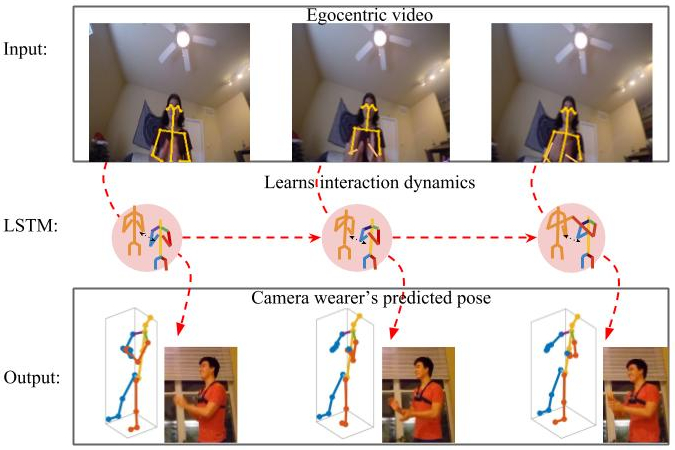
The body pose of a person wearing a camera is of great interest for applications in augmented reality, healthcare, and robotics, yet much of the person's body is out of view for a typical wearable camera. We propose a learning-based approach to estimate the camera wearer's 3D body pose from egocentric video sequences. Our key insight is to leverage interactions with another person---whose body pose we can directly observe---as a signal inherently linked to the body pose of the first-person subject.
We show that since interactions between individuals often induce a well-ordered series of back-and-forth responses, it is possible to learn a temporal model of the interlinked poses even though one party is largely out of view.
We demonstrate our idea on a variety of domains with dyadic interaction and show the substantial impact on egocentric body pose estimation, which improves the state of the art.
*On leave from The University of Texas at Austin.
Overview
Egocentric pose prediction poses as a unique challenge since the subject, the camera wearer, is largely out of the camera's field of view. Our idea is to facilitate the recovery of 3D body pose for the camera wearer by paying attention to the interactions between the first and second person as observed in a first-person video stream. To that end, we introduce "You2Me": an approach to ego-pose estimation that explicitly captures the interplay between the first and second person body poses during dyadic interactions.
Our Approach
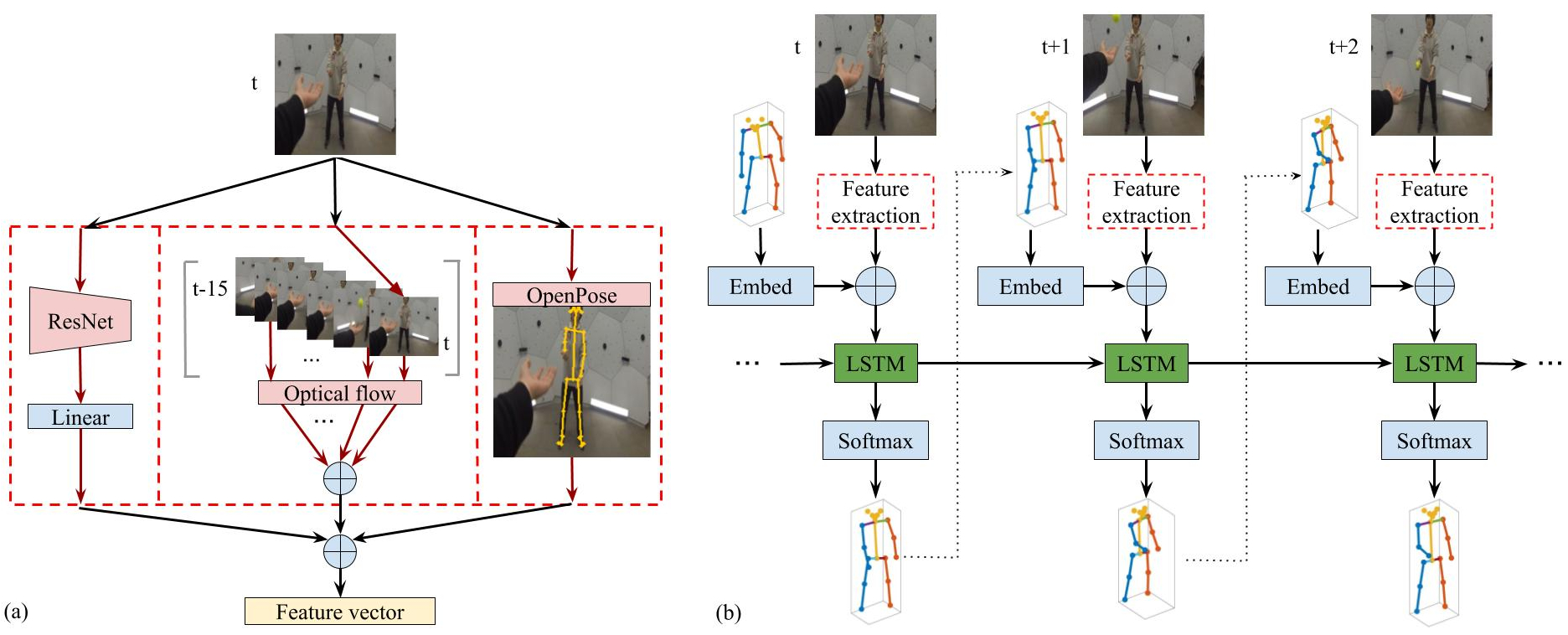
We present a recurrent neural network model that utilizes first- and second-person features---both extracted from monocular egocentric video---to predict the 3D joints of the camera wearer. More specifically, we extract three main features from each ego-view frame: dynamic first-person global motion features, static first-person scene features, and second-person body pose interaction features. See below for an overview of our network:
Qualitative Video
We show examples of success cases across the four different action domains: conversation, sports, hand games, and ball tossing. In both the Kinect and Panoptic Studio captures, our method is able to perform well. Most notably, our approach is able to determine when the camera wearer is going to squat or sit, when they are raising their hand to receive or catch an item, and when they are gesturing as part of a conversation.
For the failure cases, we demonstrate that our approach can fail when the view of the second person is obscured for a long duration. This is especially true for the sports category. We also show an instance towards the very beginning of a test sequence when the LSTM does not have any priors, to demonstrate that the beginning of test sequences is generally more error-prone.