Santhosh K. Ramakrishnan1,2,* Dinesh Jayaraman3,* Kristen Grauman1,2
1The University of Texas at Austin 2Facebook AI Research 3University of California, Berkeley
Science Robotics 2019
Standard computer vision systems assume access to intelligently captured inputs (e.g., photos from a human photographer), yet autonomously capturing good observations is a major challenge in itself. We address the problem of learning to look around: How can an agent learn to acquire informative visual observations? We propose a reinforcement learning solution, where the agent is rewarded for reducing its uncertainty about the unobserved portions of its environment. Specifically, the agent is trained to select a short sequence of glimpses, after which it must infer the appearance of its full environment. To address the challenge of sparse rewards, we further introduce sidekick policy learning, which exploits the asymmetry in observability between training and test time. The proposed methods learned observation policies that not only performed the completion task for which they were trained but also generalized to exhibit useful “look-around” behavior for a range of active perception tasks.
[code] [data] [full text] [supp] [arXiV]
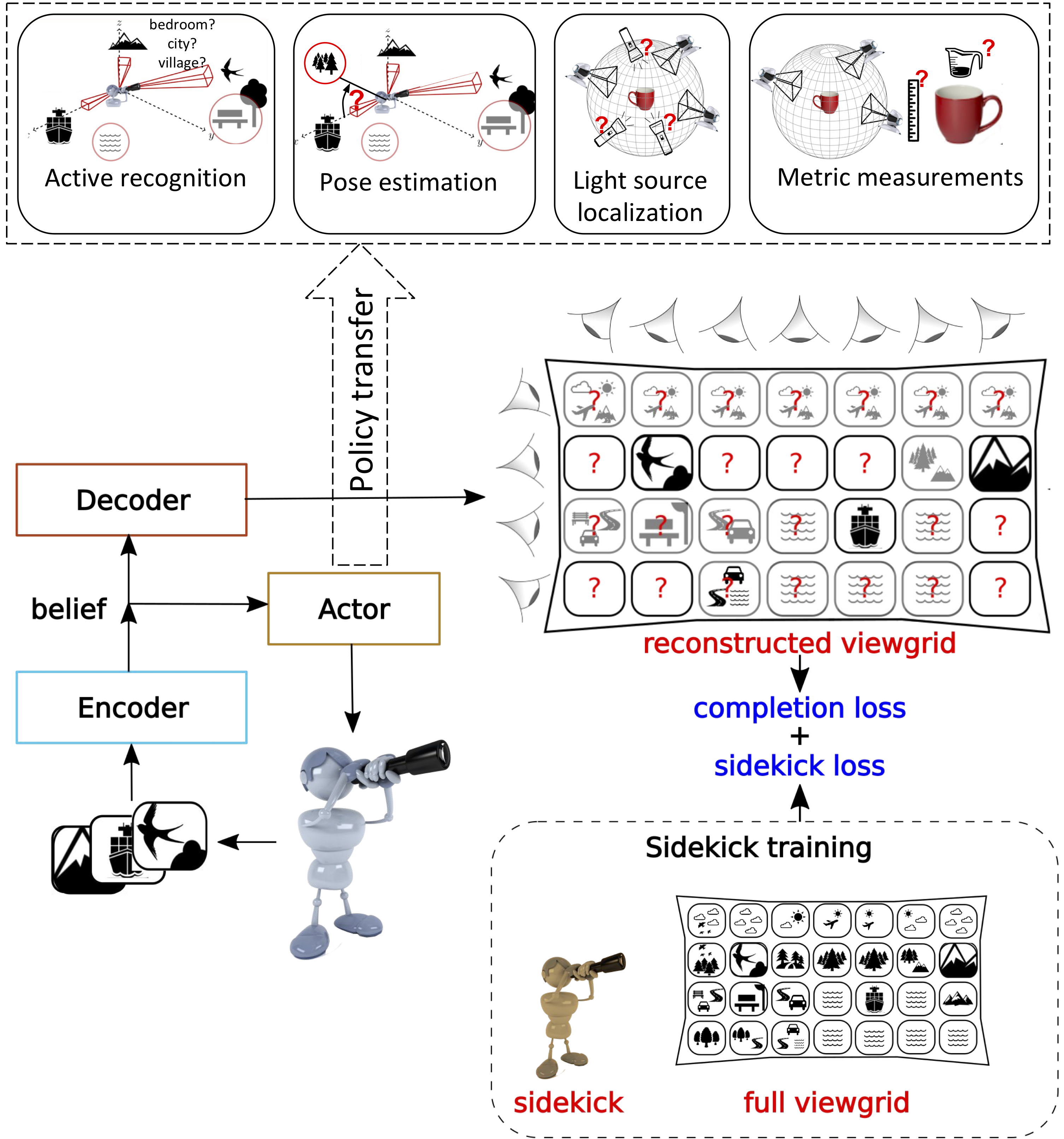
The agent starts by looking at a novel environment (left) or object (right) from some unknown viewpoint. It has a budget T of time to explore the environment. The learning objective is to minimize the error in the agent’s pixelwise reconstruction of the full—mostly unobserved— environment using only the sequence of views selected within that budget. The agent does this by learning a policy to actively sample views that allows it to reconstruct the environment.
The goal of the exploration agent is to sample informative views that reduce uncertainty about the environment and permit high quality reconstruction of the unseen environment with a limited amount of glimpses. To do this, the agent (actor) encodes individual views from the environment and aggregates them into a belief state vector. This belief is used by the decoder to get the reconstructed viewgrid. The agent’s incomplete belief about the environment leads to uncertainty over some viewpoints (red question marks). To reduce this uncertainty, the agent intelligently samples more views based on its current belief within a fixed time budget T. The agent is penalized on the basis of the reconstruction error at the end of T steps (completion loss). In addition, we provide guidance through sidekicks (sidekick loss), which exploit the full viewgrid—only at training time—to alleviate uncertainty in training due to partial observability. The learned exploratory policy is then transferred to other tasks (top row shows four tasks we consider).
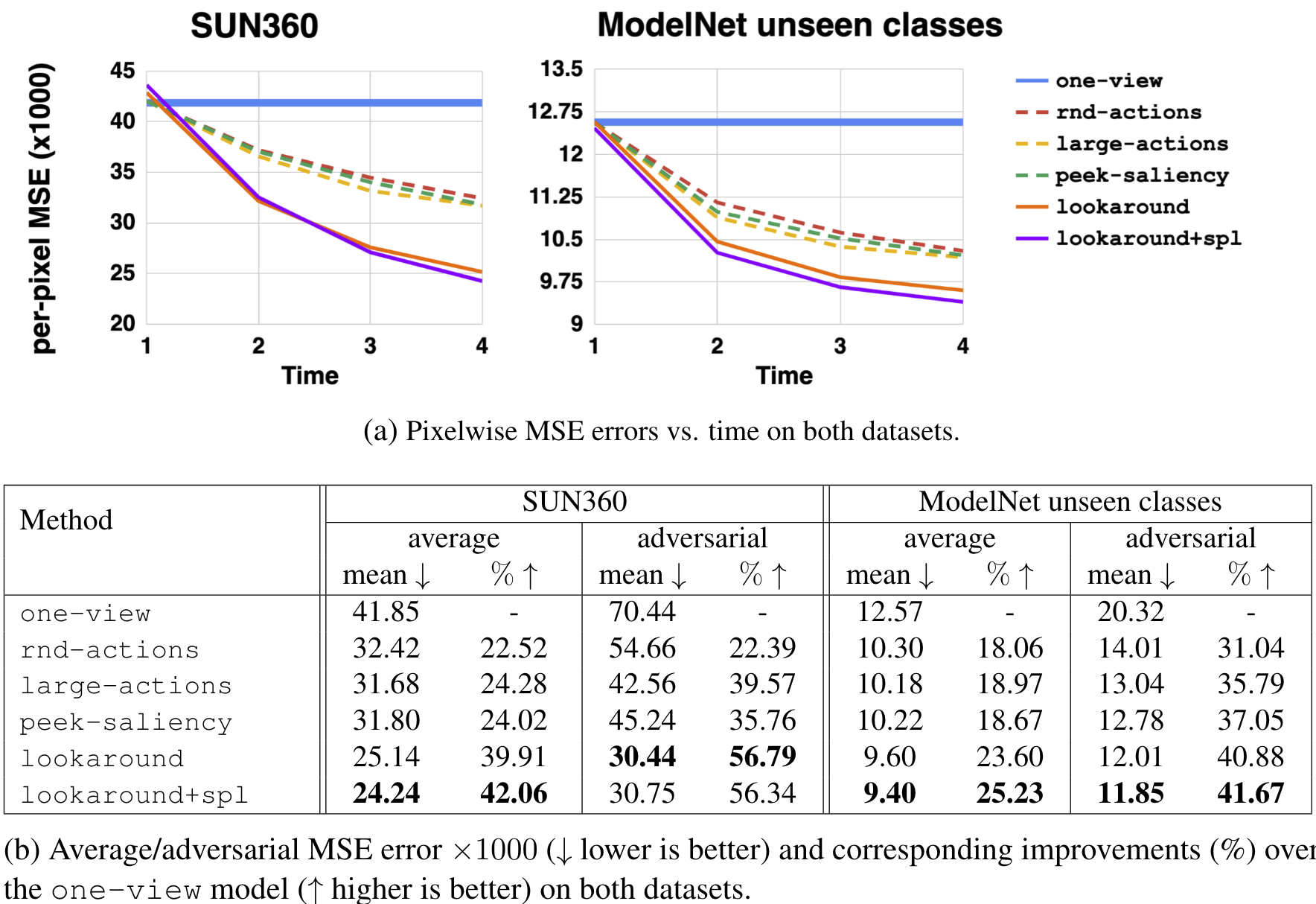
(A) Pixelwise MSE errors versus time on both datasets as more glimpses are acquired. (B) Average/adversarial MSE error ×1000 (↓ lower is better) and corresponding improvements (%) over the one-view model (↑ higher is better) on both datasets after all T glimpses are acquired.
Our hypothesis is that the glimpses acquired to maximize completion accuracy will transfer well to solve perception tasks efficiently, because they were chosen to reveal maximal information about the full environment or object. To demonstrate transfer, we first trained a rnd-actions model for each of the target tasks (“model A”) and a lookaround model for the active observation completion task (“model B”). The policy from model B was then used to select actions for the target task using model A’s task head. In this way, the agent learned to solve the task given arbitrary observations, then inherited our intelligent look-around policy to (potentially) solve the task more quickly—with fewer glimpses. The transfer is considered a success if the look-around agent can solve the task with similar efficiency as a supervised task-specific policy, despite being unsupervised and task agnostic. We tested policy transferability for the following four tasks: active categorization, surface area estimation, light source localization and pose estimation.

lookaround and lookaround+spl are transferred to the rnd-actions task-heads from each task. The same unsupervised look-around policy successfully accelerates a variety of tasks—even competing well with the fully supervised task-specific policy (supervised). Note that RMSE here denotes the root mean squared error in the surface area prediction.
We show the set of glimpses sampled by the agent in different environments, and provide a random walkthrough of the reconstructed environments. Note that the original glimpses are actively chosen by the look-around policy, while the egocentric views shown in the walkthrough are from a manually specified path.
@article {ramakrishnan2019exploration,
author = {Ramakrishnan, Santhosh K. and Jayaraman, Dinesh and Grauman, Kristen},
title = {Emergence of exploratory look-around behaviors through active observation completion},
volume = {4},
number = {30},
elocation-id = {eaaw6326},
year = {2019},
doi = {10.1126/scirobotics.aaw6326},
publisher = {Science Robotics},
URL = {https://robotics.sciencemag.org/content/4/30/eaaw6326},
eprint = {https://robotics.sciencemag.org/content/4/30/eaaw6326.full.pdf},
journal = {Science Robotics}
}