State-of-the-art approaches to ObjectGoal navigation rely on reinforcement learning and typically require significant computational resources and time for learning. We propose Potential functions for ObjectGoal Navigation with Interaction-free learning (PONI), a modular approach that disentangles the skills of 'where to look?' for an object and 'how to navigate to (x, y)?'. Our key insight is that 'where to look?' can be treated purely as a perception problem, and learned without environment interactions. To address this, we propose a network that predicts two complementary potential functions conditioned on a semantic map and uses them to decide where to look for an unseen object. We train the potential function network using supervised learning on a passive dataset of top-down semantic maps, and integrate it into a modular framework to perform ObjectGoal navigation. Experiments on Gibson and Matterport3D demonstrate that our method achieves the state-of-the-art for ObjectGoal navigation while incurring up to 1,600x less computational cost for training.
Potential Functions for ObjectNav with Interaction-free Learning
In this work, we introduce PONI, a new paradigm for learning modular ObjectNav policies that disentangle the object search skill (i.e., where to look for an object) and the navigation skill (i.e., how to navigate to (x, y)). Our key insight is that the object search skill can be treated purely as a perception problem and learned without interactions. We address this problem by defining a potential function, which is [0, 1]-valued function that represents the value of visiting each location in order to find the object. Given the potential function, we can simply select its argmax location to decide where to look for the object. We propose a potential function network that uses geometric and semantic cues from a partially filled semantic map to predict the potential function for the object of interest (e.g., a shower). We train this network in a non-interactive fashion on a dataset of semantic maps, and integrate it into a modular framework for performing ObjectGoal navigation.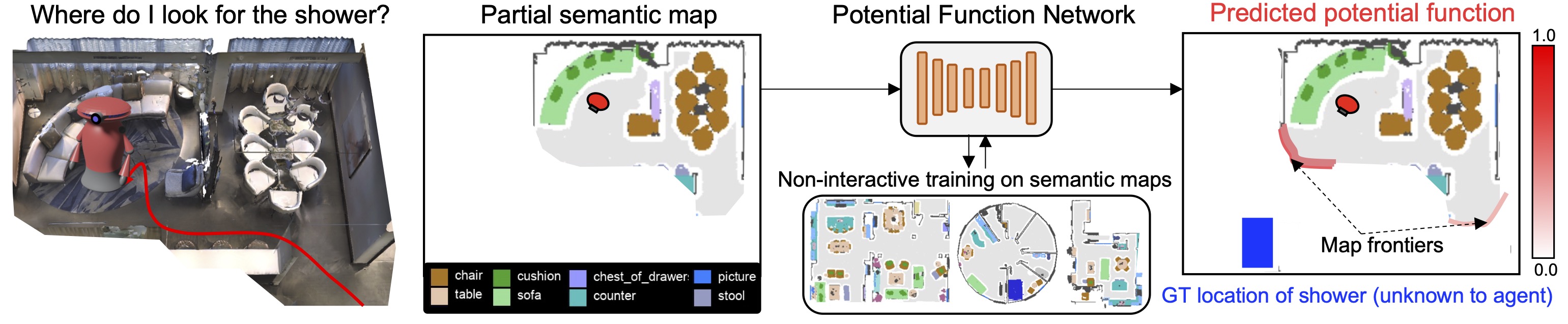
CVPR oral talk
Demos of ObjectNav using PONI
We show examples of intelligent object search behaviors exhibited by PONI. Each video consists of 3 panels. In the left panel, we show the agent's egocentric view, semantic map built by the agent, the goal category and time-steps taken by the agent in the episode. In the center panel, we show the predicted object potential function (in red) overlayed on the semantic map. In the right panel, we show the predicted area potential function (in red) overlayed on the semantic map.Source code and pretrained models
Code to reproduce our results along with pre-trained models are available now on GitHub.
Citation
@inproceedings{ramakrishnan2022poni,
author = {Ramakrishnan, Santhosh K. and Chaplot, Devendra Singh and Al-Halah, Ziad and Malik, Jitendra and Grauman, Kristen},
booktitle = {Computer Vision and Pattern Recognition (CVPR), 2022 IEEE Conference on},
title = {PONI: Potential Functions for ObjectGoal Navigation with Interaction-free Learning},
year = {2022},
organization = {IEEE},
}
Acknowledgements
UT Austin is supported in part by the IFML NSF AI Institute, the FRL Cog. Sci. Consortium, and DARPA L2M. We thank Vincent Cartiller for sharing image segmentation models for MP3D.