Learning a Tree of Metrics
with Disjoint Visual Features
Sung Ju Hwang, Kristen Grauman and Fei Sha
The University of Texas at Austin
University of Southern California
Motivation
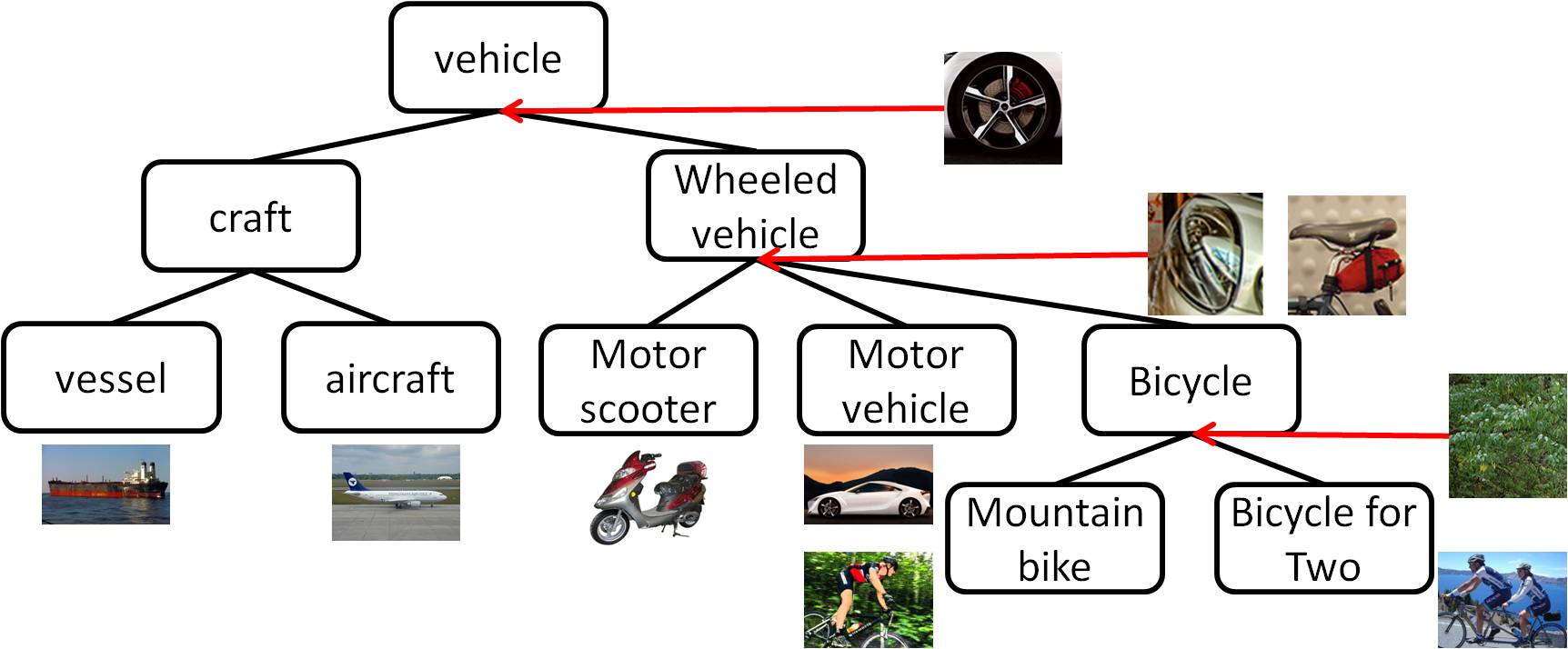
Idea
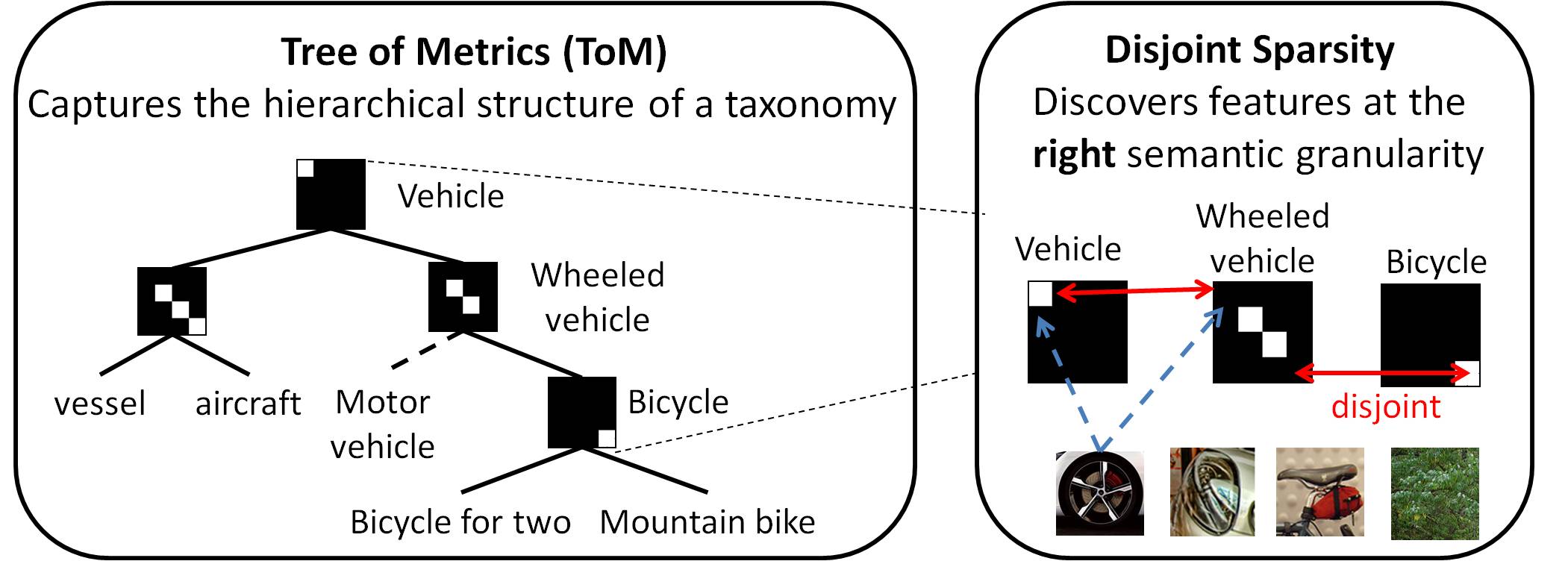
Approach
Tree of Metrics (ToM)
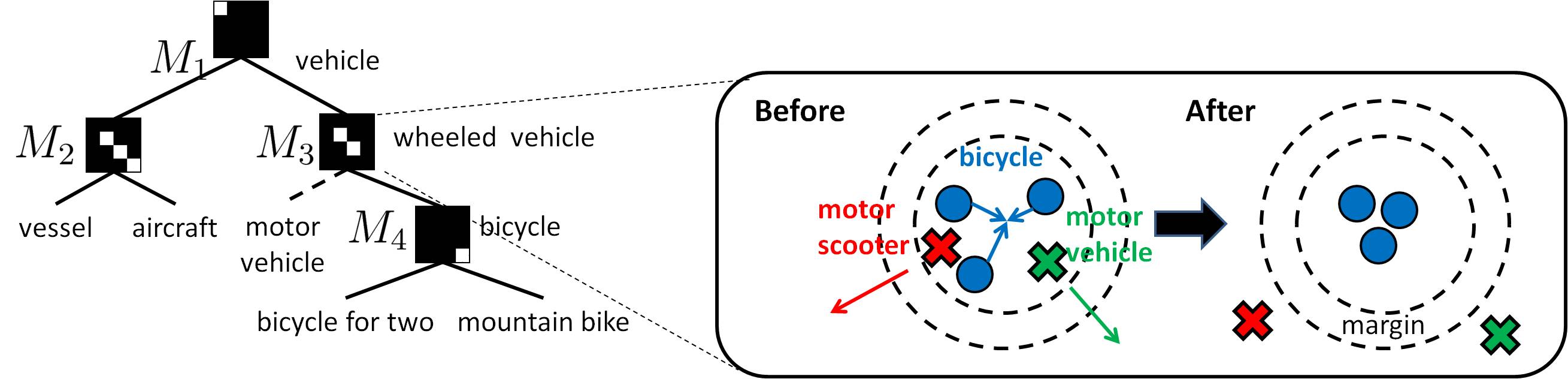
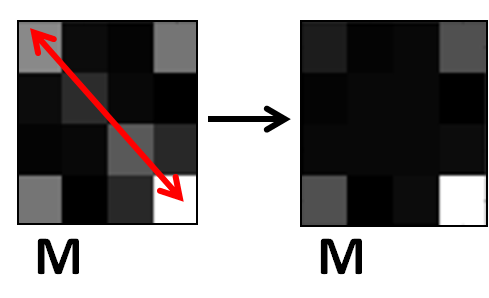
Regularization terms to learn compact discriminative metrics
| Local level (sparsity regularization) | Global level (disjoint regularization) |
 |
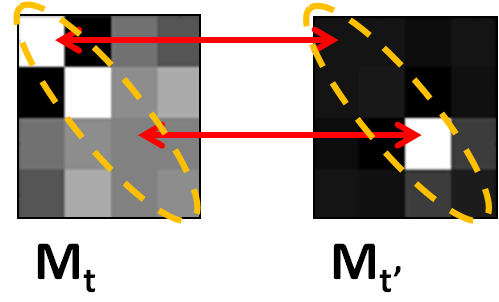 |
| Apply trace-norm based regularization at each node. Promotes competition between features in a single metric. | Apply disjoint regularization between nodes. Promotes competition for the features between metrics. |
Optimization problem
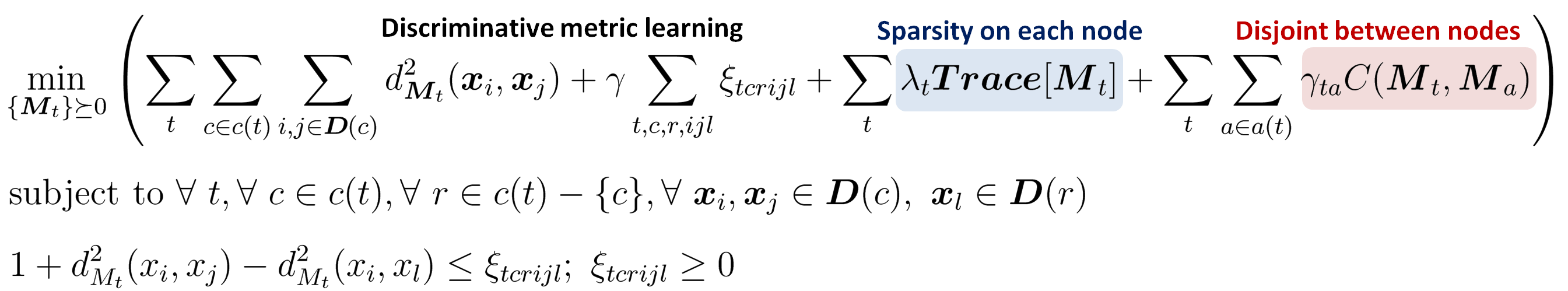
The above optimization problem is convex, but nonsmooth due to the large margin constraints. We optimize it using a subgradient solver similar to the one in [2].
Classification with Tree of Metrics
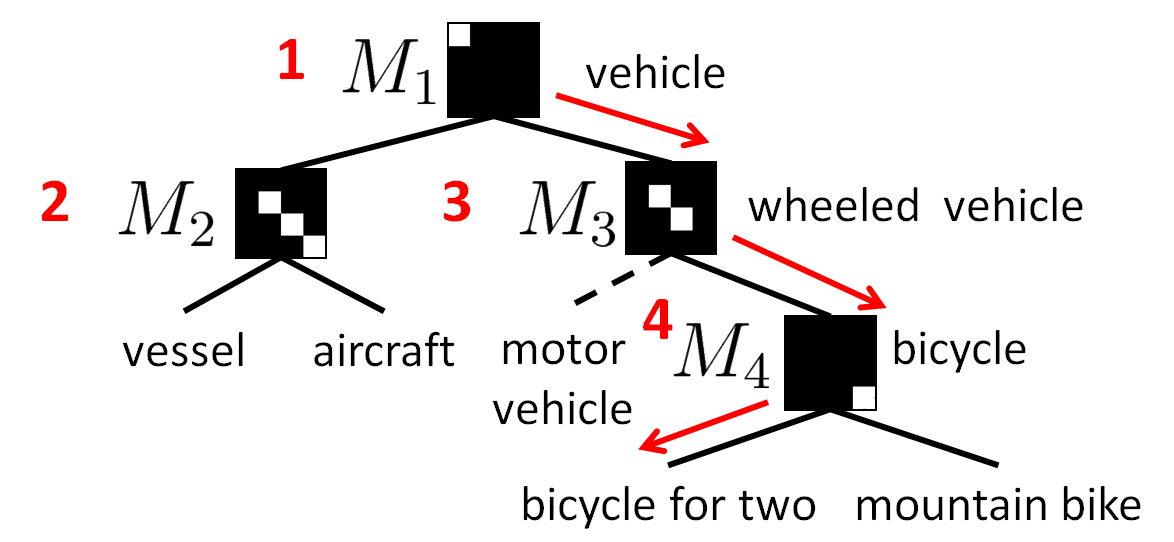
Proof of Concept
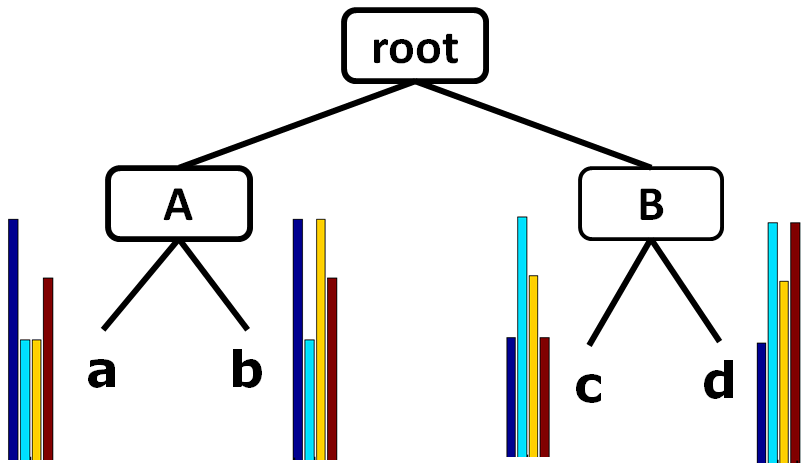 |
 |
 |
 |
| Synthetic dataset & category hierarchy | ToM | ToM + sparsity | Tom + disjoint |
Visual recognition experiments
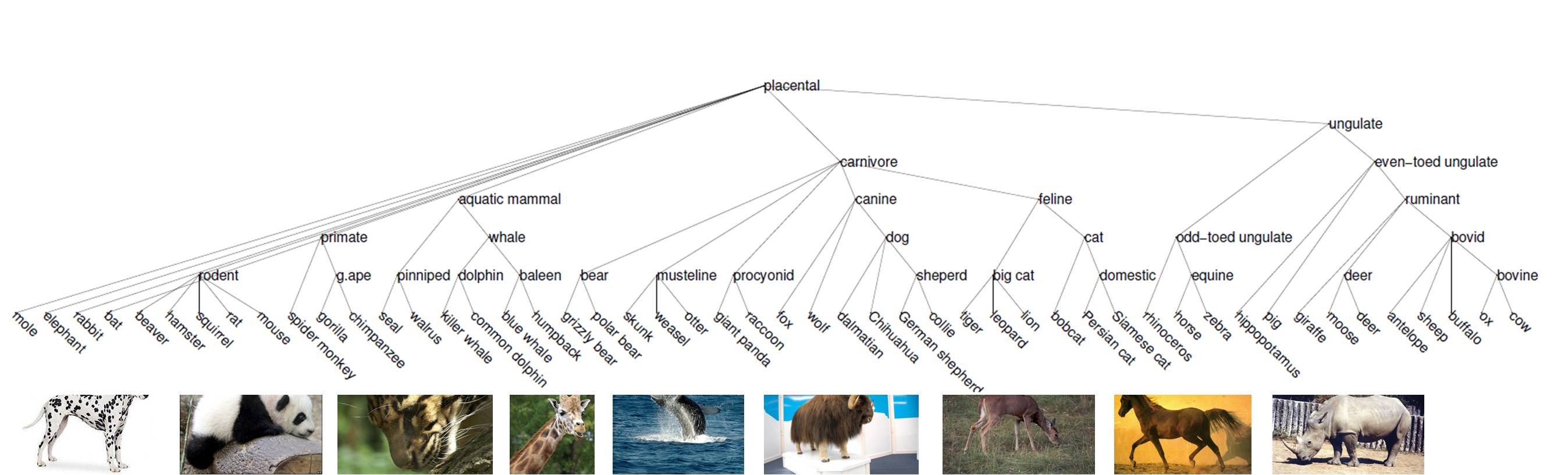
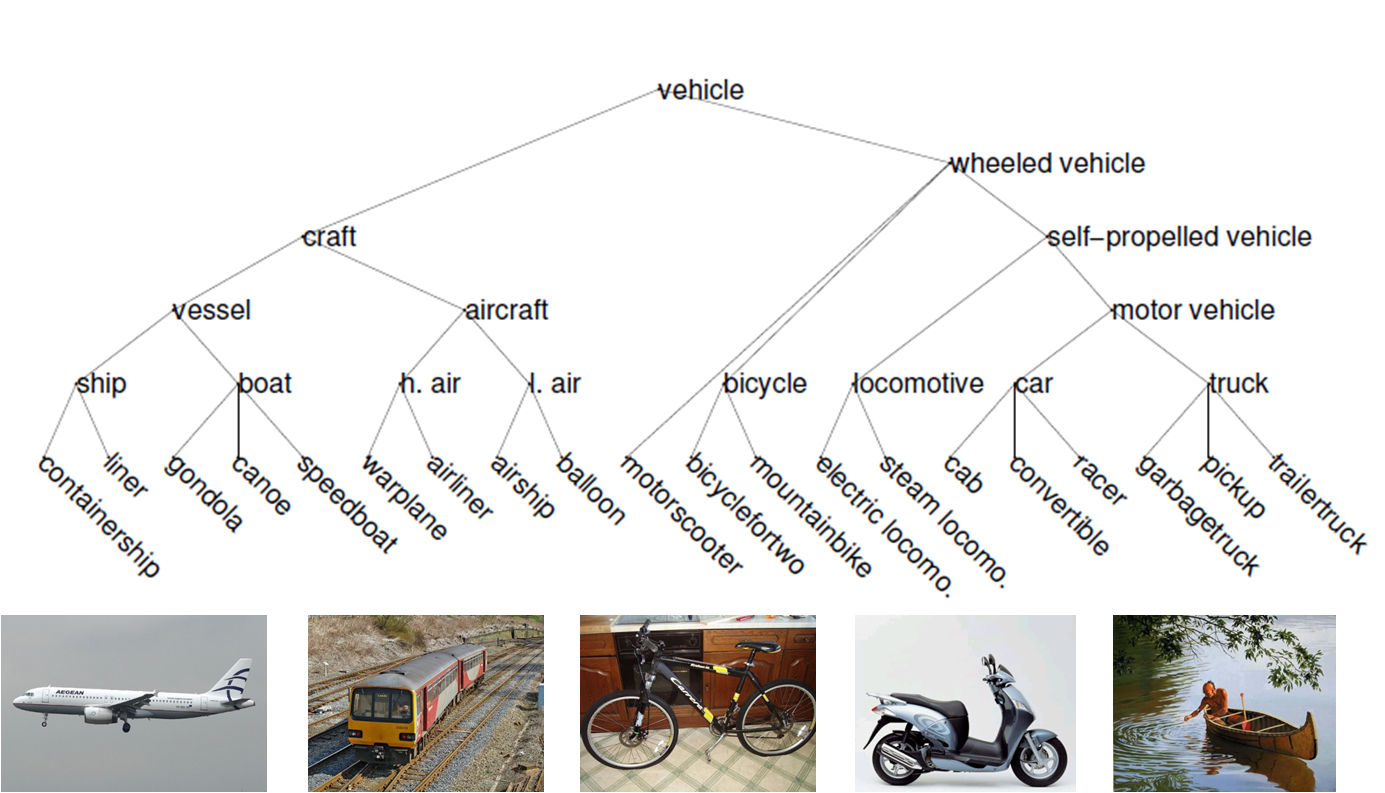
Datasets
 |
 |
|
| Animals with Attributes (AWA) | Imagenet Vehicle | |
| ~30K images | ~26K images | |
| 50 classes | 20 classes |
Hierarchical multi-class classification accuracy
| AWA-ATTR (Predicted Attributes) | Vehicle-20 (PCA projected) | |||
|---|---|---|---|---|
| Method | Correct label | Semantic similarity | Correct label | Semantic similarity |
| Euclidean | 32.4 | 53.6 | 28.5 | 56.1 |
| Global LMNN [1] | 32.5 | 53.9 | 29.7 | 53.6 |
| Multi-metric LMNN [1] | 32.3 | 53.7 | 30.0 | 57.9 |
| ToM w/o disjoint sparsity | 36.8 | 58.4 | 31.2 | 60.7 |
| ToM + sparsity | 37.6 | 59.3 | 32.1 | 62.7 |
| ToM + disjoint | 38.3 | 59.7 | 32.8 | 63.0 |
Attributes selected from the AWA-ATTR dataset
 |
 |
Related
Comparison with orthogonal transfer [3].| Orthogonal Transfer | Tree of Metrics |
|---|---|
| Orthogonality does not necessarily imply disjoint features | Learns true disjoint features |
| The convexity of the regularizer depends critically on tuning the weight matrix K | Regularizers are convex |
References
[1] K. Q. Weinberger, J. Blitzer and L. K. Saul, Distance Metric Learning for Large Margin Nearest Neighbor Classification, NIPS, 2006[2] Y. Ying, K. Huang and C. Campbell, Sparse Metric Learning via Smooth Optimization, NIPS, 2009
[3] D. Zhou, L. Xiao and M. Wu, Hierarchical Classification via Orthogonal Transfer, ICML, 2011
Source codes and data
[tom.tar.gz] (183Mb) (v0.9) Contains matlab codes for ToM, the data, and other utilities for taxonomiesC++ implementation with matlab interface (v1.0) will be released soon.
Publication
Learning a Tree of Metrics with Disjoint Visual FeaturesSung Ju Hwang, Fei Sha and Kristen Grauman
Advances in Neural Information Processing System (NIPS),
Granada, Spain, December 2011