| Sagnik Majumder1 and Kristen Grauman1,2 |
|
1UT Austin,2Facebook AI Research Accepted at ECCV 2022. |
|
|
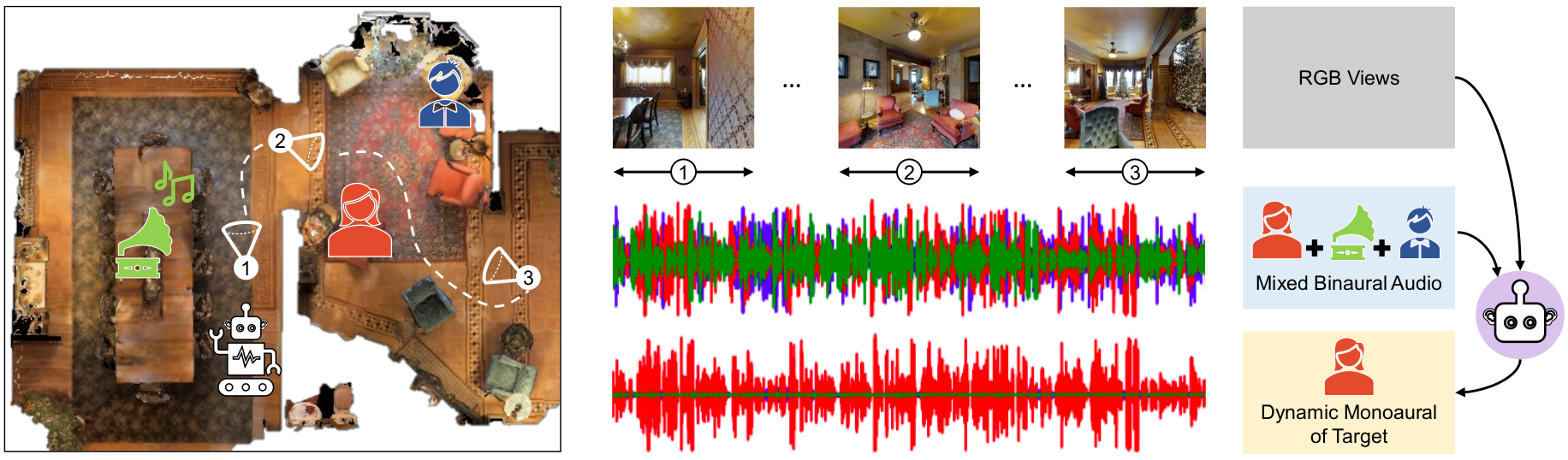
| We explore active audio-visual separation for dynamic sound sources, where an embodied agent moves intelligently in a 3D environment to continuously isolate the time-varying audio stream being emitted by an object of interest. The agent hears a mixed stream of multiple time-varying audio sources (e.g., multiple people conversing and a band playing music at a noisy party). Given a limited time budget, it needs to extract the target sound using egocentric audio-visual observations. We propose a reinforcement learning agent equipped with a novel transformer memory that learns motion policies to control its camera and microphone to recover the dynamic target audio, using self-attention to make high-quality estimates for current timesteps and also simultaneously improve its past estimates. Using highly realistic acoustic SoundSpaces simulations in real-world scanned Matterport3D environments, we show that our model is able to learn efficient behavior to carry out continuous separation of a time-varying audio target. |
|
Simulation demos and navigation examples.
|
|
|
@article{majumder2022active,
title={Active Audio-Visual Separation of Dynamic Sound Sources},
author={Majumder, Sagnik and Grauman, Kristen},
journal={arXiv preprint arXiv:2202.00850},
year={2022}
}
|
| Thank you to Ziad Al-Halah for very valuable discussions. Thanks to Tushar Nagarajan, Kumar Ashutosh and David Harwarth for feedback on paper drafts. UT Austin is supported in part by DARPA L2M, NSF CCRI, and the IFML NSF AI Institute. K.G. is paid as as a research scientist by Meta. |
| Copyright © 2022 University of Texas at Austin |