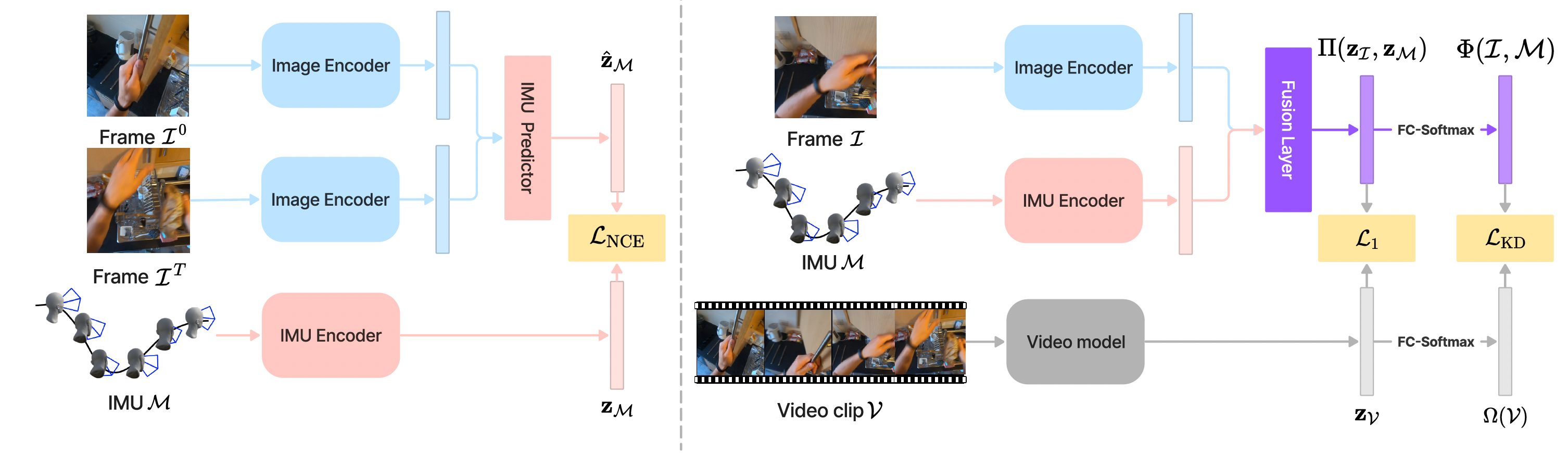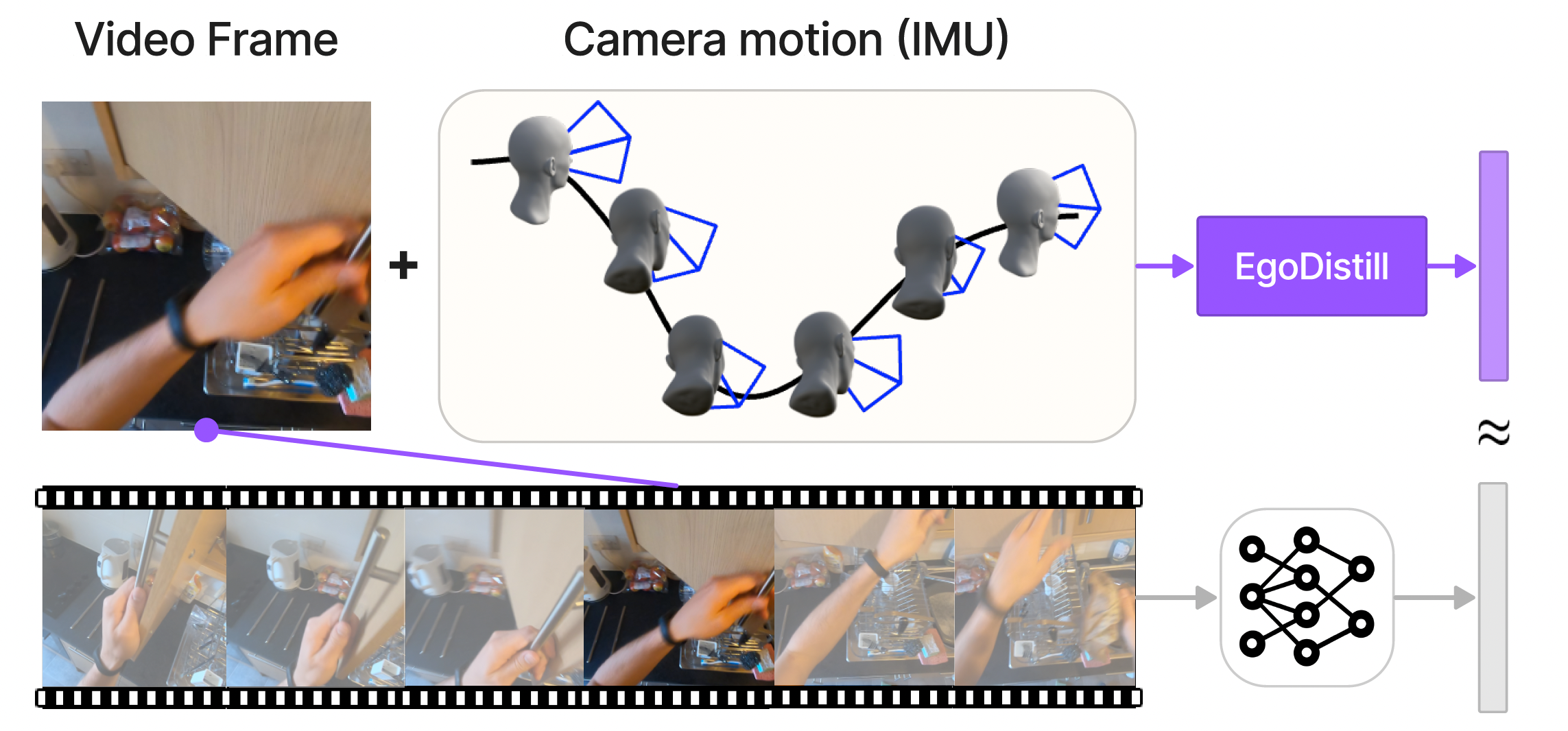
Recent advances in egocentric video understanding models are promising, but their heavy computational expense is a barrier for many real-world applications. To address this challenge, we propose EgoDistill, a distillation-based approach that learns to reconstruct heavy egocentric video clip features by combining the semantics from a sparse set of video frames with the head motion from lightweight IMU readings. We further devise a novel self-supervised training strategy for IMU feature learning. Our method leads to significant improvements in efficiency, requiring 200x fewer GFLOPs than equivalent video models. We demonstrate its effectiveness on the Ego4D and EPICKitchens datasets, where our method outperforms state-ofthe- art efficient video understanding methods.