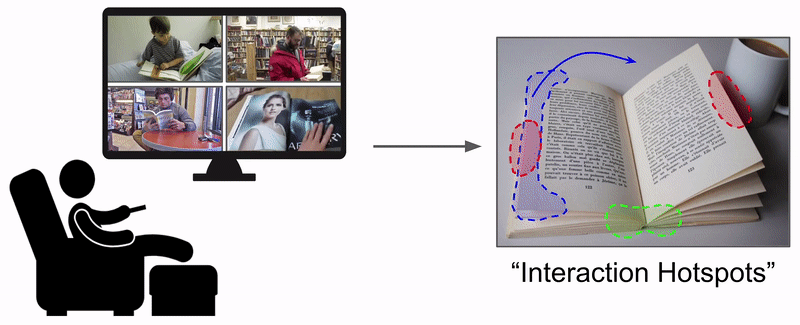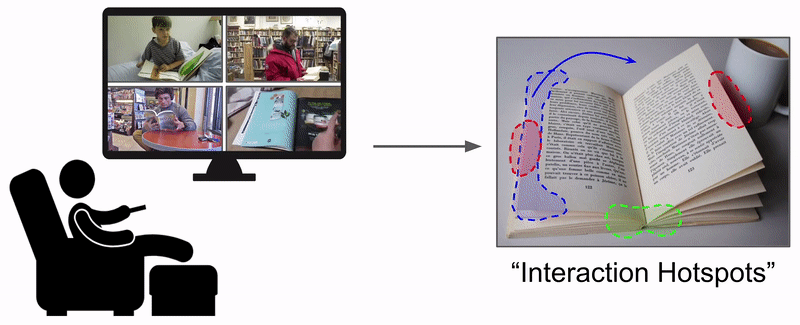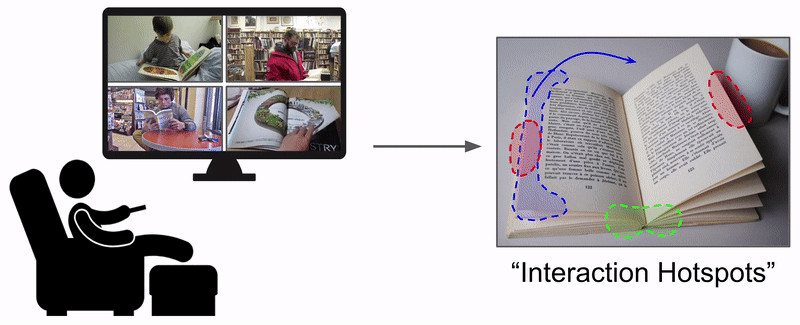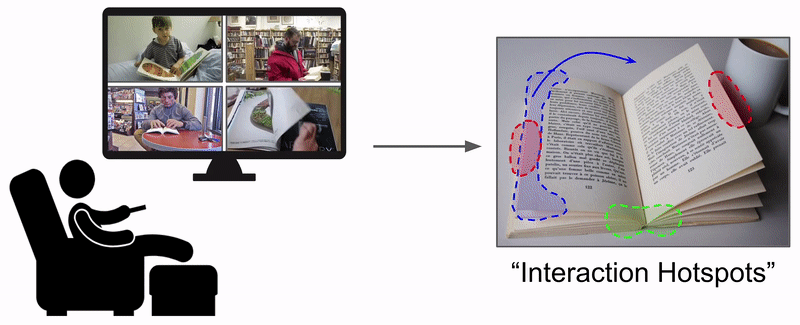
Learning how to interact with objects is an important step towards embodied visual intelligence, but existing techniques suffer from heavy supervision or sensing requirements. We propose an approach to learn human-object interaction "hotspots" directly from video. Rather than treat affordances as a manually supervised semantic segmentation task, our approach learns about interactions by watching videos of real human behavior and anticipating afforded actions. Given a novel image or video, our model infers a spatial hotspot map indicating how an object would be manipulated in a potential interaction---even if the object is currently at rest. Through results with both first and third person video, we show the value of grounding affordances in real human-object interactions. Not only are our weakly supervised hotspots competitive with strongly supervised affordance methods, but they can also anticipate object interaction for novel object categories.
If you find this work useful in your own research, please consider citing:
@inproceedings{interaction-hotspots,
author = {Nagarajan, Tushar and Feichtenhofer, Christoph and Grauman, Kristen},
title = {Grounded Human-Object Interaction Hotspots from Video},
booktitle = {ICCV},
year = {2019}
}