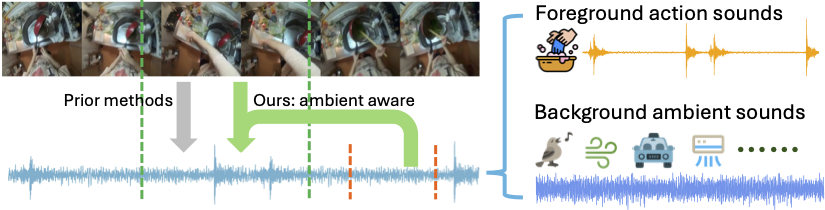
Generating realistic audio for human interactions is important for many applications, such as creating sound effects for films or virtual reality games. Existing approaches implicitly assume total correspondence between the video and audio during training, yet many sounds happen off-screen and have weak to no correspondence with the visuals---resulting in uncontrolled ambient sounds or hallucinations at test time. We propose a novel ambient-aware audio generation model, AV-LDM. We devise a novel audio-conditioning mechanism to learn to disentangle foreground action sounds from the ambient background sounds in in-the-wild training videos. Given a novel silent video, our model uses retrieval-augmented generation to create audio that matches the visual content both semantically and temporally. We train and evaluate our model on two in-the-wild egocentric video datasets Ego4D and EPIC-KITCHENS. Our model outperforms an array of existing methods, allows controllable generation of the ambient sound, and even shows promise for generalizing to computer graphics game clips. Overall, our work is the first to focus video-to-audio generation faithfully on the observed visual content despite training from uncurated clips with natural background sounds.
We curate a new datasets based on Ego4D, Ego4D-Sounds, to study the problem of action sound generation from egocentric videos. It contains 1.2 million video clips spanning hundreds of different scenes and actions. Videos have a high action-audio correspondence, making it a high-quality dataset for action to sound generation. Clips have time-stamped narrations describing the actions performed by the camera-wearer. See details of this dataset at the project page.
puts the wheat down
drops the spanner on the table
cuts the grapes from the tree
cuts onion with a knife
Below we show examples of video to audio generation on unseen Ego4D clips for our method and baselines.
Original video
Diff-Foley
Ours (action-ambient joint generation)
Ours (action-focused generation)
We show that our model can generalize to computer graphics game clips. Below we show examples of video to audio generation on unseen VR game clips for our method.
Original video
Ours (action-ambient joint generation)
@inproceedings{chen2024action2sound,
title = {Action2Sound: Ambient-Aware Generation of Action Sounds from Egocentric Videos},
author = {Changan Chen and Puyuan Peng and Ami Baid and Sherry Xue and Wei-Ning Hsu and David Harwath and Kristen Grauman},
year = {2024},
booktitle = {ECCV},
}