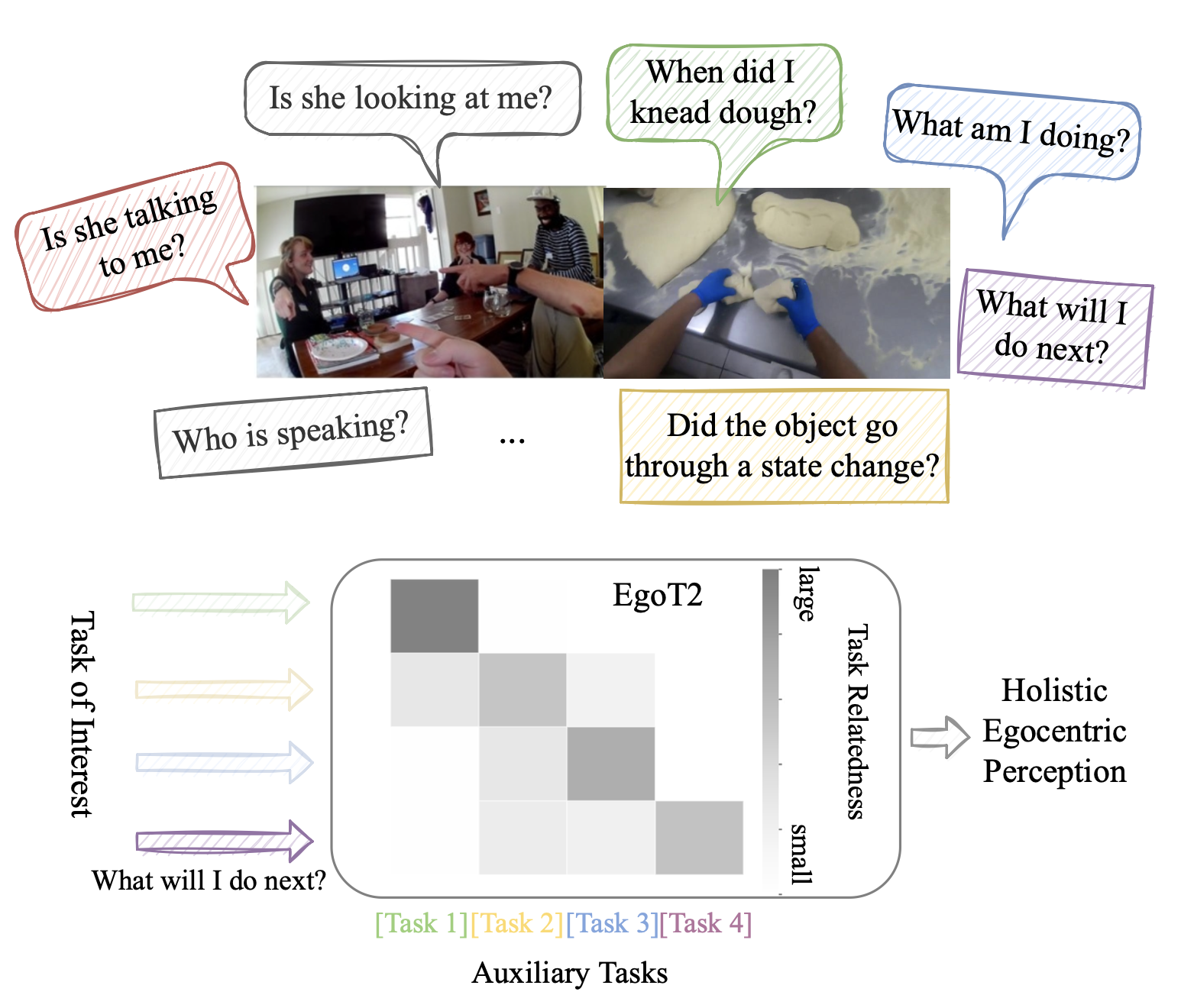
Different video understanding tasks are typically treated in isolation, and even with distinct types of curated data (e.g., classifying sports in one dataset, tracking animals in another). However, in wearable cameras, the immersive egocentric perspective of a person engaging with the world around them presents an interconnected web of video understanding tasks—hand-object manipulations, navigation in the space, or human-human interactions—that unfold continuously, driven by the person’s goals. We argue that this calls for a much more unified approach.
We propose EgoTask Translation (EgoT2), which takes a collection of models optimized on separate tasks and learns to translate their outputs for improved performance on any or all of them at once. Unlike traditional transfer or multi-task learning, EgoT2’s “flipped design” entails separate task-specific backbones and a task translator shared across all tasks, which captures synergies between even heterogeneous tasks and mitigates task competition. Demonstrating our model on a wide array of video tasks from Ego4D, we show its advantages over existing transfer paradigms and achieve top-ranked results on four of the Ego4D 2022 benchmark challenges.
We propose two variants, EgoT2-s (left) and EgoT2-g (right). EgoT2-s learns to "translate" auxiliary task features into predictions for the primary task and EgoT2-g conducts task translation for multiple tasks at the same time.
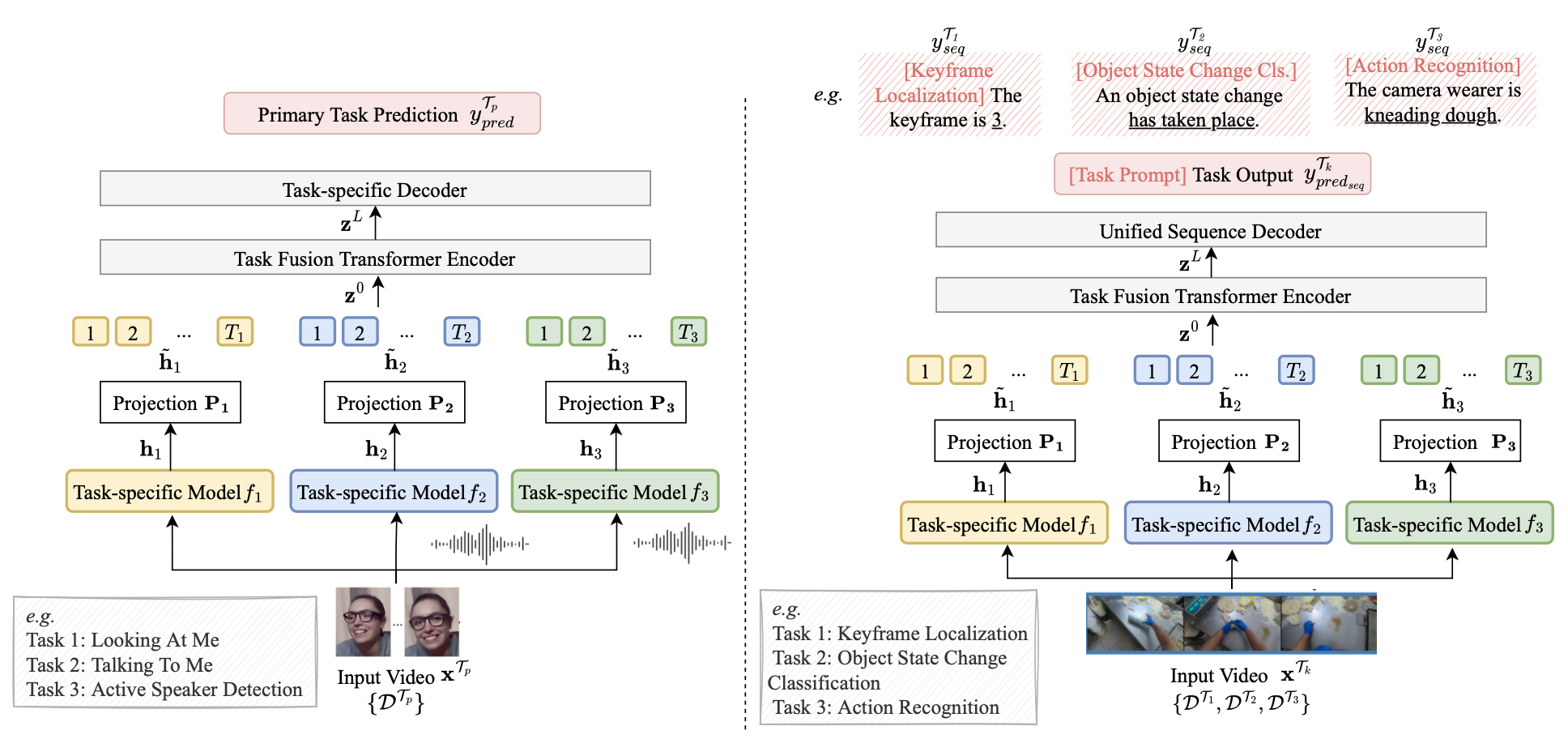
EgoT2-s: How auxiliary tasks contribute to the primary task prediction?
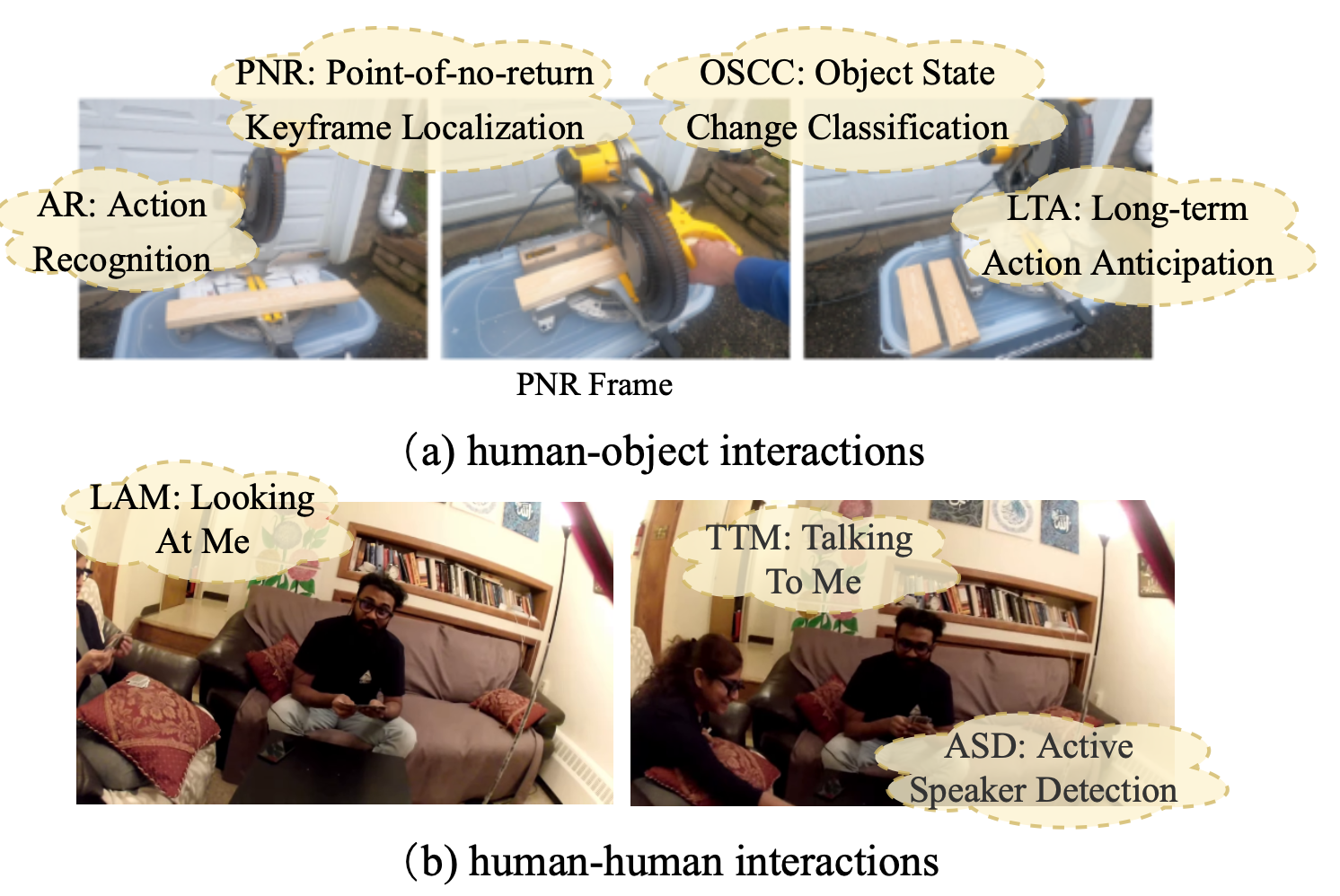
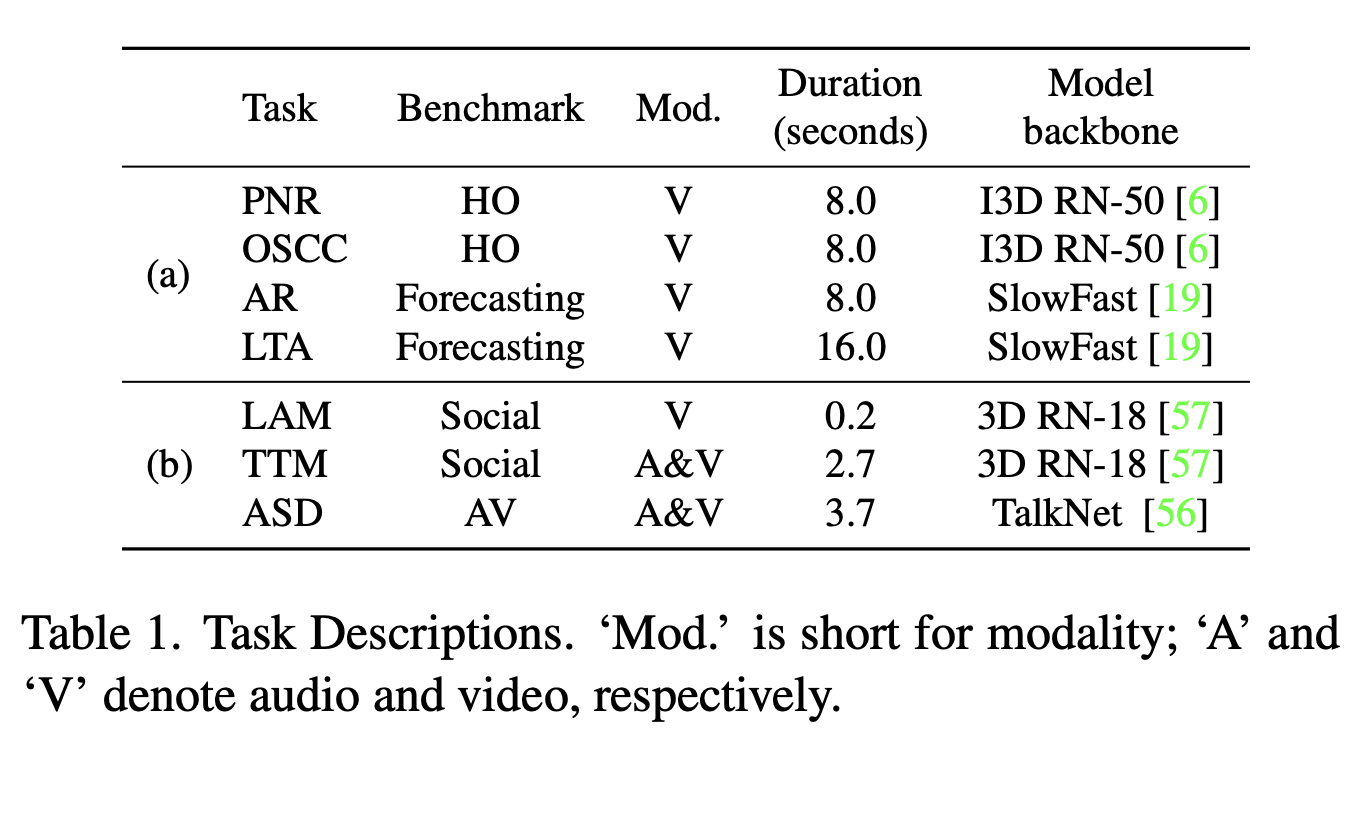
(A) Task of interest is TTM (talking-to-me classificiation), auxiliary tasks are LAM (looking-at-me classification) and ASD (active speaker detection)

Eye contact → LAM weights increase

Camera moves → LAM weights become large when the face is evident

Wrong bounding box (no face) → small attention weights
(B) Task of interest is LTA (long-term action anticipation, i.e., predicting future actions), auxiliary task is action recognition (AR, i.e., predicting current actions).

Action sequence: put wheel → take container → put container
AR tokens have large weights when the current action is indicative of future actions → We observe larger AR weights after the scene change.

operate computer → operate computer → operate computer
The video is temporally similar & current action provides strong cues for the next action → We observe similar AR & LTA weights.
EgoT2-g: How task features tokens get selectively activated?
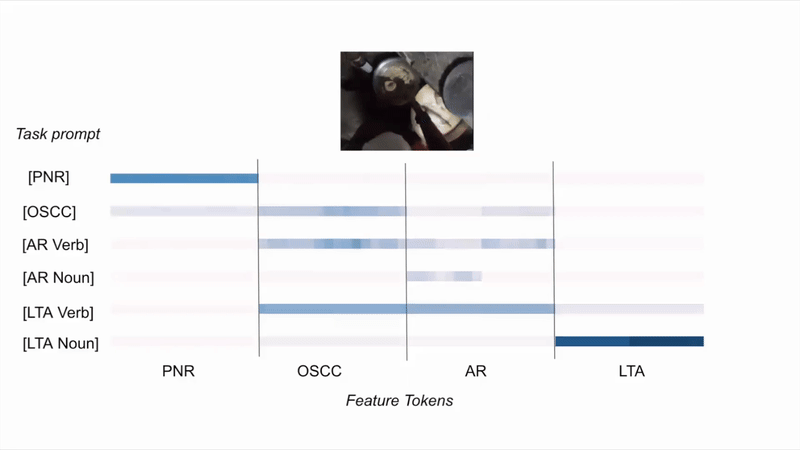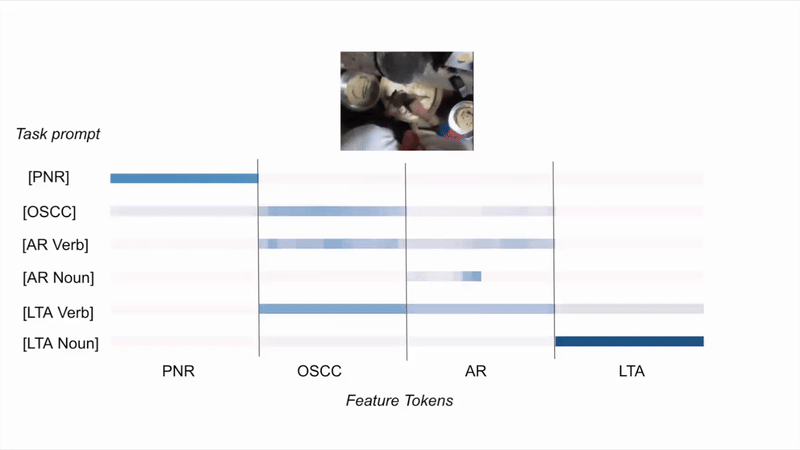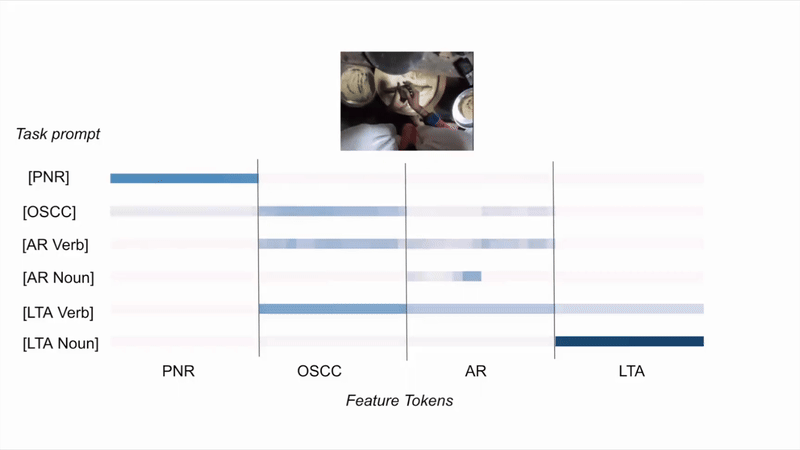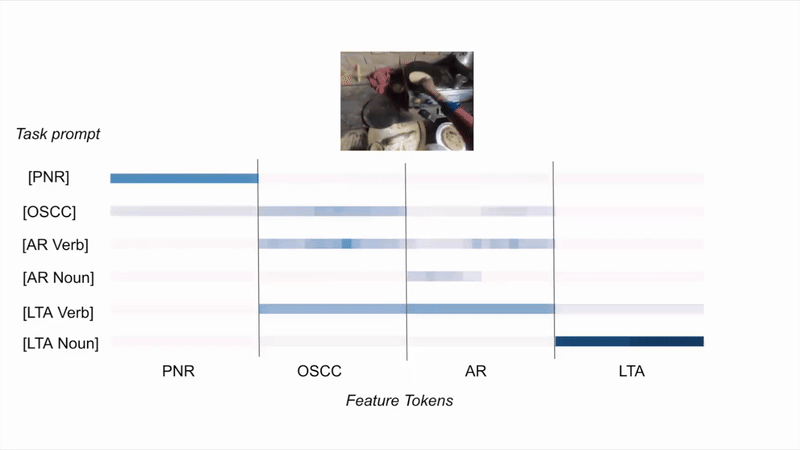
(A) Given the same video and different task prompts, EgoT2-g activates task tokens differently.

(B) Given different videos and the same task prompt, EgoT2-g activates task tokens differently.
@inproceedings{xue2023egot2,
title={Egocentric Video Task Translation},
author={Xue, Zihui and Song, Yale and Grauman, Kristen and Torresani, Lorenzo},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={2310--2320},
year={2023}
}
@article{xue2023egocentric,
title={Egocentric Video Task Translation@ Ego4D Challenge 2022},
author={Xue, Zihui and Song, Yale and Grauman, Kristen and Torresani, Lorenzo},
journal={arXiv preprint arXiv:2302.01891},
year={2023}
}