ViBE: Dressing for Diverse Body Shapes
Wei-Lin Hsiao
Kristen Grauman
UT Austin
Facebook AI Research (FAIR)
In CVPR 2020
Body shape plays an important role in determining what garments will best suit a given person, yet today’s clothing recommendation methods take a “one shape fits all” approach. These body-agnostic vision methods and datasets are a barrier to inclusion, ill-equipped to provide good suggestions for diverse body shapes. We introduce ViBE, a VIsual Body-aware Embedding that captures clothing’s affinity with different body shapes. Given an image of a person, the proposed embedding identifies garments that will flatter her specific body shape. We show how to learn the embedding from an online catalog displaying fashion models of various shapes and sizes wearing the products, and we devise a method to explain the algorithm’s suggestions for well-fitting garments. We apply our approach to a dataset of diverse subjects, and demonstrate its strong advantages over status quo body-agnostic recommendation, both according to automated metrics and human opinion.
Dataset Introduction
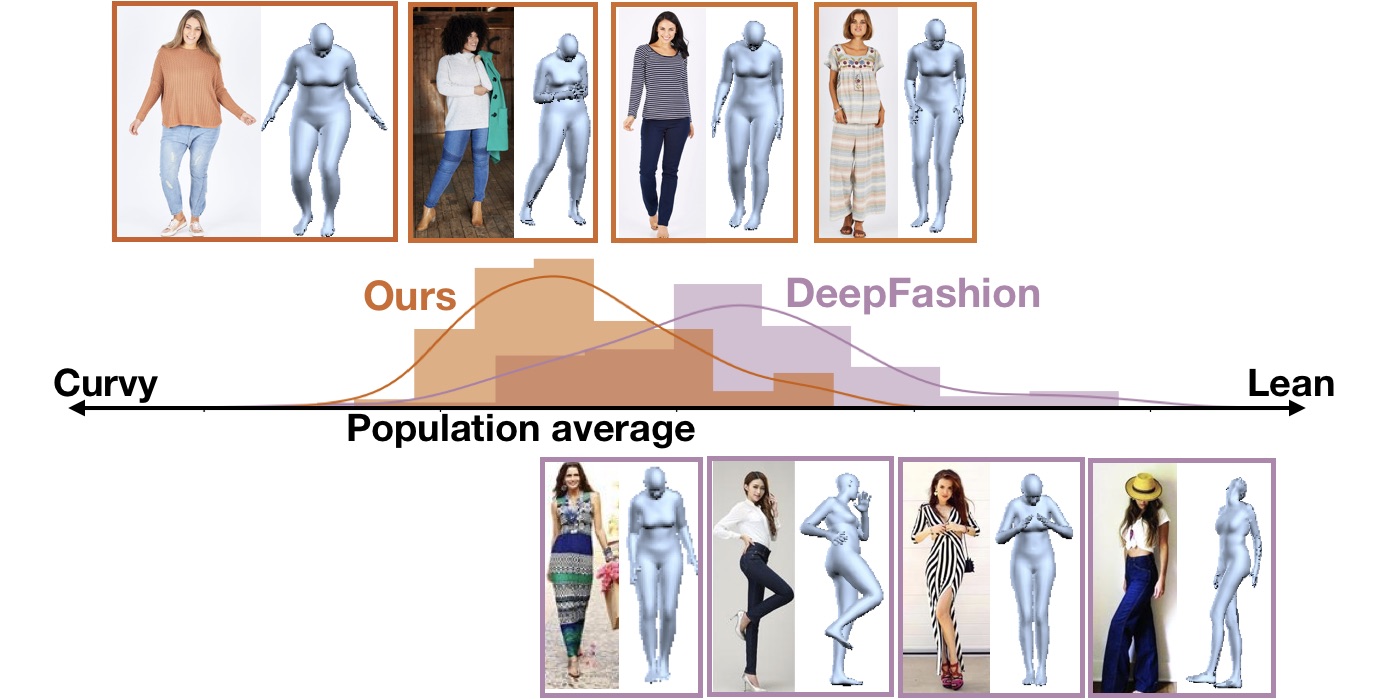
Trained largely from images of slender fashionistas and celebrities (bottom row), existing methods ignore body shape's effect on clothing recommendation and exclude much of the spectrum of real body shapes. Our proposed embedding considers diverse body shapes (top row) and learns which garments flatter which across the spectrum of the real population. Histogram plots the distribution of the second principal component of SMPL for the dataset we collected (orange) and DeepFashion (purple). We collected our dataset from an online shopping website Birdsnest.
ViBE Overview
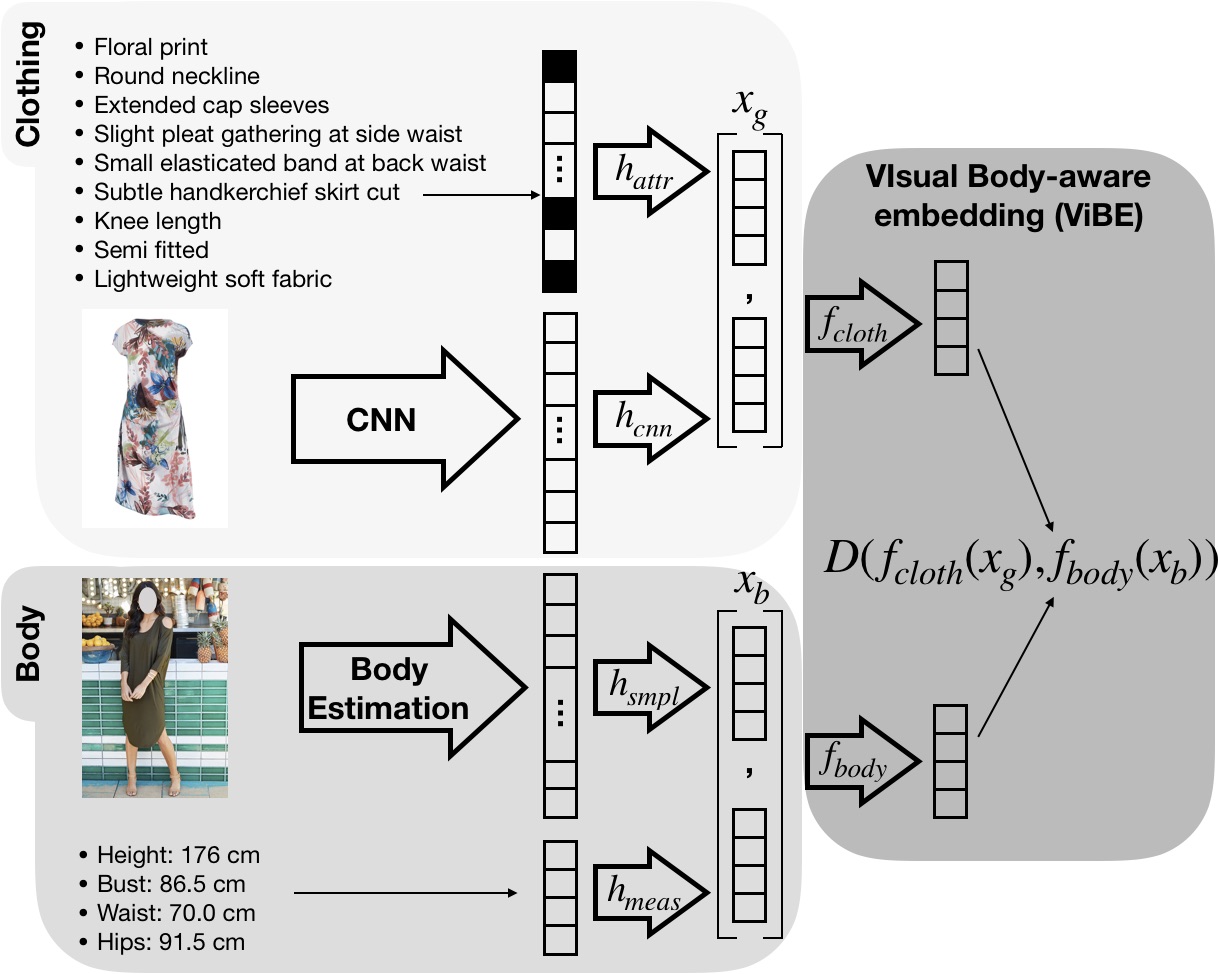
We use mined attributes with CNN features for clothing, and estimated SMPL parameters and vital statistics for body shape. Following learned projections, they are mapped into the joint embedding that measures body-clothing affinities.
ViBE Example Recommendations and Explanations
For each subject (row), we show the predicted most (left) and least (right) suitable attributes (text at the bottom) and garments, along with the garments' explanation localization maps. The "suitable silhouette" image represents the gestalt of the recommendation. The localization maps show where our method sees (un)suitable visual details, which agree with our method’s predictions for (un)recommended attributes.
