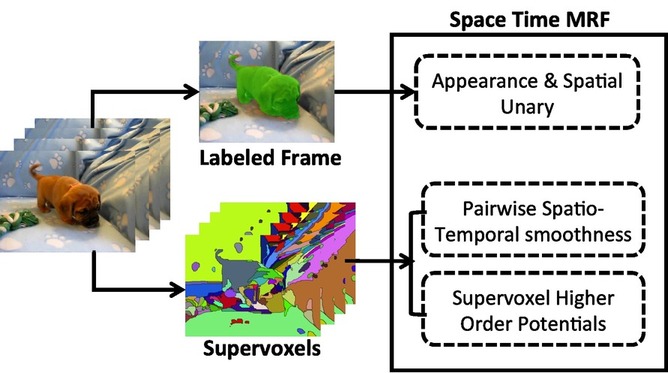
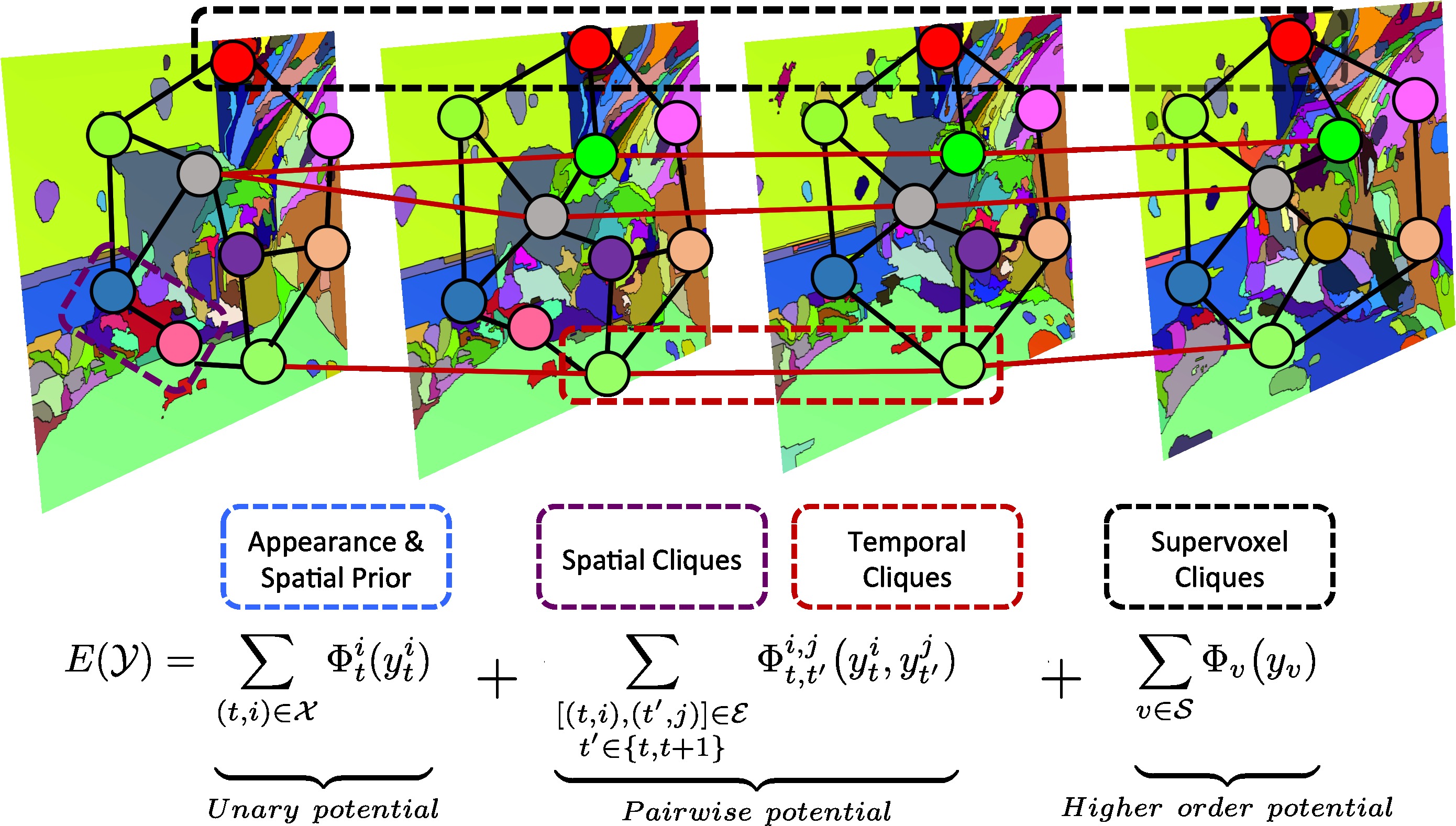
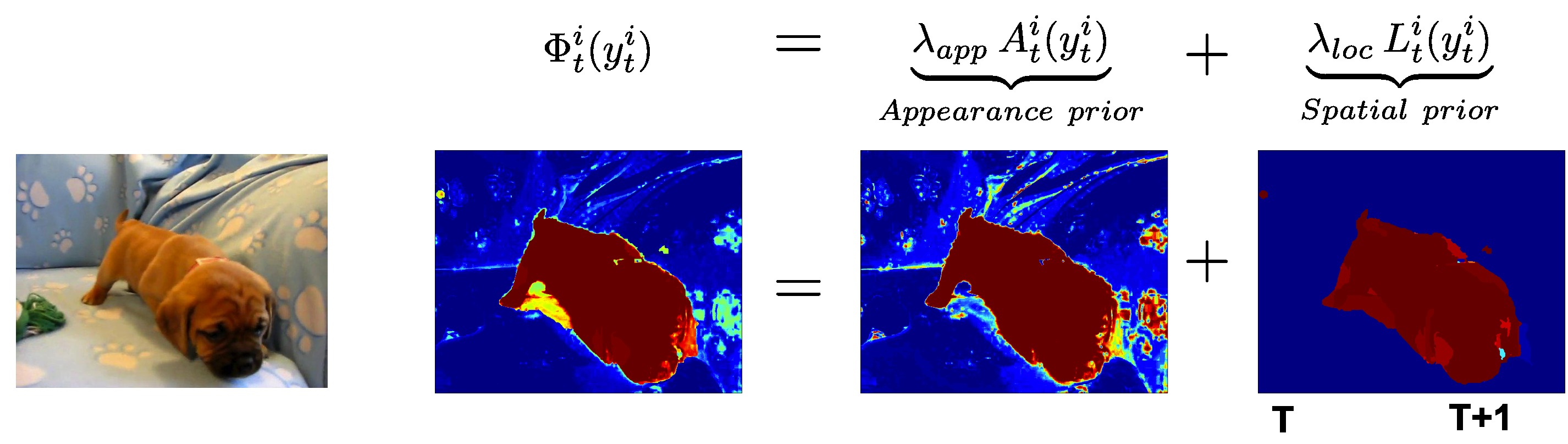
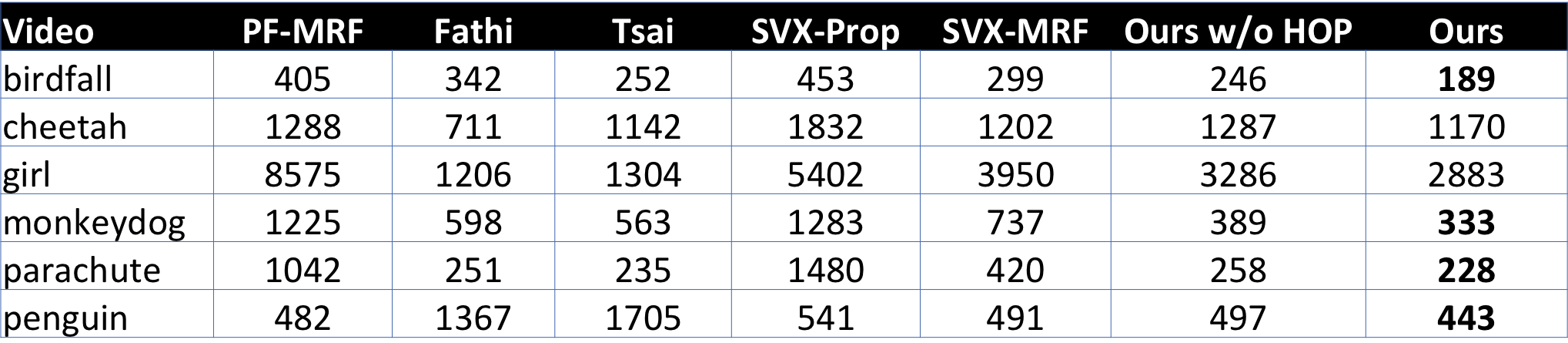
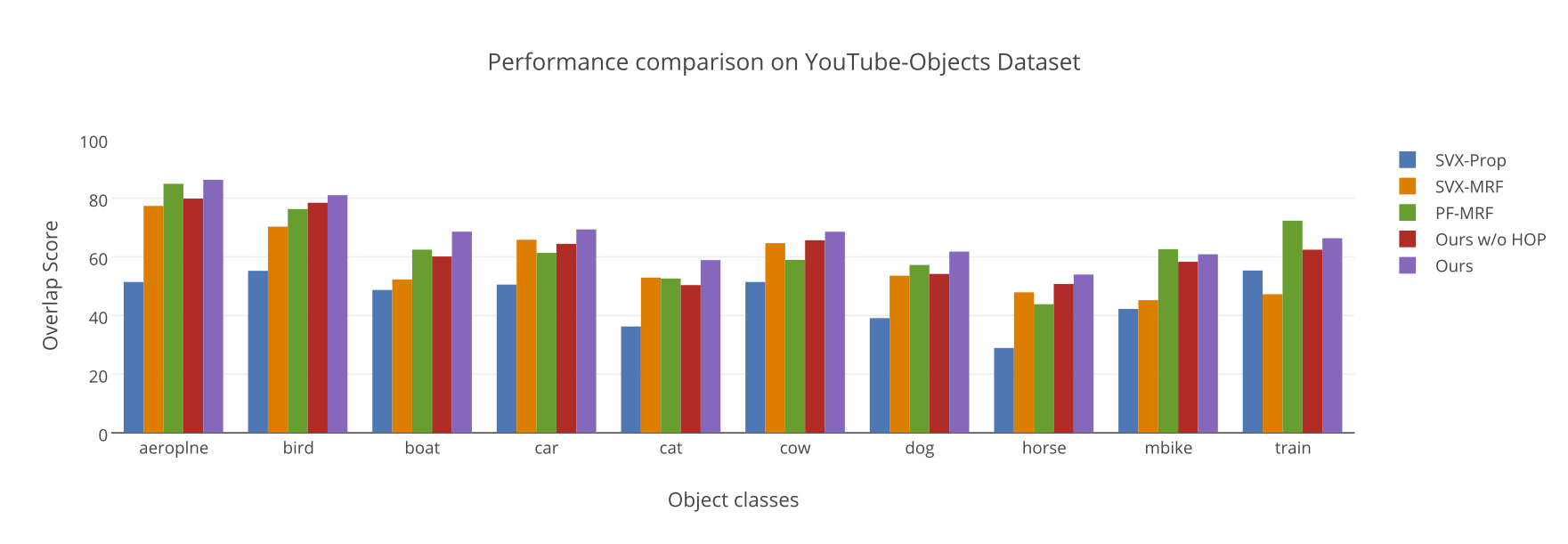
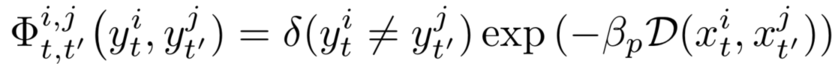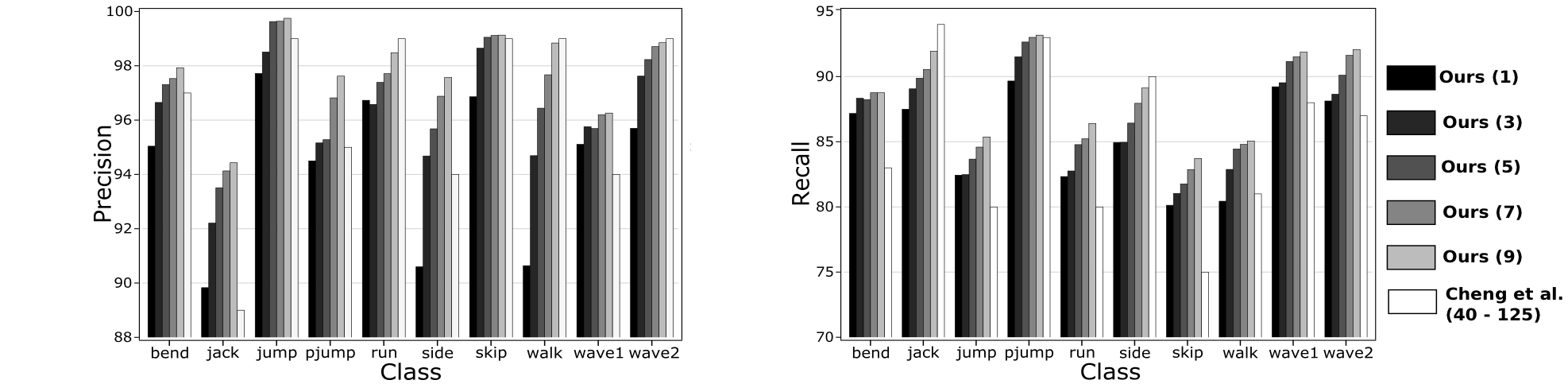Problem
Automatic propagation of foreground segmentation in videos from a single/multiple labeled frame (s).

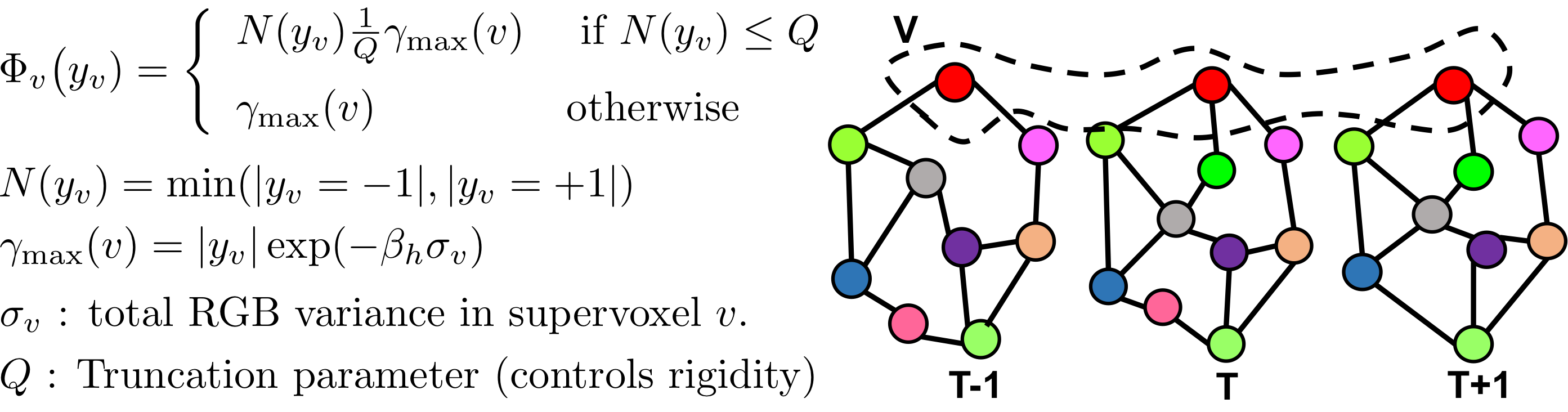
Existing methods can only enforce local consistency in space and time
(Only use pairwise connections)
Robust foreground propagation requires capturing long range dependencies as object evolves in shape over time.