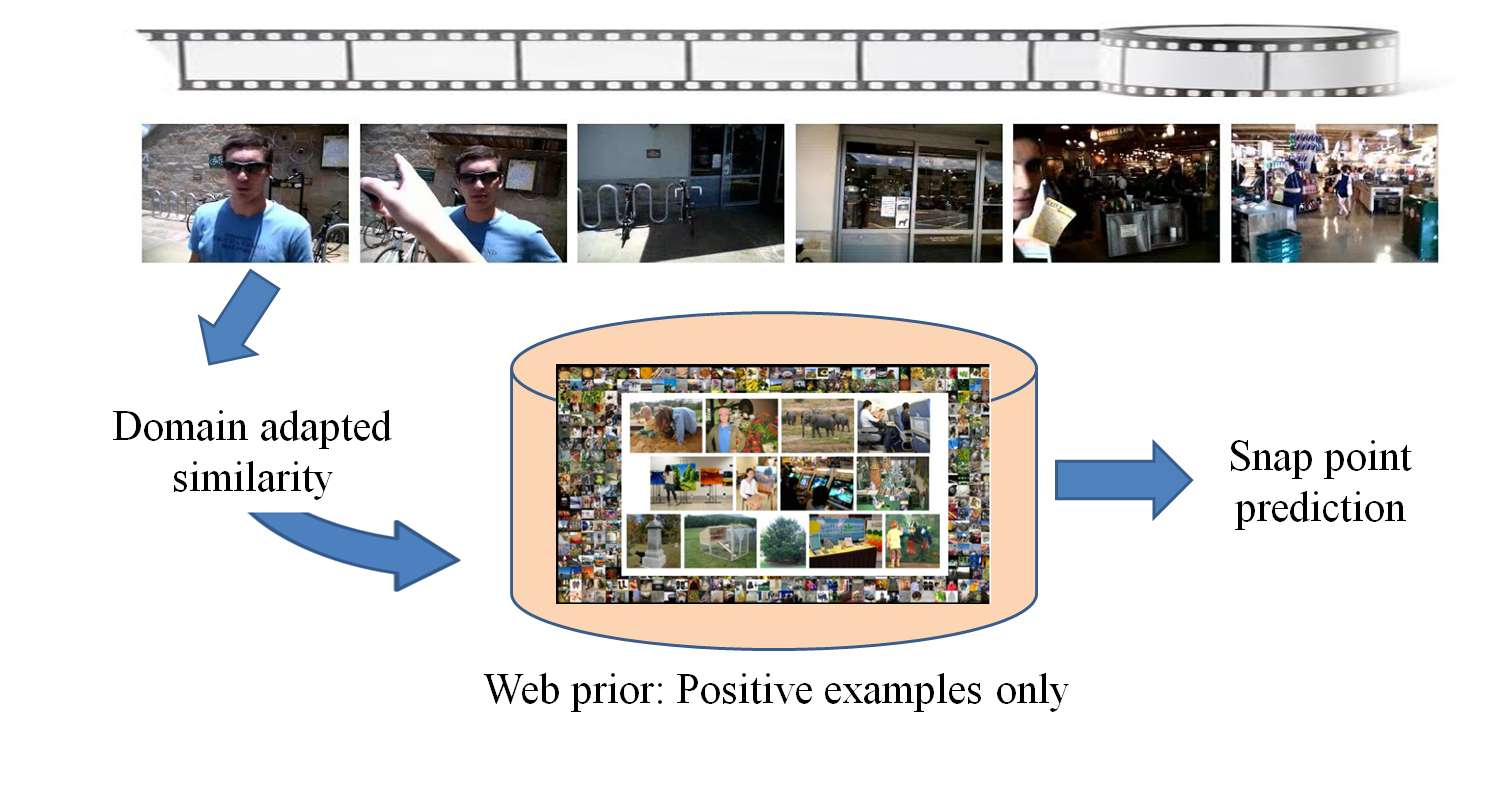
Wearable cameras capture a first-person view of the world,
and offer a hands-free way to record daily experiences or special events.
Yet, not every frame is worthy of being captured and stored. We propose
to automatically predict “snap points” in unedited egocentric video—
that is, those frames that look like they could have been intentionally
taken photos. We develop a generative model for snap points that relies
on a Web photo prior together with domain-adapted features. Critically,
our approach avoids strong assumptions about the particular content of
snap points, focusing instead on their composition. Using 17 hours of
egocentric video from both human and mobile robot camera wearers,
we show that the approach accurately isolates those frames that human
judges would believe to be intentionally snapped photos. In addition,
we demonstrate the utility of snap point detection for improving object
detection and keyframe selection in egocentric video.
What is new
We have released a new version of the code!
Demo Video
We show a demo video of snap point detection with both predicted and ground truth snap point qualities.
Overview
Problem: Can a vision system predict “snap points” in unedited egocentric video—that is, those frames that look like intentionally taken photos?
Challenges:
1) Egocentric video contains a wide variety of scene types, activities, and actors. This is certainly true for human camera wearers going about daily life activities, and it will be increasingly true for mobile robots that freely explore novel environments. 2) An optimal snap point is likely to differ in subtle ways from its less-good temporal neighbors, i.e., two frames may be similar in content but distinct in terms of snap point quality. 3) It is burdensome to obtain adequate and unbiased labeled data.
Our Approach
Overview:
We introduce an approach to detect snap points from egocentric video that
requires no human annotations. The main idea is to construct a generative model
of what human-taken photos look like by sampling images posted on the Web.
Web Photo Prior
We select the SUN Database as our Web photo source [Xiao et al.], which originates from Internet search for hundreds of scene category names.
Image Descriptors
To represent each image, we designate descriptors to capture intentional composition effects.
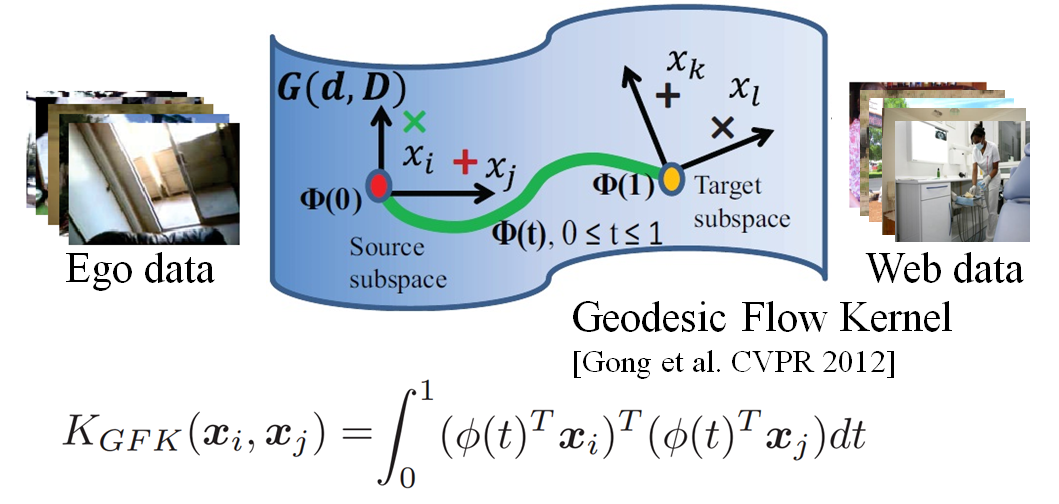
Domain-adapted Similarity
Applications
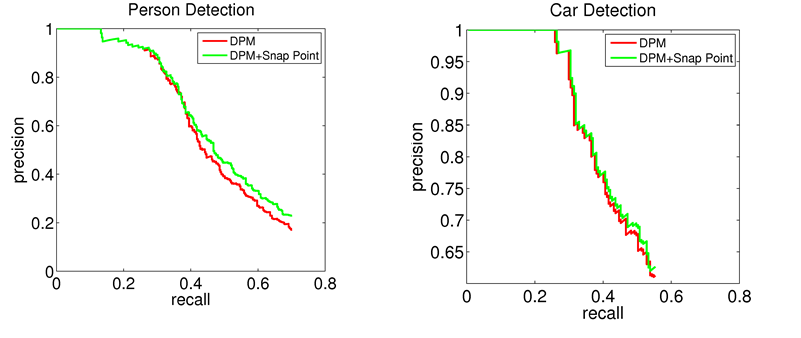
Object Detection
Standard object detectors do not generalize well on egocentric videos. We can use snap points to predict where a standard object is trustworthy.
Keyframe Selection
First, we identify temporal event segments using the color- and time-based grouping method, which finds chunks of frames likely to belong to the same physical location or scene. Then, for each such event, we select the frame most confidently scored as a snap point.
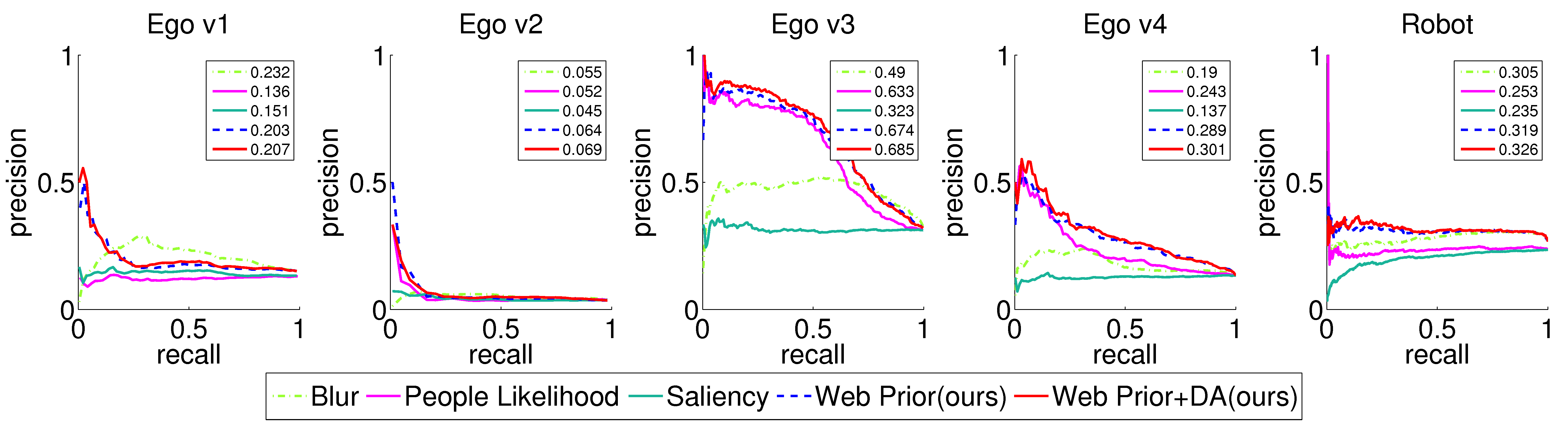
Results
Snap Points Accuracy
We use UT Egocentric Dataset and Robotc Egocentric Video. which is newly collected. We compare our method with the following baselines:
Saliency: uses the CRF-based saliency method to score an
image. This baseline reflects that people tend to compose images with a
salient object in the center.
Blurriness: uses the blur estimates to score an image. It reflects
that intentionally taken images tend to lack motion blur.
People likelihood: uses a person detector to rank each frame by how likely
it is to contain one or more people.
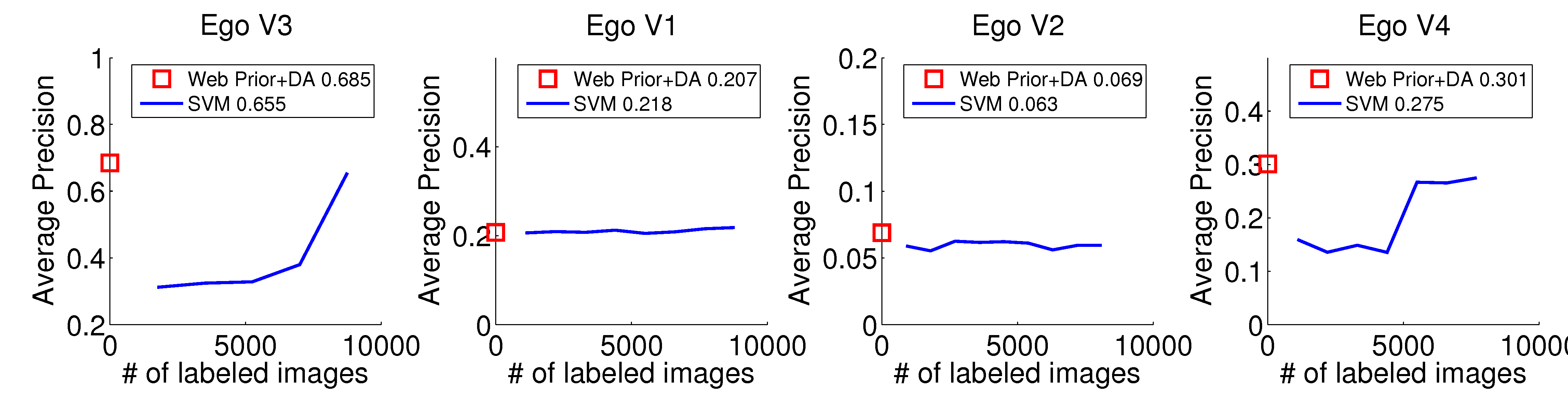
Discriminative SVM: uses a RBF kernel SVM trained with the ground
truth snap points/non-snap points in the Ego data.
Unsupervised Baselines
Supervised Baseline
Examples Snap Points Detection
Object Detection:
We see that snap points improve the precision of the standard DPM detector, since they let us ignore frames where the detector is not trustworthy.
Keyframe Selection:
Downloads
You can download the dataset using the links below:
@InProceedings{snap-points, author = {B. Xiong and K. Grauman}, title = {Detecting Snap Points in Egocentric Video with a Web Photo Prior}, booktitle = {ECCV}, month = {September}, year = {2014} }