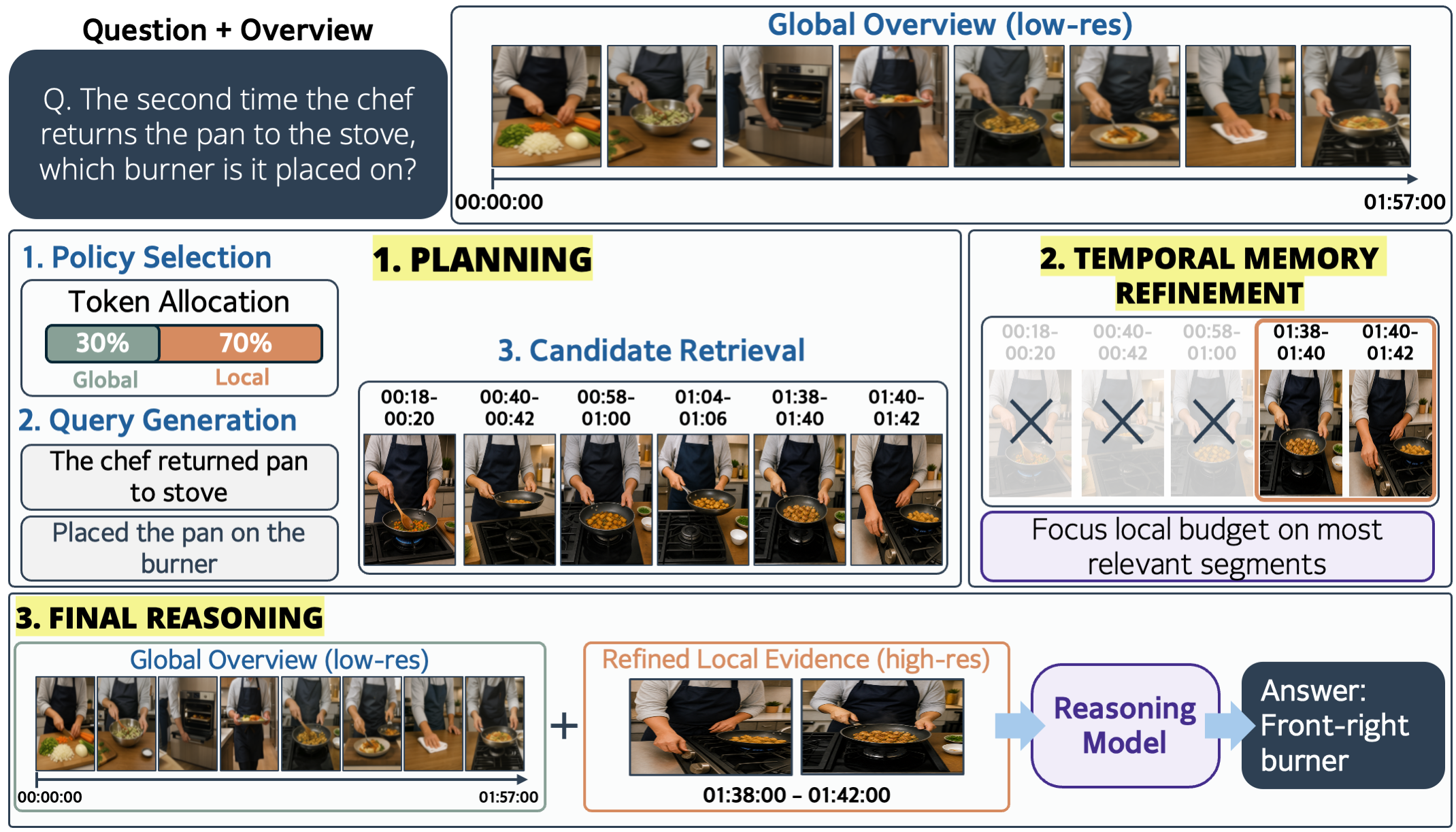
We propose AdaAlloc, a training-free long-video question answering framework that adaptively allocates fixed visual-token budgets between global temporal coverage and high-resolution local evidence through overview-conditioned planning, temporal grounding, and refined temporal memory, enabling precise and efficient reasoning over minute- to hour-long videos.
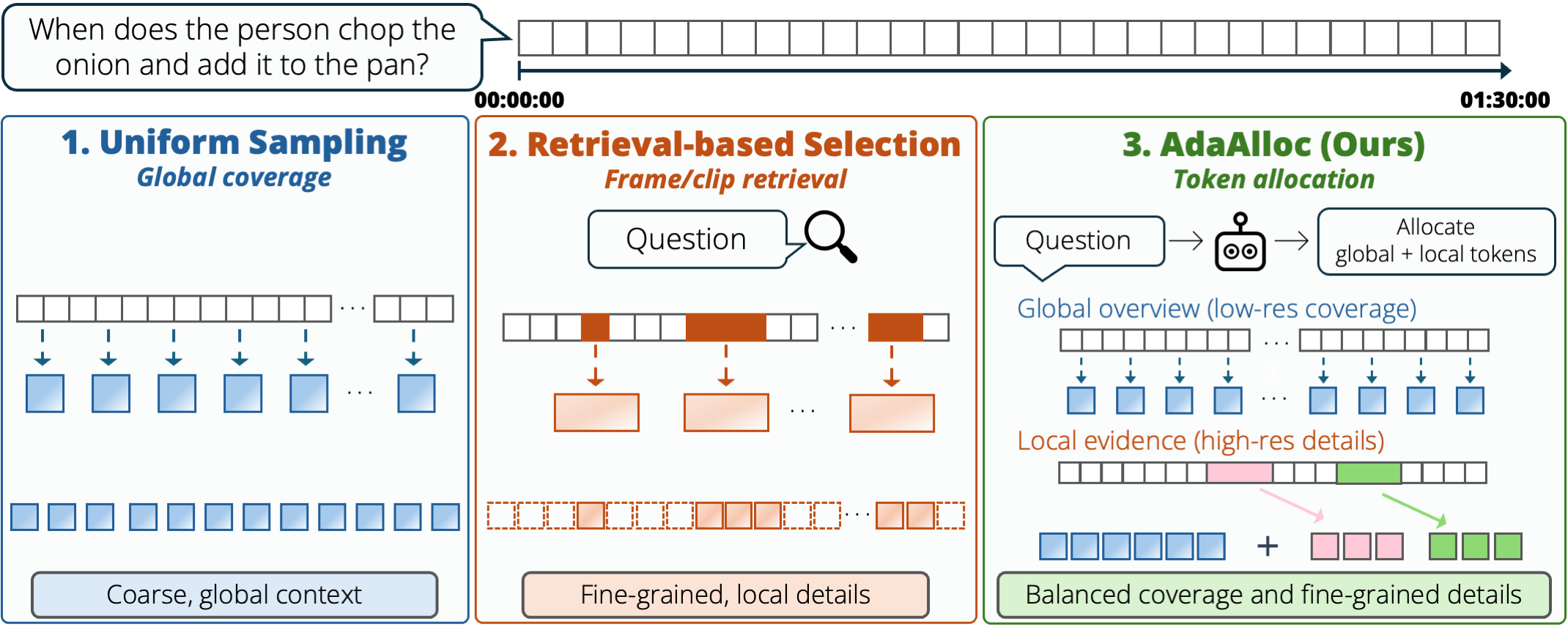
Visual token allocation for long-video reasoning. Uniform sampling preserves global coverage but loses fine details, while retrieval-based selection focuses on a few clips but can lose context. AdaAlloc allocates a fixed token budget between low-resolution global coverage and high-resolution local evidence for both context and fine-grained verification.