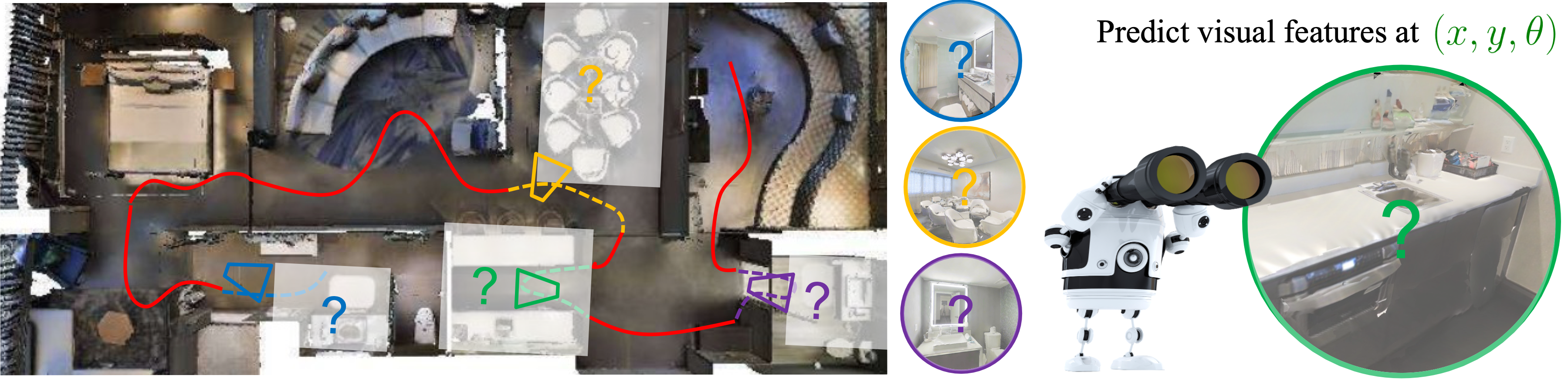
We introduce environment predictive coding, a self-supervised approach to learn environment-level representations for embodied agents. In contrast to prior work on self-supervised learning for individual images, we aim to encode a 3D environment using a series of images observed by an agent moving in it. We learn these representations via a masked-zone prediction task, which segments an agent’s trajectory into zones and then predicts features of randomly masked zones, conditioned on the agent’s camera poses. This explicit spatial conditioning encourages learning representations that capture the geometric and semantic regularities of 3D environments. We learn such representations on a collection of video walkthroughs and demonstrate successful transfer to multiple downstream navigation tasks. Our experiments on the real-world scanned 3D environments of Gibson and Matterport3D show that our method obtains 2 - 6× higher sample-efficiency and up to 57% higher performance over standard image-representation learning.
Source code and pretrained models
Code to reproduce our results along with pre-trained models are available now on GitHub.
Citation
@inproceedings{
ramakrishnan2022environment,
title={Environment Predictive Coding for Visual Navigation},
author={Santhosh Kumar Ramakrishnan and Tushar Nagarajan and Ziad Al-Halah and Kristen Grauman},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=DBiQQYWykyy}
}
Acknowledgements
UT Austin is supported in part by the IFML NSF AI Institute, the FRL Cognitive Science Consortium, and DARPA Lifelong Learning Machines. We thank members of the UT Austin Vision Lab for feedback on the project. We thank Dhruv Batra for feedback on the paper draft. We thank the ICLR reviewers and meta-reviewers for their valuable feedback and suggestions.