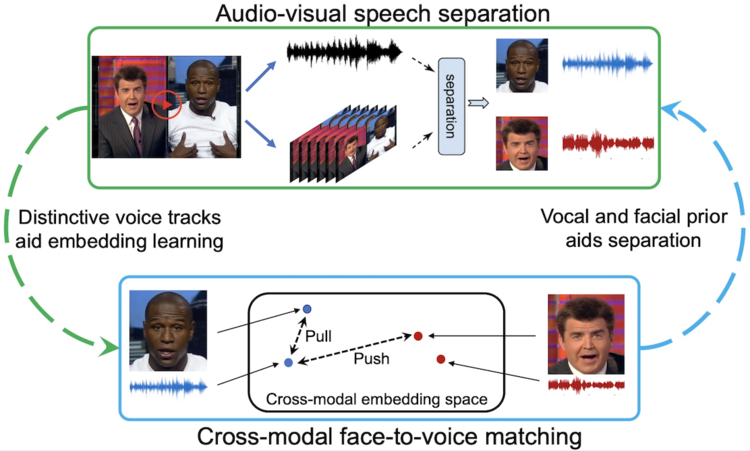
We introduce a new approach for audio-visual speech separation. Given a video, the goal is to extract the speech associated with a face in spite of simultaneous background sounds and/or other human speakers. Whereas existing methods focus on learning the alignment between the speaker's lip movements and the sounds they generate, we propose to leverage the speaker's face appearance as an additional prior to isolate the corresponding vocal qualities they are likely to produce. Our approach jointly learns audio-visual speech separation and cross-modal speaker embeddings from unlabeled video. It yields state-of-the-art results on five benchmark datasets for audio-visual speech separation and enhancement, and generalizes well to challenging real-world videos of diverse scenarios.
Qualitative Video
In the qualitative video, we show example separation results. We first show audio-visual speech separation and enhancement results on real-world test videos of multiple speakers in various challenging scenarios including interviews, zoom calls, and noisy restaurants. Next, we show some qualitative results on synthetic mixtures from the VoxCeleb2 dataset and compare with the baselines. Finally, we show some failure cases of our model.
Publication
R. Gao and K. Grauman. "VisualVoice: Audio-Visual Speech Separation with Cross-Modal Consistency". In CVPR, 2021.[bibtex]
@inproceedings{gao2021VisualVoice, title = {VisualVoice: Audio-Visual Speech Separation with Cross-Modal Consistency}, author = {Gao, Ruohan and Grauman, Kristen}, booktitle = {CVPR}, year = {2021} }
Acknowledgement
Thanks to Ariel Ephrat, Triantafyllos Afouras, and Soo-Whan Chung for help with experiments setup and to Lorenzo Torresani, Laurens van der Maaten, and Sagnik Majumder for feedback on paper drafts. RG is supported by a Google PhD Fellowship and a Adobe Research Fellowship. UT Austin is supported in part by NSF IIS-1514118 and the IFML NSF AI Institute.