The goal in episodic memory (EM) is to search a long egocentric video to answer a natural language query (e.g., ``where did I leave my purse?"). Existing EM methods exhaustively extract expensive fixed-length clip features to look everywhere in the video for the answer, which is infeasible for long wearable camera videos that span hours or even days. We propose SpotEM, an approach to achieve efficiency for a given EM method while maintaining good accuracy. SpotEM consists of three key ideas: a novel clip selector that learns to identify promising video regions to search conditioned on the language query; a set of low-cost semantic indexing features that capture the context of rooms, objects, and interactions that suggest where to look; and distillation losses that address optimization issues arising from end-to-end joint training of the clip selector and EM model. Our experiments on 200+ hours of video from the Ego4D EM Natural Language Queries benchmark and three different EM models demonstrate the effectiveness of our approach: computing only 10%-25% of the clip features, we preserve 84%-95%+ of the original EM model's accuracy.
[PDF] [Poster] [SlidesLive recording] [Code]
Citation
@inproceedings{ramakrishnan2023spotem,
author = {Ramakrishnan, Santhosh K. and Al-Halah, Ziad and Grauman, Kristen},
booktitle = {International Conference on Machine Learning},
title = {SpotEM: Efficient Video Search for Episodic Memory},
year = {2023},
organization = {PMLR},
}
Episodic Memory
The episodic memory task was recently introduced as a benchmark in Ego4D. It aims to build augmented reality assistants that can preview the history of what a AR-device user has seen and answer their questions about the past (e.g., where did I leave my keys?), effectively enabling super-human memory. In this work, we focus on episodic memory using natural language queries, where a user can ask free-form natural language questions about long-form egocentric videos representing their visual history. This is a challenging task due to the long-form and egocentric nature of the videos, free-form nature of queries, and short responses that span a tiny fraction of the overall video (2% on average).Motivation
Standard episodic memory (EM) methods divide videos into fixed-length clips and perform costly processing of every clip. The processed clips are provided to an EM model for query-conditioned search. Exhaustively processing every video clip is costly and contributes to over 99.9% of the overall inference cost per query. This becomes intractable as the video length grows, especially for real-time applications where the on-board computation is severly restrictive. We propose SpotEM, a clip-selection approach that spots clips relevant to the query cheaply and selectively processes these clips to serve as inputs to the EM model.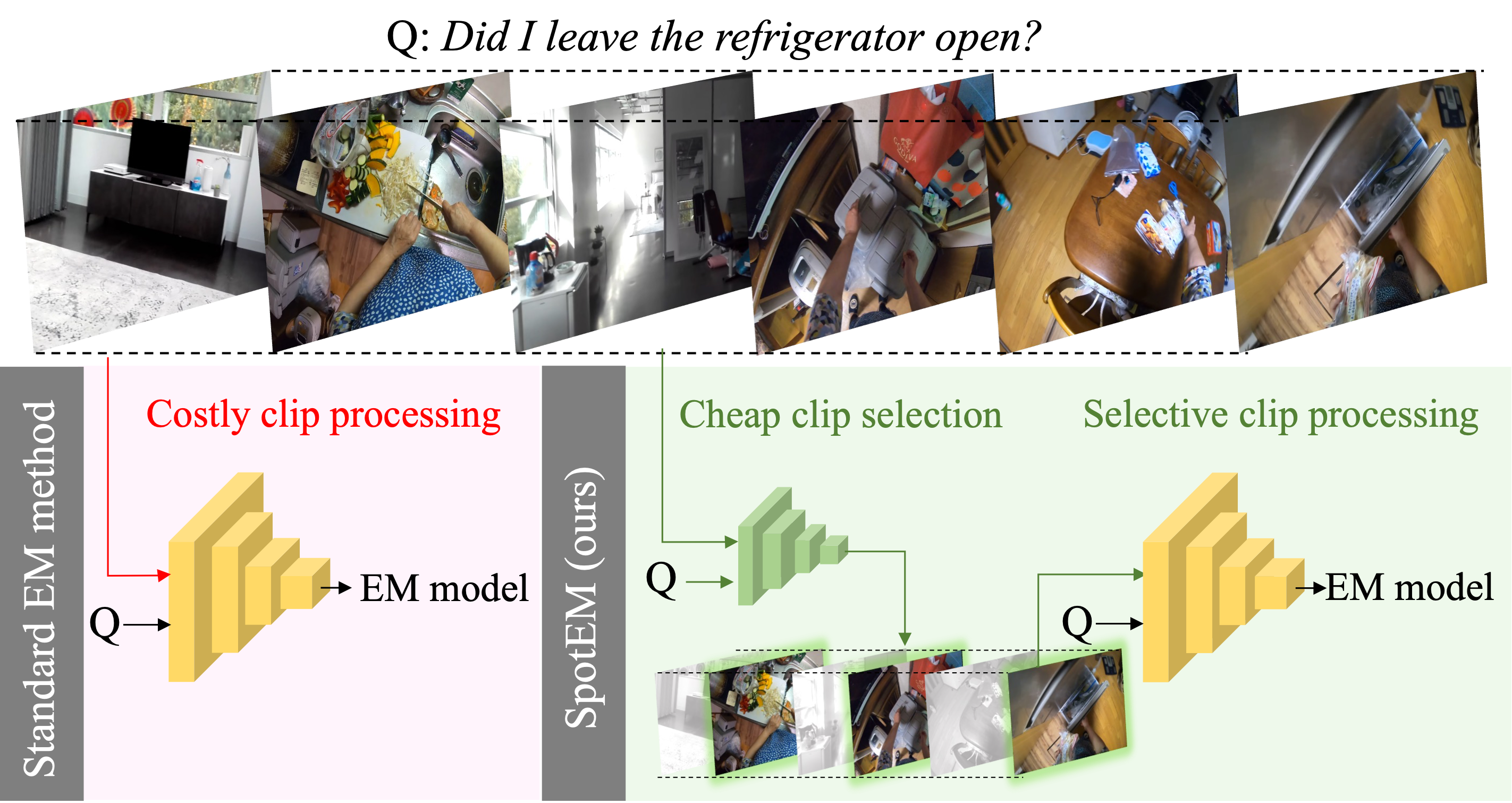
Visualizations
We visualize five success and two failure cases of SpotEM below. In each video, we visualize the clips selected by SpotEM at each step, highlight their relevance to the query (if any), and provide a textual description of SpotEM's behavior. Finally, we visualize the predicted and ground-truth responses.|
Success case #1 |
Success case #2 |
|---|---|
|
Success case #3 |
Success case #4 |
|
Success case #5 |
|
|
Failure case #1 |
Failure case #2 |