| Arjun Somayazulu1, Kristen Grauman1 |
|
1UT Austin |
|
|
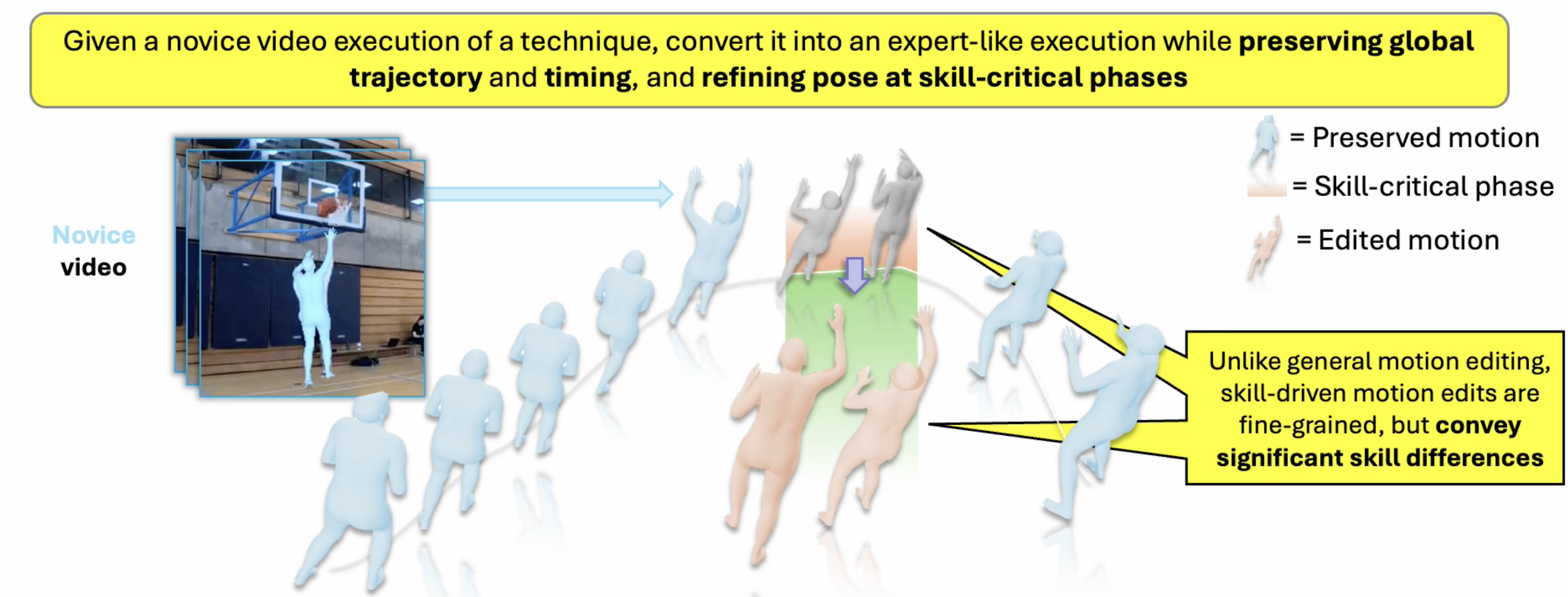
| Visual feedback is critical for motor skill acquisition in sports and rehabilitation, and psychological studies show that observing near-perfect versions of one’s own performance accelerates learning more effectively than watching expert demonstrations alone. We propose to enable such personalized feedback by automatically editing a person’s motion to reflect higher skill. Existing motion editing approaches are poorly suited for this setting because they assume paired input-output data—rare and expensive to curate for skill-driven tasks—and explicit edit guidance at inference. We introduce ExpertEdit, a framework for skill-driven motion editing trained exclusively on unpaired expert video demonstrations. ExpertEdit learns an expert motion prior with a masked language modeling objective that infills masked motion spans with expert-level refinements. At inference, novice motion is masked at skill-critical moments and projected into the learned expert manifold, producing localized skill improvements without paired supervision or manual edit guidance. Across eight diverse techniques and three sports from Ego-Exo4D and Karate Kyokushin, ExpertEdit outperforms state-of-the-art supervised motion editing methods on multiple metrics of motion realism and expert quality. |
|
|
|
If you find this work useful, please cite:
@misc{somayazulu2026experteditlearningskillawaremotion,
title={ExpertEdit: Learning Skill-Aware Motion Editing from Expert Videos},
author={Arjun Somayazulu and Kristen Grauman},
year={2026},
eprint={2604.10466},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.10466},
}
|
| Copyright © 2026 The University of Texas at Austin |