dataset. We also provide corresponding frames from the Glass Video.
@InProceedings{text-repetition, author = {B. Xiong and K. Grauman}, title = {Text Detection in Stores Using a Repetition Prior}, booktitle = {WACV}, month = {March}, year = {2016} }