Sudheendra Vijayanarasimhan and Kristen Grauman
Department of Computer Sciences,
University of Texas at Austin
Traditional active learning reduces supervision by obtaining a single type of label (single-level active learning) for the most informative or uncertain examples first.
However, in visual category recognition, annotations can occur at multiple levels requiring different amounts of manual effort.
Different questions can be posed on an image given how uncertain the classifier is about an example. To best utilize manual effort we need to let the classifier choose not only what example but also what type of information needs to be supplied.
How do we actively learn in the presence of multi-level annotations?
We propose an active learning framework that chooses from multiple types of annotations.
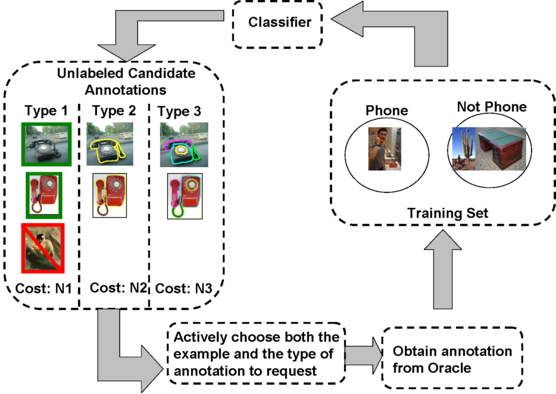
To best use manual resources we choose from a combination of weak and strong annotations by balancing the varying cost and information content of different annotations.
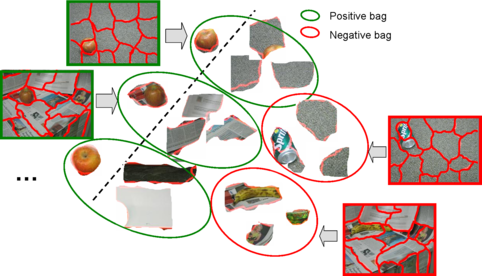
We deal with multi-level annotations by posing the problem in the Multiple Instance Learning setting. Here, an instance is an image segment, a positive bag is an image belonging to the class of interest and a negative bag is any image not belonging to the class of interest.
|
Given this scenario we consider the following three queries that an active learner can pose:
|
|
|
Labeling an unlabeled instance or an unlabeled bag does not require as much manual effort as providing a complete segmentation of the image which provides more information to the classifier. Our multi-level active learning criterion therefore considers both the information content and the manual effort expended on an annotation and chooses the candidate annotation that provides the best trade-off.
We measure the information content of a candidate annotation by computing the reduction in the risk of the dataset once we add the example along with the annotation to the training set and retrain the classifier.
We obtain the cost (manual effort) of an annotation empirically through user experiments where we measure the average time taken by a number of users to provide a particular type of annotation and set the cost proportionally.
At each active iteration, we compute the ``net worth'' of each unlabeled example and its candidate annotations and choose the annotation that provides the best tradeoff and add it to the training set.
We evaluate the framework in two different scenarios.
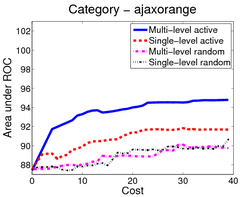
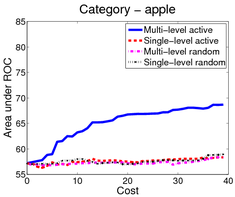
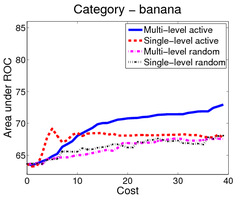
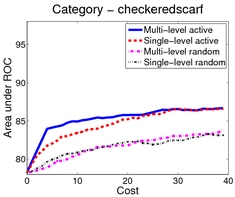
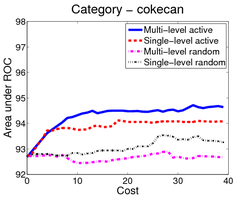
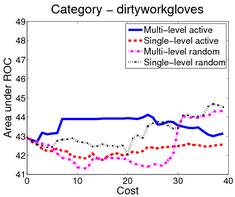
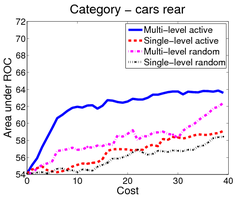
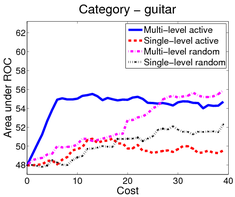
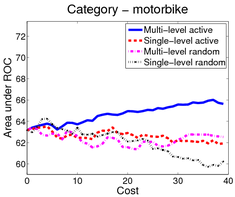
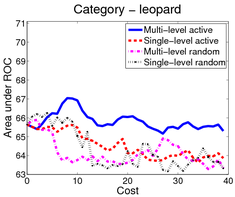
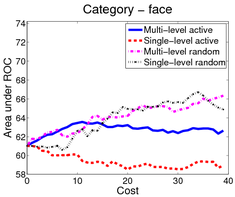
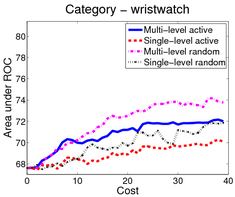
In the first scenario (shown above), an image is a bag of segments. We use the publicly available SIVAL dataset which contains 25 different classes, 1500 images and 30 segments per image represented by texture and color features.
|
A good learning curve is steep early on, as we gain more accuracy in the predictions with very little manual effort. Our multi-level active selection criterion (in blue) has the steepest curve initially and therefore performs the best for most classes compared to both traditional single-level active selection and passive learning.
In the second scenario, an image is an instance and positive bags are sets of images containing at least one example of the class of interest downloaded from web searches while negative bags are collected from returns of unrelated searches. Our framework also applies to non-vision scenarios containing multi-level data such as document classification (bags: documents, instances: passages).
We use the Google dataset ([Fergus et al., 2005]) to evaluate our approach in this scenario.
|
Thus, by optimally choosing from multiple types of annotations which require different amounts of manual effort we are able to reduce the total cost needed to learn accurate models.
In this framework, we accounted for the varying cost between the different types of annotations, though for image examples under the same type of annotation, we assumed uniform cost. More recently, we have shown that we can learn to predict the cost of an annotation on an example-specific basis.(pdf)
Multi-Level Active Prediction of Useful Image Annotations for Recognition,
S. Vijayanarasimhan and K. Grauman, in NIPS 2008
[paper, supplementary][slides]