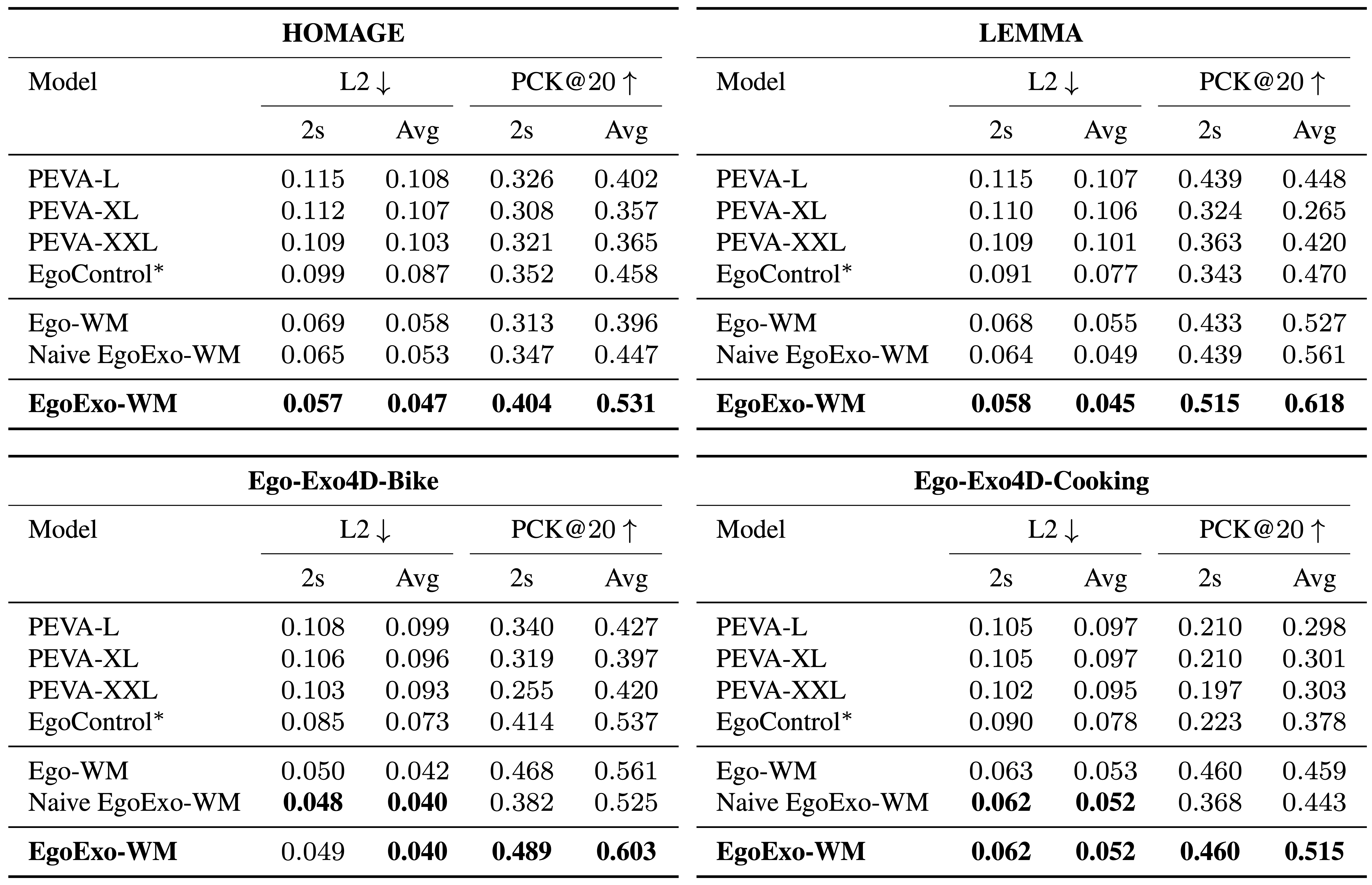
Existing Ego World Models Rely Solely on Ego video, which has inherent limitations...
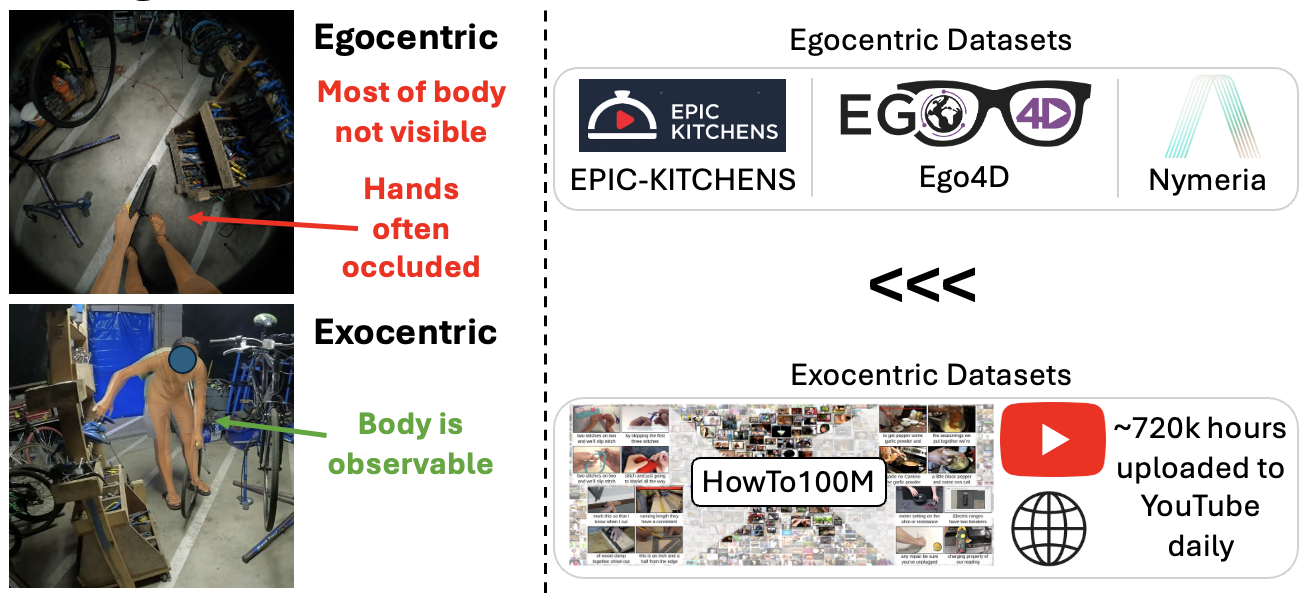
Egocentric video often occludes the human body and is dwarfed by largely exocentric internet-scale videos.
References
- Miech, Antoine, et al. "HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
- Grauman, Kristen, et al. "Ego4D: Around the World in 3,000 Hours of Egocentric Video." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
- Grauman, Kristen, et al. "Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
- YouTube. "YouTube at 15: My Personal Journey and the Road Ahead." YouTube Official Blog, 14 Feb. 2020, blog.youtube/news-and-events/youtube-at-15-my-personal-journey/.
- Damen, Dima, et al. "Scaling Egocentric Vision: The EPIC-KITCHENS Dataset." Proceedings of the European Conference on Computer Vision (ECCV). 2018.