|
Sagnik Majumder1,2,3,
Hao Jiang2,
Pierre Moulon2,
Ethan Henderson2, Paul Calamia2, Kristen Grauman1,3*, Vamsi Krishna Ithapu2*, |
|
1UT Austin,2Reality Labs Research at Meta, 3FAIR at Meta * Equal contribution Accepted to CVPR 2023 |
|
|
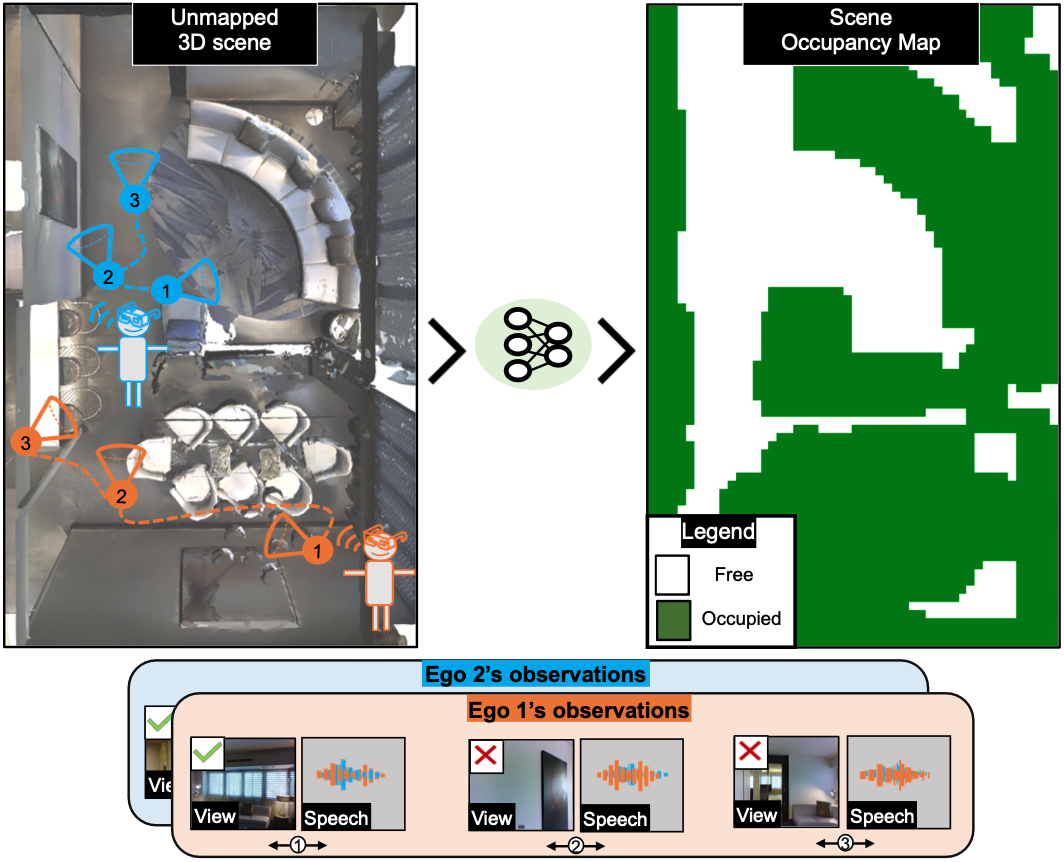
| Can conversational videos captured from multiple egocentric viewpoints reveal the map of a scene in a cost-efficient way? We seek to answer this question by proposing a new problem: efficiently building the map of a previously unseen 3D environment by exploiting shared information in the egocentric audio-visual observations of participants in a natural conversation. Our hypothesis is that as multiple people ("egos") move in a scene and talk among themselves, they receive rich audio-visual cues that can help uncover the unseen areas of the scene. Given the high cost of continuously processing egocentric visual streams, we further explore how to actively coordinate the sampling of visual information, so as to minimize redundancy and reduce power use. To that end, we present an audio-visual deep reinforcement learning approach that works with our shared scene mapper to selectively turn on the camera to efficiently chart out the space. We evaluate the approach using a state-of-the-art audio-visual simulator for 3D scenes as well as real-world video. Our model outperforms previous state-of-the-art mapping methods, and achieves an excellent cost-accuracy tradeoff. |
|
Task description, prediction examples and failure cases.
|
|
|
@inproceedings{majumder2023chat2map,
title={Chat2Map: Efficient Scene Mapping from Multi-Ego Conversations},
author={Majumder, Sagnik and Jiang, Hao and Moulon, Pierre and Henderson, Ethan and Calamia, Paul and Grauman, Kristen and Ithapu, Vamsi Krishna},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10554--10564},
year={2023}
}
|
| (1) Senthil Purushwalkam, Sebastia Vincenc Amengual Gari, Vamsi Krishna Ithapu, Carl Schissler, Philip Robinson, Abhinav Gupta, Kristen Grauman. Audio-Visual Floorplan Reconstruction. In ICCV 2021 [Bibtex] |
| (2) Santhosh K. Ramakrishnan, Ziad Al-Halah, Kristen Grauman. Occupancy Anticipation fo Efficient Exploration and Navigation. In ECCV 2020 [Bibtex] |
| (3) Changan Chen*, Unnat Jain*, Carl Schissler, Sebastia Vicenc Amengual Gari, Ziad Al-Halah, Vamsi Krishna Ithapu, Philip Robinson, Kristen Grauman. SoundSpaces: Audio-Visual Navigation in 3D Environments. In ECCV 2020 [Bibtex] |
| (4) Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, Yinda Zhang. Matterport3D: Learning from RGB-D Data in Indoor Environments. In 3DV 2017 [Bibtex] |
| (5) Vassil Panayotov, Guoguo Chen, Daniel Povey, Sanjeev Khudanpur. Librispeech: An ASR corpus based on public domain audio books. In ICASSP 2015 [Bibtex] |
| Copyright © 2022 University of Texas at Austin |