A short silent video designed to supplement the paper
Personal VCL
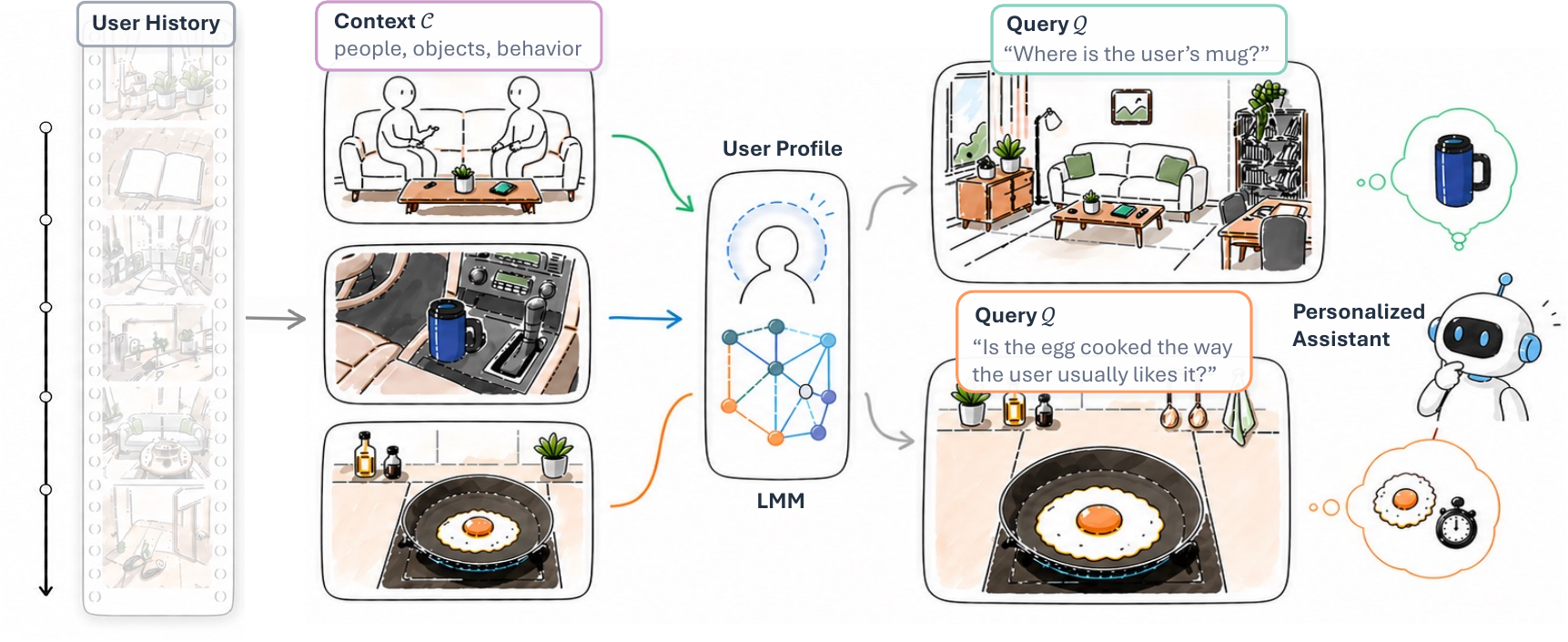
As wearable devices like smart glasses integrate Large Multimodal Models (LMMs) into the continuous first-person visual stream of an individual user, the evolution of these models into true personal assistants hinges on visual personalization: the ability to reason over visual information unique to the wearer.
We formalize this capability as Personal Visual Context Learning (Personal VCL), the prompt-time capability of using user-specific visual context to resolve personalized queries.
Personal-VCL-Bench
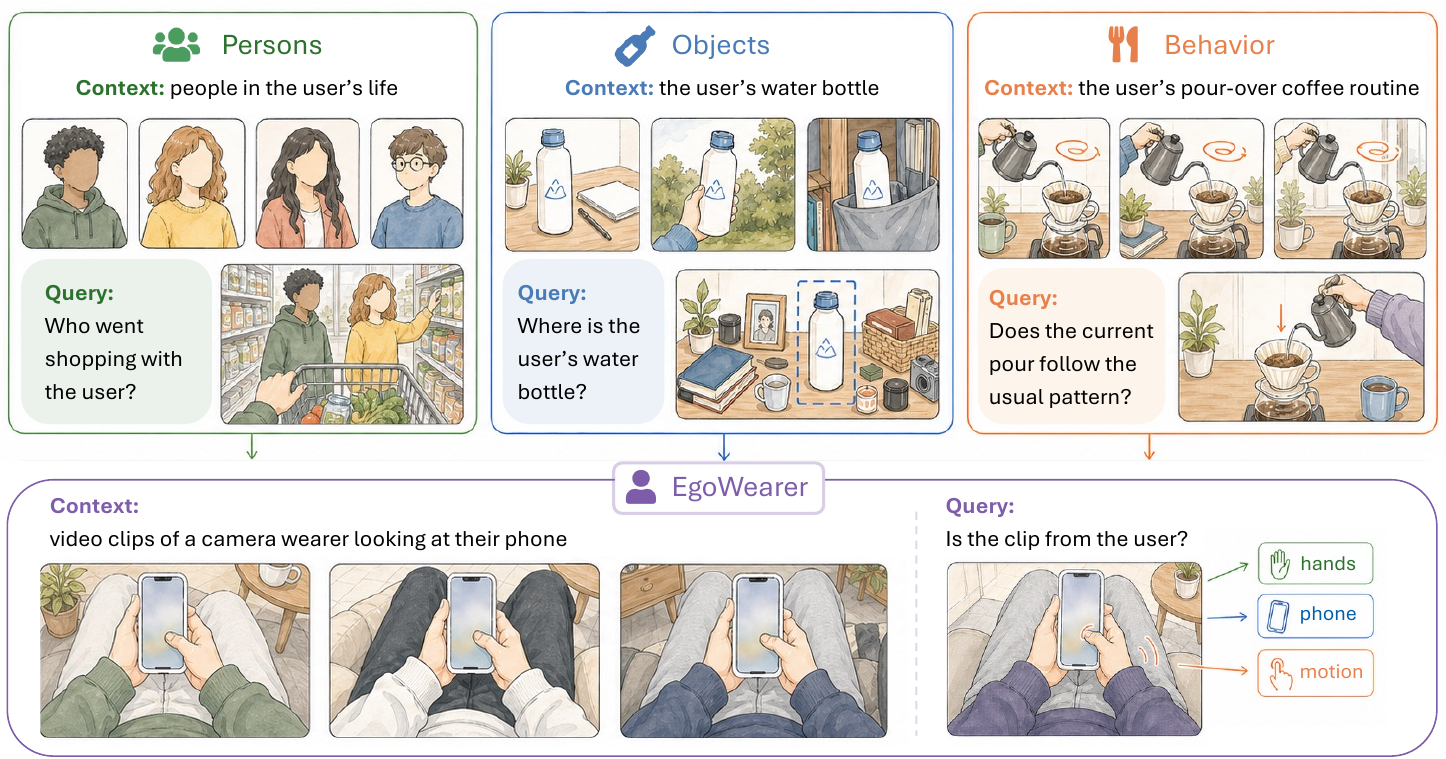
We propose Personal-VCL-Bench, a benchmark organized around the three core axes of a user's visual world: persons, objects, and behavior. It culminates in EgoWearer Identification, a capstone challenge where the model must recognize the user behind a new egocentric video by aggregating subtle, persistent cues from their prior history: who they interact with, what they own, and how they navigate routine activities.
Built on top of EgoLife, Ego4D, and CaptainCook4D, the benchmark contains 2,255 clean context-query instances spanning 7 tasks; each query is paired with 4.25 supplied context images/clips on average.
Diagnosing the Personal VCL Gap
Benchmarking seven frontier LMMs on Personal-VCL-Bench, we reveal a substantial Personal VCL gap: raw visual context is not reliably exploited, and scaling up the volume of context often fails to improve performance. Two paradoxes emerge:
Modality paradox
Providing the model with a language summary of the visual context, an inherently lossy compression, yields performance on par with or even superior to using the raw pixels. Current LMMs struggle to natively reason over visual evidence and instead lean on textual proxies.
Scaling paradox
A core assumption of in-context learning is that more evidence yields better predictions. Yet adding additional historical context items frequently fails to improve accuracy, revealing the inability of current models to synthesize multiple visual observations into consistent personal patterns.
Baseline Approach: Agentic Context Bank
Motivated by the diagnosis above, we propose the Agentic Context Bank as a strong, model-agnostic, inference-time baseline for Personal VCL. Rather than concatenating raw visual context into the prompt, our approach organizes a user's visual history into a structured, evidence-linked memory and selectively grounds only the entries needed for a given query.
Stage I — Structured Bank Construction. Disjoint context items are converted into a coherent, self-refining memory bank of typed entries (appearance, owned objects, behavior), each pairing a natural-language descriptor with its supporting visual evidence. The bank is updated sequentially through four operations: add, confirm, revise, and retract.
Stage II — Query-Adaptive Evidence Selection. At inference, the model first surveys a lightweight text view of the bank and either answers directly or requests the visual evidence for selected entry IDs. Only the supporting frames or clips for those selected entries are then attached to the prompt for a second, final-answer call, leaving the rest of the bank as compact text.
// Stage I: Structured Bank Construction (query-agnostic)B ← ∅
forvi ∈ VcdoMi ← Extract(vi) // candidate memory entries (τ, d, e)for each (τ, d, e) ∈ Midoop ← Merge(B, (τ, d, e)) // op ∈ {add, confirm, revise, retract}
apply op to B// Stage II: Query-Adaptive Evidence Selection (query-specific)TB ← TextView(B) // memory descriptors with entry IDsy ← fθ(TB, Lq, Vq) // Call 1: text triageify = (request, I) thenHI ← HybridView(B, I) // inline evidence only for selected IDsA ← fθ(HI, Lq, Vq) // Call 2: selective visual verificationelseA ← y.answer
returnA
Together, the two stages turn the diagnostic findings into a concrete Personal VCL baseline. Stage I tackles the scaling paradox by shifting the unit of context from isolated clips to persistent, evidence-linked personal cues. Stage II addresses the modality paradox by replacing passive visual concatenation with query-conditioned selection, which preserves the benefit of textual organization while retaining access to supporting visual evidence.
Qualitative Example
A walk-through of the full Agentic Context Bank pipeline. The left side shows Stage-I bank construction: from each context clip, the model extracts candidate memory entries describing visually-grounded appearance or behavior cues, and a merge step consolidates them into stable evidence-linked bank entries. The right side shows Stage-II query-time use: in Query 1, the model requests selected evidence entries for visual verification and confirms the same wearer; in Query 2, the text descriptors already contradict the query clip, allowing a direct negative decision.
Takeaway
Together, our formulation, benchmark, diagnosis, and baseline approach establish Personal VCL as a concrete capability for building LMMs that adapt to individuals through visual experience, an essential next step for the wearable computing era.
BibTeX
@article{xue2026personalvcl,
title={Personal Visual Context Learning in Large Multimodal Models},
author={Xue, Zihui and Baid, Ami and Kim, Sangho and Luo, Mi and Grauman, Kristen},
journal={arXiv preprint arXiv:2605.10936},
year={2026}
}