WhittleSearch: Image Search with Relative Attribute Feedback
Adriana Kovashka, Devi Parikh, and Kristen Grauman
Note: We have a patent pending for this work.
We also have a demo for this project.
Abstract
We propose a novel mode of feedback for image search,
where a user describes which properties of exemplar images
should be adjusted in order to more closely match his/her
mental model of the image(s) sought. For example, perusing
image results for a query "black shoes", the user might
state, "Show me shoe images like these, but sportier." Offline,
our approach first learns a set of ranking functions,
each of which predicts the relative strength of a nameable
attribute in an image ('sportiness', 'furriness', etc.). At
query time, the system presents an initial set of reference
images, and the user selects among them to provide relative
attribute feedback. Using the resulting constraints in
the multi-dimensional attribute space, our method updates
its relevance function and re-ranks the pool of images. This
procedure iterates using the accumulated constraints until
the top ranked images are acceptably close to the user.s envisioned
target. In this way, our approach allows a user to
efficiently "whittle away" irrelevant portions of the visual
feature space, using semantic language to precisely communicate
her preferences to the system. We demonstrate the
technique for refining image search for people, products,
and scenes, and show it outperforms traditional binary relevance
feedback in terms of search speed and accuracy.
Introduction
Existing image search methods rely either on keywords or on content-based retrieval. Keywords are not enough-- we cannot pre-tag all images the user might like to search with keywords that match whatever query the user might come up with. On the other hand, content-based image retrieval is limited by the well-known "semantic gap" between low-level cues and the higher-level user intent. User feedback can help, but current methods provide a very narrow channel for human feedback -- it is not clear what about the marked images is relevant or irrelevant.
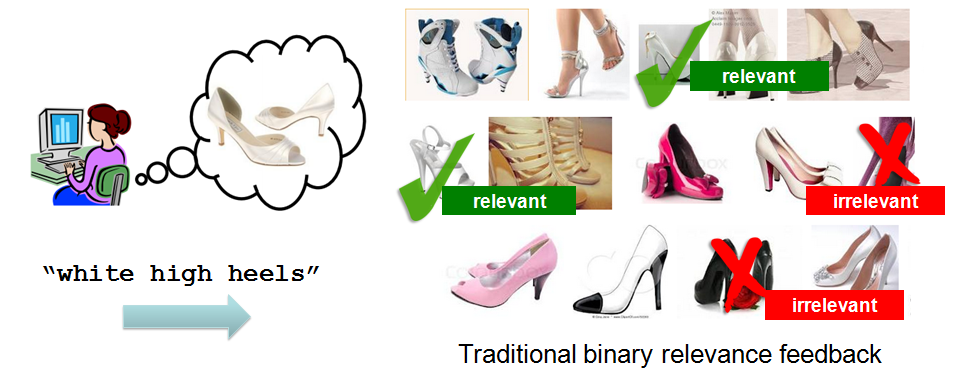
Therefore, we propose to use relative attributes for more specific user feedback in image search. We allow user to describe precisely what is missing from current set of results. The user expresses the semantics of their search goal through relative attributes, relating their target and some pre-selected exemplar images. Note that attributes (or "concepts" in the information retrieval community) have been used previously for search, but users have not been allowed to isolate individual attributes as a handle for feedback.
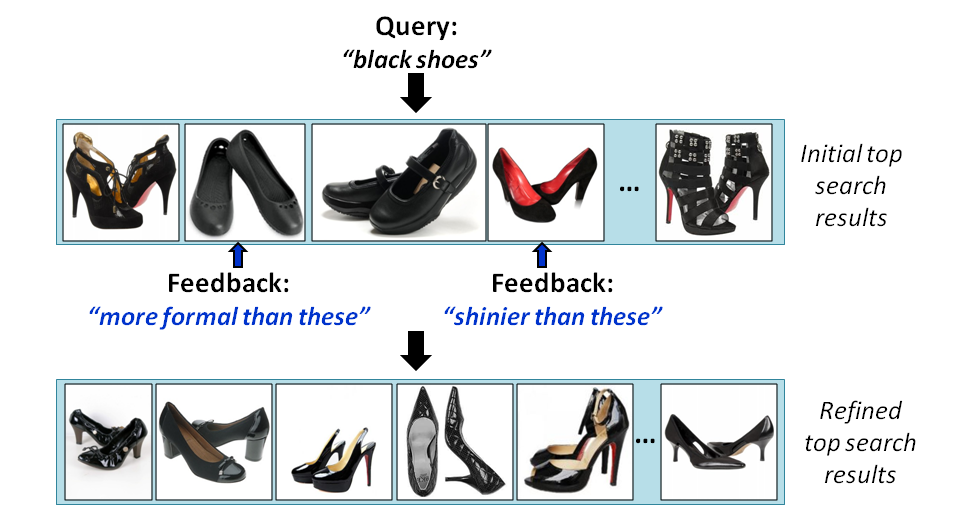
Our idea: Allow users to give relative attribute feedback on reference images to refine their image search.
Approach
Step 1: Predict relative attribute strengths.
Step 2: Get user statements relating their search target to exemplar images.
Step 3: Use the constraints to whittle away irrelevant regions of the multi-dimensional attribute space.
Background: Binary Relevance Feedback
- User marks some images as relevant or irrelevant given their search target.
- We learn a binary classifier using the relevant images as positives and the irrelevant images as negatives, and rank images in the dataset by the classifier outputs.
Relative Attribute Feedback
Learning to predict relative attributes
We learn relative attributes as in Parikh and Grauman, "Relative Attributes", ICCV 2011.

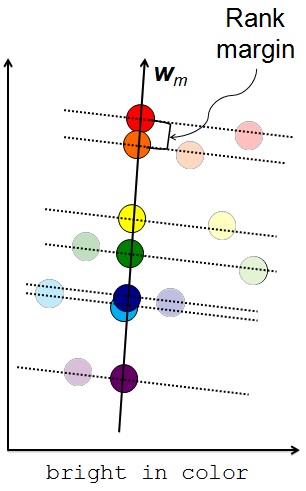
Interface for image-level relative attribute annotations.
- Obtain ordered image pairs
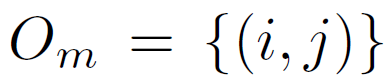 and unordered pairs
and unordered pairs 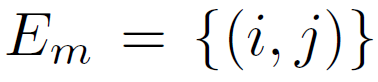 such that
such that 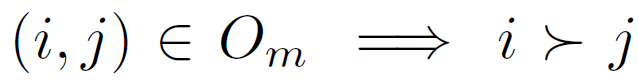 (image i has stronger presence of attribute m than image j) and
(image i has stronger presence of attribute m than image j) and 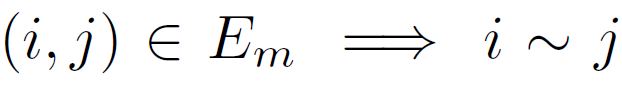 (the images have equivalent presence of attribute m).
(the images have equivalent presence of attribute m).
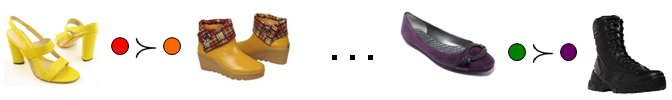

- Learn a ranking function
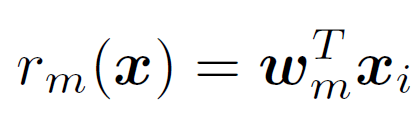 such that as many of the following constraints are satisfied as possible:
such that as many of the following constraints are satisfied as possible:
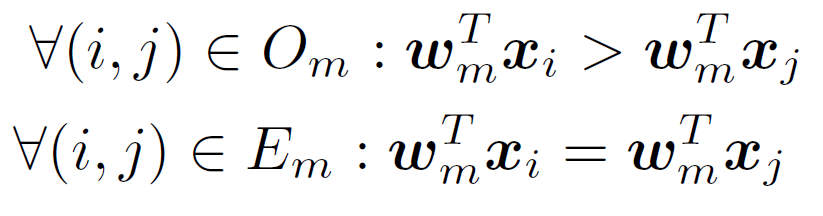 .
.
- For the latter, use the formulation due to Thorsten Joachims, "Optimizing Search Engines Using Clickthrough Data", KDD 2002:
minimize 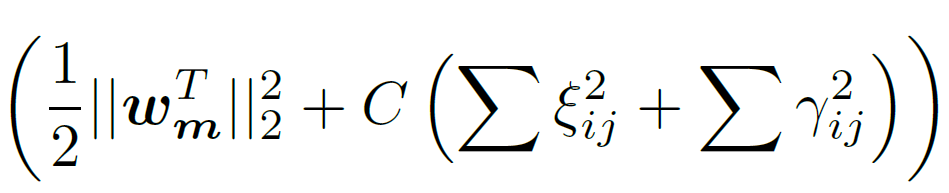 subject to:
subject to:
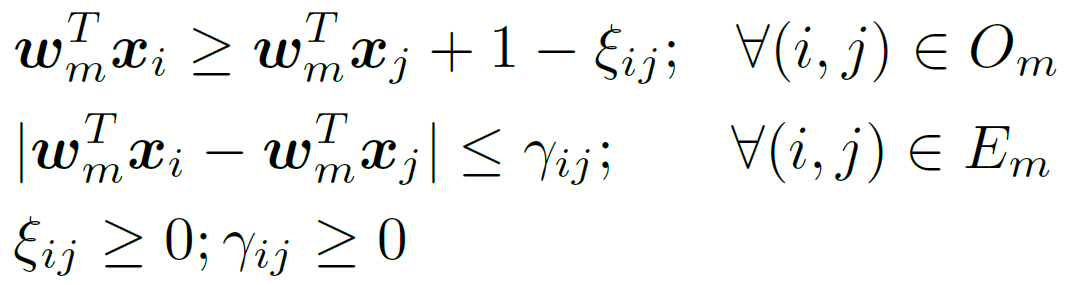
Updating the scoring function from feedback
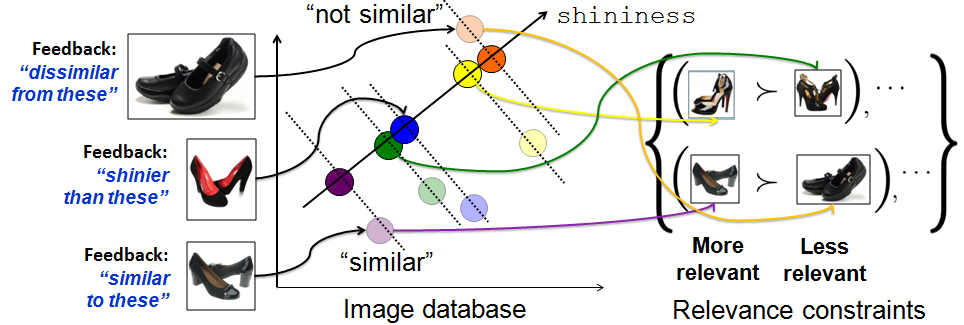
- User selects some images and marks how they differ from the image want, thus defining constraints: "I want [objects] that are [more/less] [attribute name] than this image."
- We update the scores for each image in the dataset, using these constraints.

- For a constraint of the type: "I want images exhibiting more of attribute m than reference image
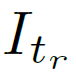 , the scoring function
, the scoring function 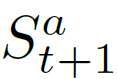 should satisfy:
should satisfy:
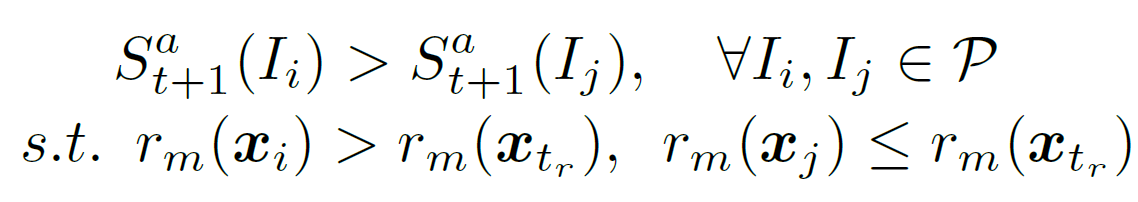
- For a constraint of the type: "I want images exhibiting less of attribute m than reference image , the scoring function should satisfy:
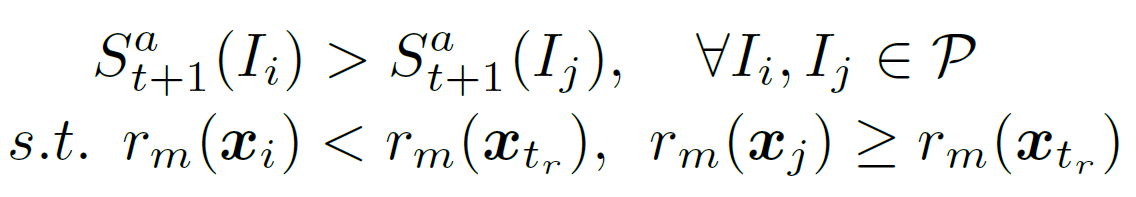
- For constraints of the type: "I want images that are similar in terms of attribute m to reference image , the scoring function should satisfy:
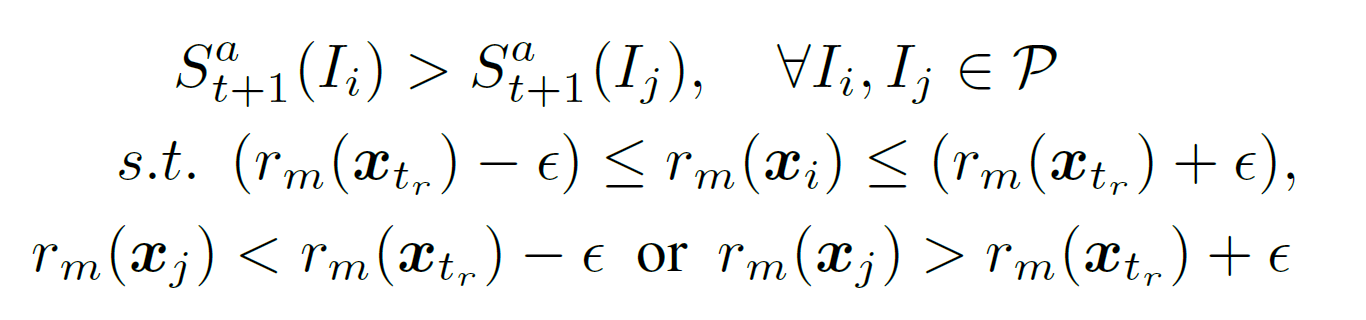
- At the top we rank images whose score
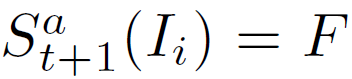 , i.e. images that satisfy all F constraints given so far. Next are images which satisfy F-1 constraints, etc.
, i.e. images that satisfy all F constraints given so far. Next are images which satisfy F-1 constraints, etc.
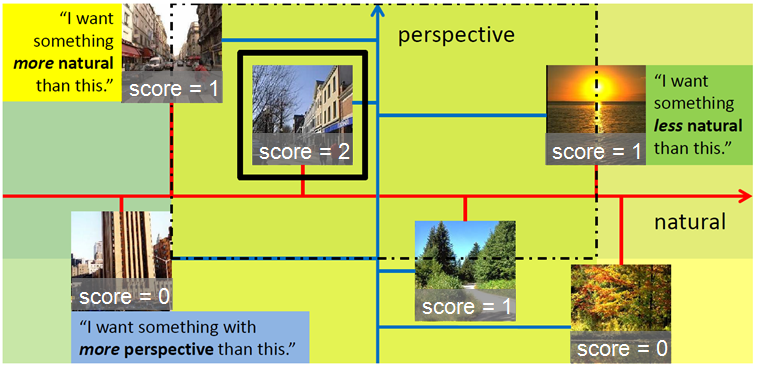
A toy example illustrating the intersection of relative
constraints with M = 2 attributes. The images are plotted on
the axes for both attributes. The space of images that satisfy each
constraint are marked in a different color. The region satisfying all
constraints is marked with a black dashed line. In this case, there
is only one image in it (outlined in black).
- Note that our method allows user to refine their query, in a way that a query stated in absolute attribute terms cannot.
- Our method is efficient, since it only involves set-logic operations and no learning.
Hybrid Feedback Approach
- Using images marked as positive (
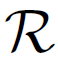 ), ones marked as negative (
), ones marked as negative (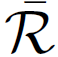 ), and our the sets of images
), and our the sets of images 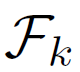 which satisfy k constraints, we can define a set which includes all relevance preferences:
which satisfy k constraints, we can define a set which includes all relevance preferences:
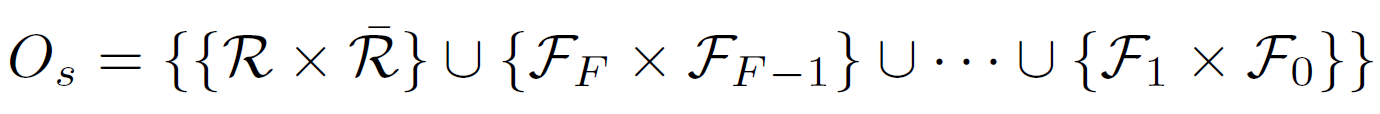
and a set which expresses equivalent relevance:
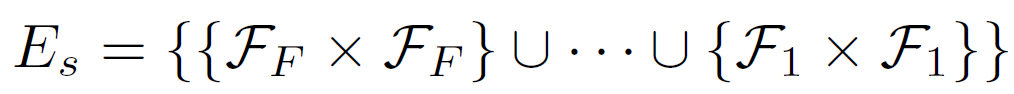
- Then we can learn a relevance ranking function.
Experimental Results
Experimental Design
Datasets
- Shoes -- 14,658 shoe images from the Attribute Discovery dataset, augmented with 10 attributes: pointy at the front, open, bright in color, high at the heel, covered with ornaments, shiny, long on the leg, formal, sporty, feminine -- dataset and instance-level relative annotations can be downloaded here
- OSR -- 2,688 images from Outdoor Scene Recognition; 6 attributes -- instance-level relative annotations can be downloaded here, dataset can be found here
- PubFig -- 772 images from Public Figures dataset; 11 attributes -- instance-level relative annotations can be downloaded here, dataset can be found here

Evaluation Metrics
- Rank -- assigned to the secret image (low is good since image appears closer to top)
- NDCG@50 -- correlation between the method's ranking and a ground truth ranking (high is good)
- Ground truth: images ranked by their distance to the secret image in learned feature space
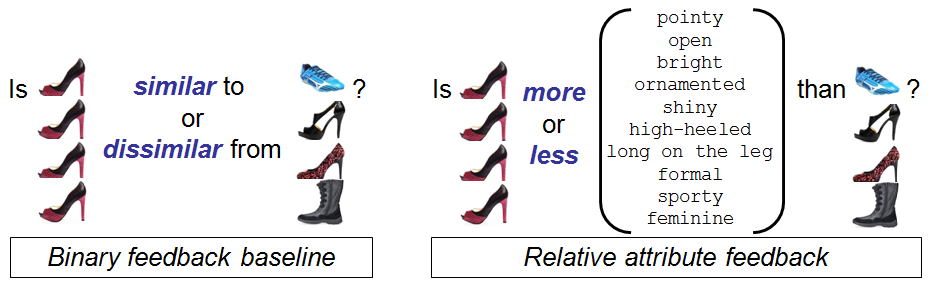
Feedback generation
- Pair each target image with 16 exemplars, show the pairs to users on Mechanical Turk and ask:
- For our method: "Is the target image more or less [attribute name] than the exemplar?"
- For binary feedback baseline: "Is the target image similar or dissimilar from the exemplar?"
- Or, generate feedback automatically:
- For our method: randomly sample constraints using relationship between secret image's and exemplar's predicted relative attribute values
- For baseline: sample positives/negatives using their image feature distance to secret image
Feedback Results
Impact of iterative feedback
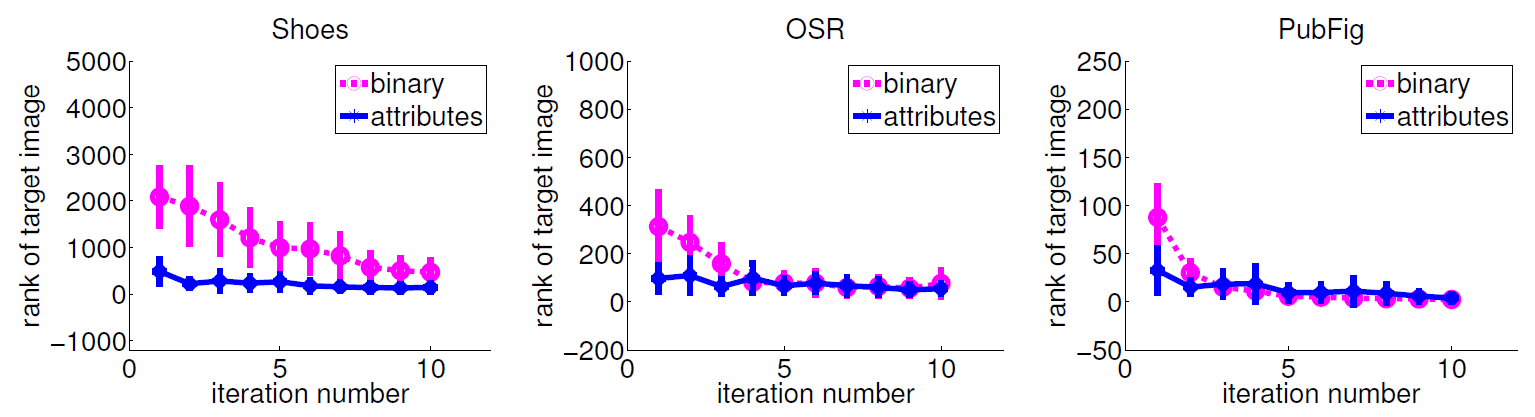
Our method converges faster than SVM-based binary feedback. Our advantage is stronger on datasets with more fluid categories.
Impact of amount of feedback
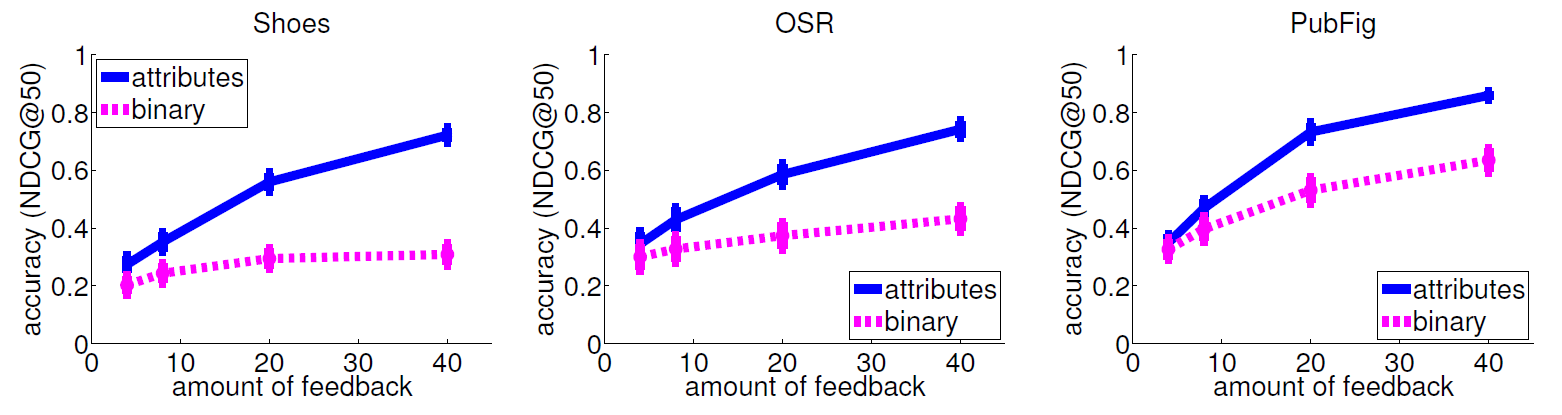
Our method learns faster; it achieves higher accuracy with fewer constraints.
Impact of reference images
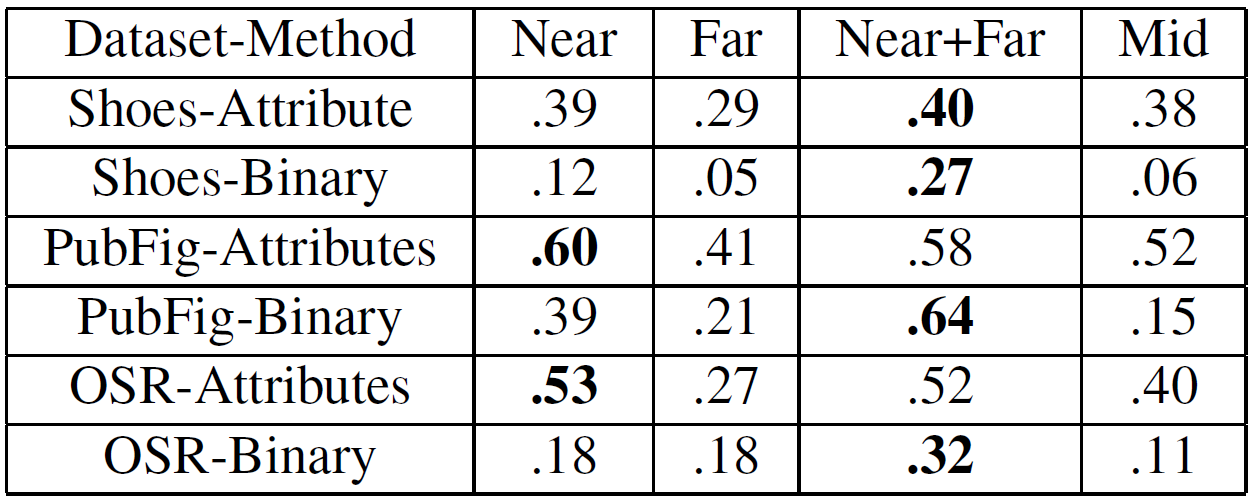
Baseline needs good positives and negatives; our method needs similar images or a mix.
Ranking accuracy with human-given feedback
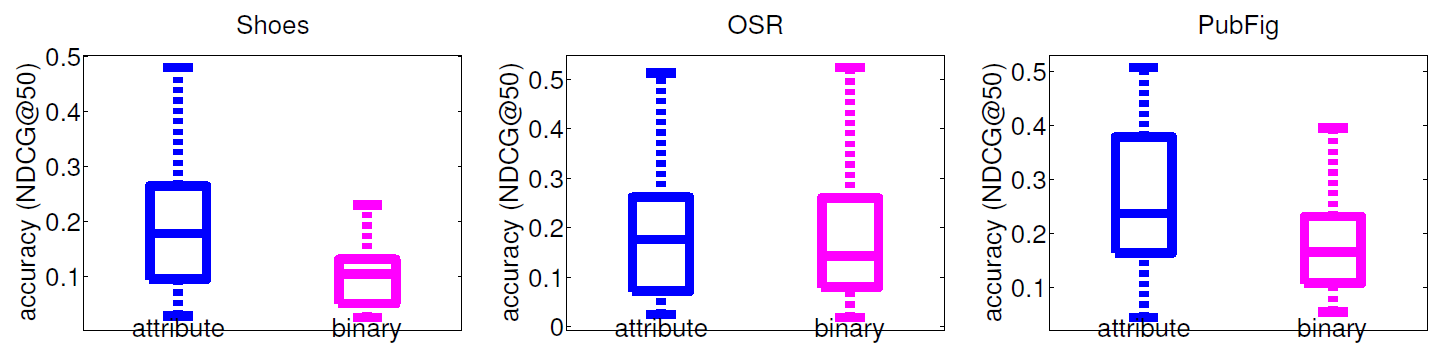
Initialization with random reference images.
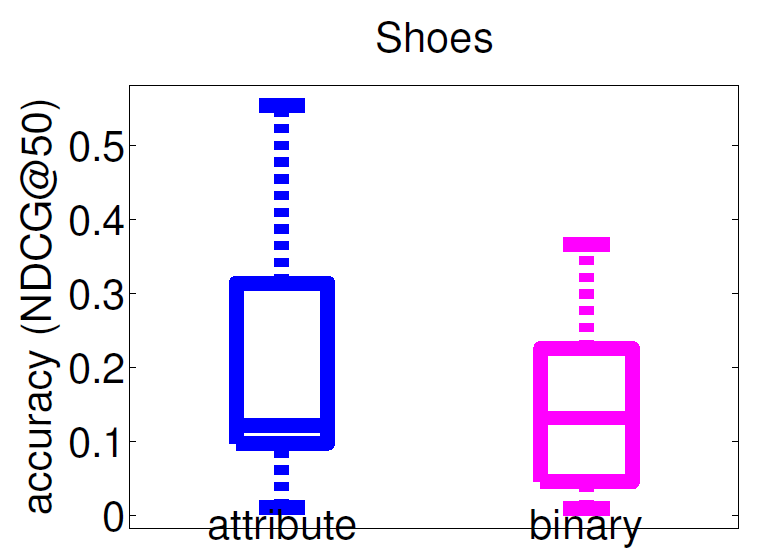
Initialization via an attribute-keyword query.
Our method outperforms binary search but not on OSR; may be due to human difficulty with attribute vocabulary. Relative attribute feedback can also refine keyword search.
Qualitative Results
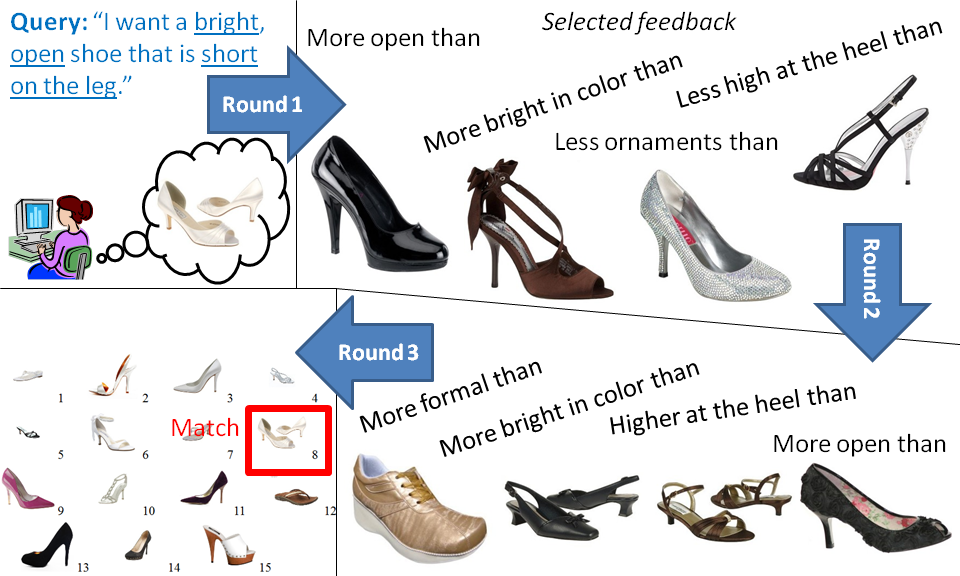
Example iterative search results with relative attribute feedback.
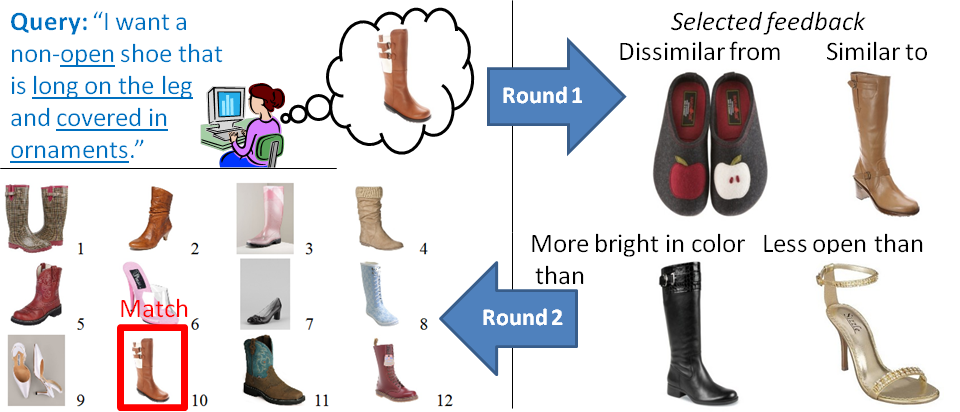
Example search result with hybrid feedback.
Note: You can find additional results in our supplementary file.
Consistency of Relative Supervision Types
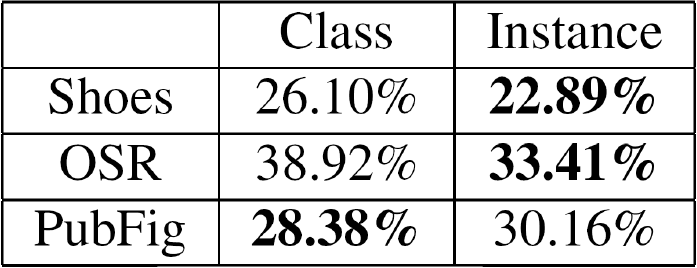
Class-level vs. instance-level
Humans agree more when asked to compare image instances (6% disagreement) than when asked to compare image categories (13% disagreement). Furthermore:
Instance-based learning is less error-prone than class-based learning for images with less strict category boundaries.
Absolute vs. relative
Humans agree more when they make relative statements (17% disagreement) vs absolute statements (22% disagreement).
Conclusion
We proposed a method that allows user to communicate very precisely how the retrieved results compare with their mental model. Our method refines results more effectively, often with less human effort.
Publication and Dataset
WhittleSearch: Image Search with Relative Attribute Feedback. Adriana Kovashka, Devi Parikh, and Kristen Grauman. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, June 2012. [pdf] [supplementary] [.bib file] [poster] [Shoes dataset] [OSR annotations] [PubFig annotations]
Note: Please send a blank email to [adriana AT cs DOT utexas DOT edu] with "WhittleSearch Shoes dataset" in the subject line so we know who downloaded our dataset, and also so we can let you know of any updates to this dataset. We will also post any updates on this page.
Note: The full OSR and PubFig datasets from the "Relative Attributes" paper can be found here.