Foreground Focus: Finding Meaningful
Features in Unlabeled Images
Yong Jae Lee and
Kristen Grauman

Summary
We present a method
to automatically discover meaningful features in unlabeled image collections.
Each image is decomposed into semi-local features that describe neighborhood
appearance and geometry. The goal is to determine for each image which of these
parts are most relevant, given the image content in the remainder of the
collection. Our method first computes an initial image-level grouping based on
feature correspondences, and then iteratively refines cluster assignments based
on the evolving intra-cluster pattern of local matches. As a result, the
significance attributed to each feature influences an image’s cluster
membership, while related images in a cluster affect the estimated significance
of their features. We show that this mutual reinforcement of object-level and
feature-level similarity improves unsupervised image clustering, and apply the
technique to automatically discover categories and foreground regions in images
from benchmark datasets.
System Overview
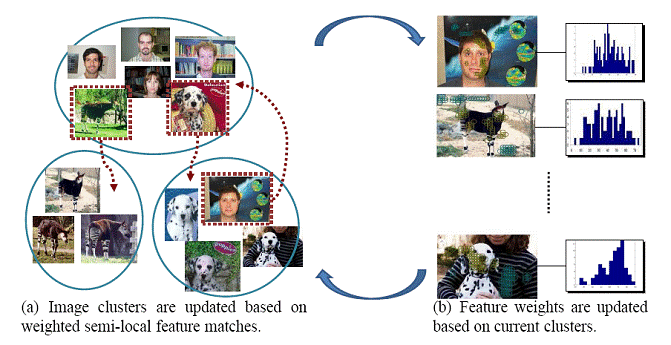
The
images are grouped based on weighted semilocal
feature matchings (a), and then image-specific
feature weights are adjusted based on their contribution in the match relative
to all other intra-cluster images (b). These two processes are iterated (as
denoted by the block arrows in the center) to simultaneously determine
foreground features while improving cluster quality. Dotted arrows denote
images with updated cluster memberships.
Evaluation
We
performed experiments both to analyze the mutual reinforcement of foreground
and clusters, and to compare against existing unsupervised methods. We work
with images from the Caltech-101, because the dataset
provides object segmentations that we need as ground truth to evaluate our
foreground detection. We formed a
four-class (Faces, Dalmatians, Hedgehogs, and Okapi) and 10-class (previous
four plus Leopards, Car side, Cougar face, Guitar, Sunflower, and Wheelchair)
set. For each class, we use the first 50 images.
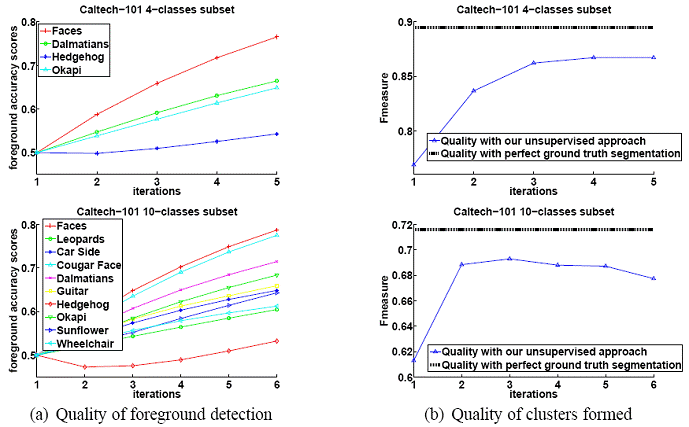
If
our algorithm correctly identifies the important features, we expect those
features to lie on the foreground objects since that
is what primarily re-occurs in these datasets. To evaluate this, we compare the
feature weights computed by our method with the ground truth list of foreground
features. We quantify accuracy by the percentage of total feature weight in an
image that our method attributes to true foreground features.
As
our method weights foreground features more highly, we also expect a positive
effect on cluster quality. Since we know the true labels of each image, we can
use the F-measure to measure cluster homogeneity.
Publication
Foreground
Focus: Finding Meaningful Features in Unlabeled Images [pdf]
[slides
(ppt)]
Yong Jae Lee and Kristen Grauman
In Proceedings of the 19th British Machine Vision Conference (BMVC), Leeds,
U.K., September 2008.